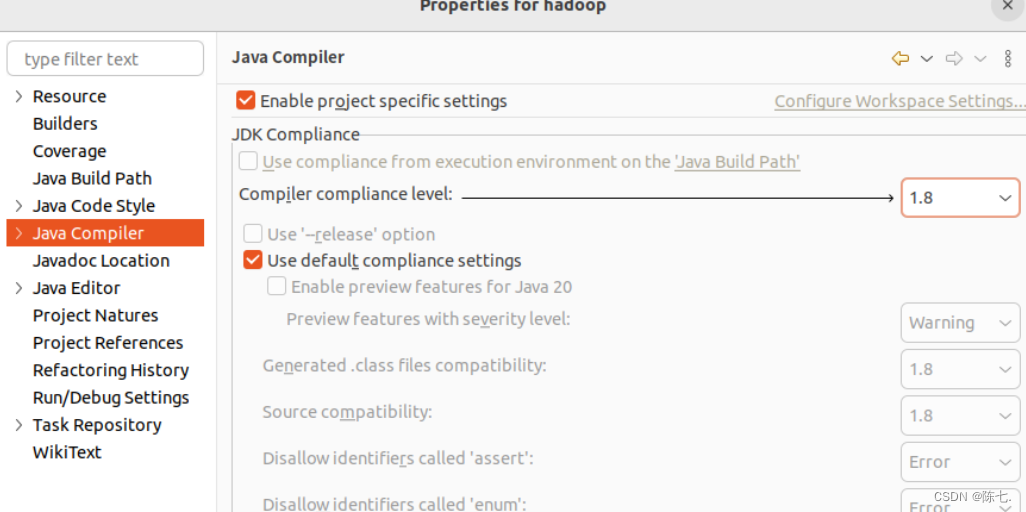
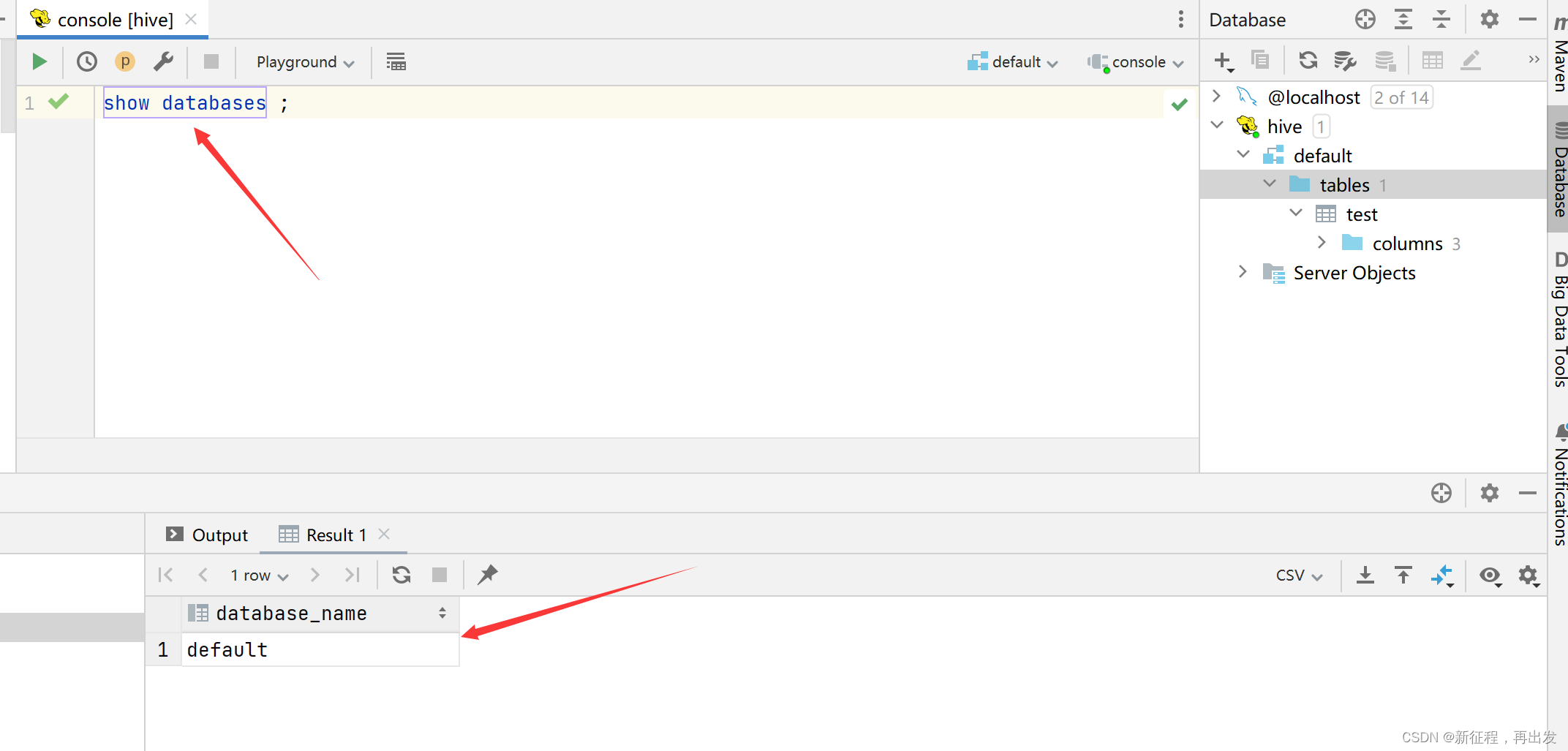
开发语言
qt
git
抽象代数
仿真
子图
cloud alibaba
WinLicense
亚马逊证书
二次元
反射型XSS
js
xshell
图像超分辨率
产品设计误区
基础知识
buildroot
433MHz自发电无线控制器
51单片机
NOIP
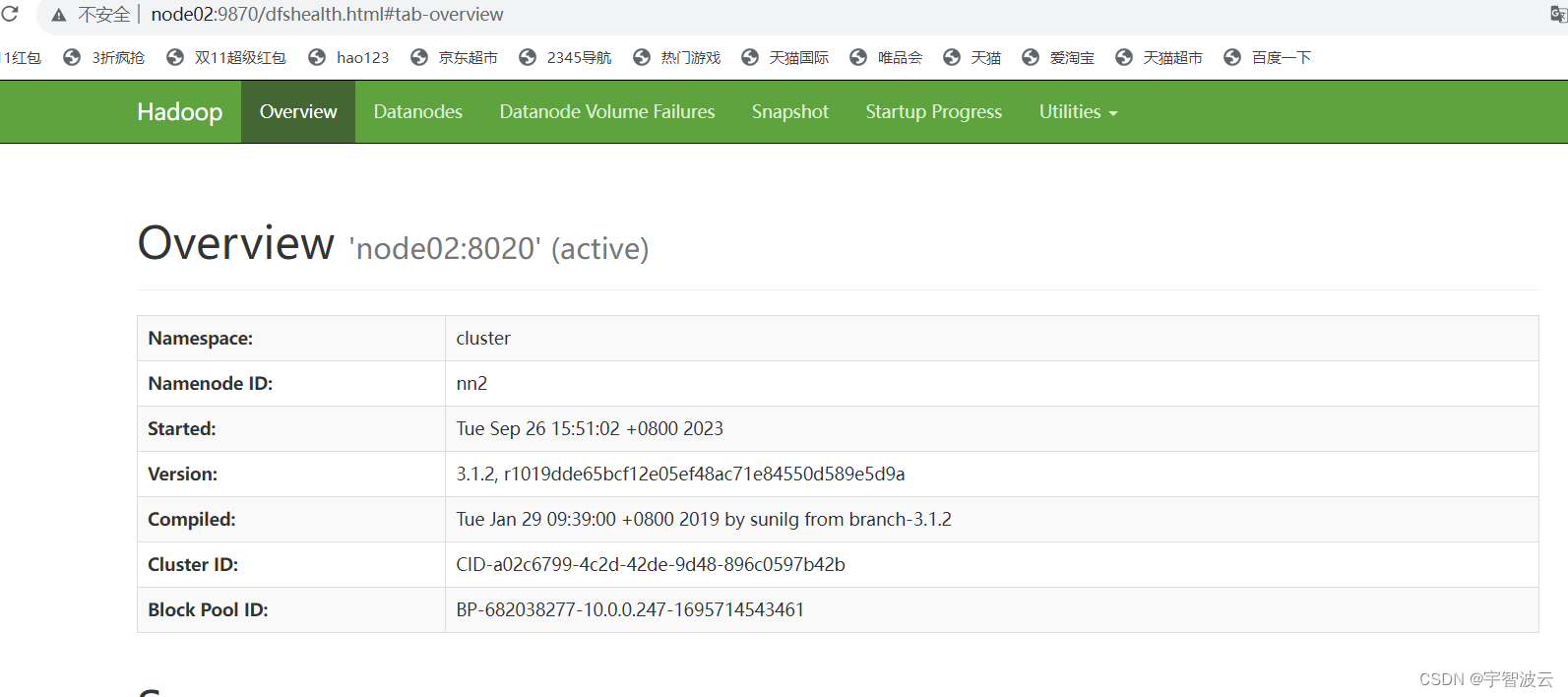
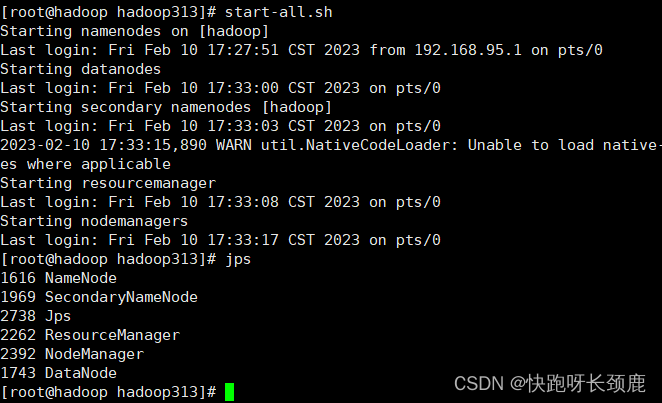
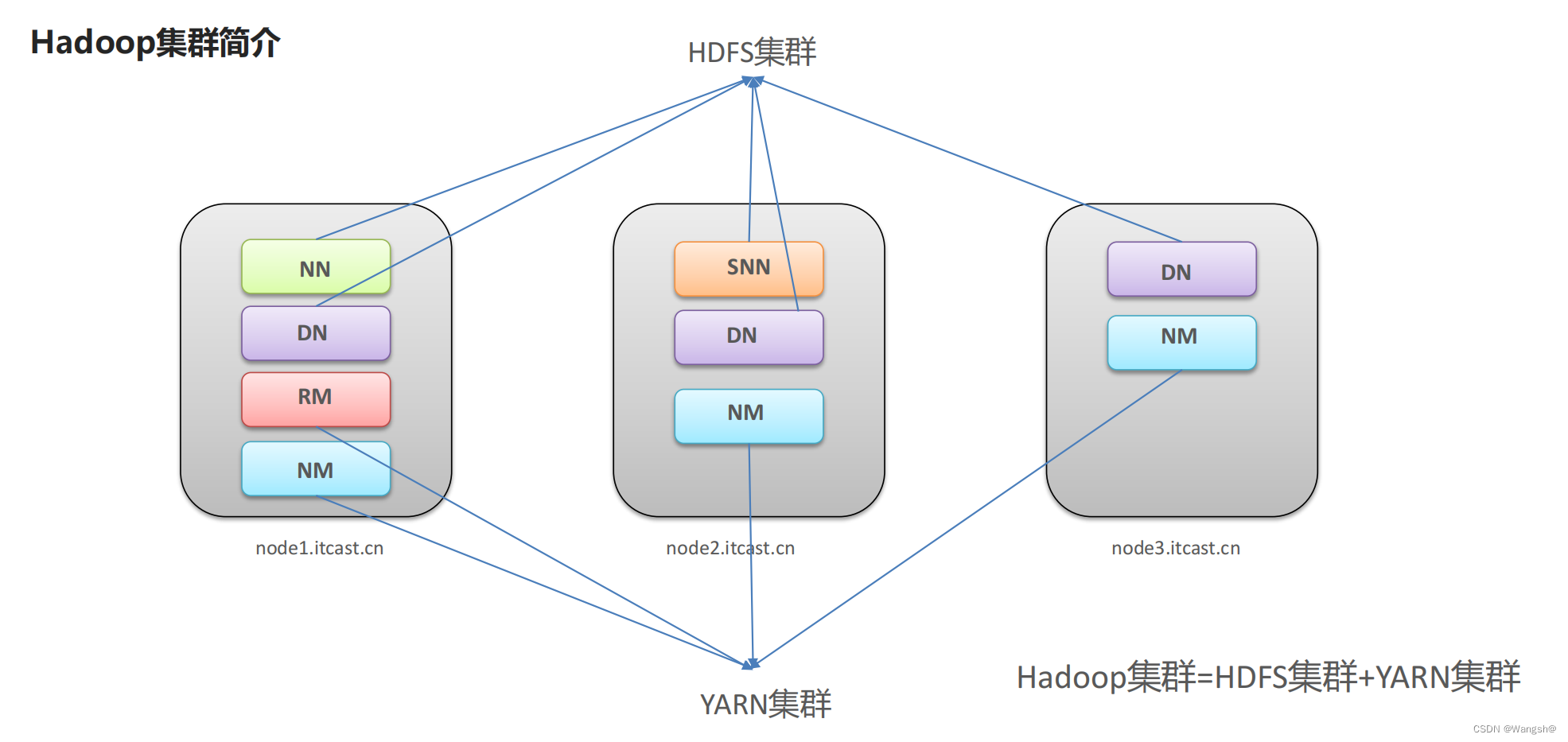
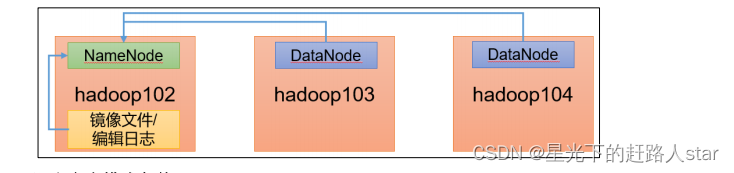
hdfs
2024/4/11 16:17:57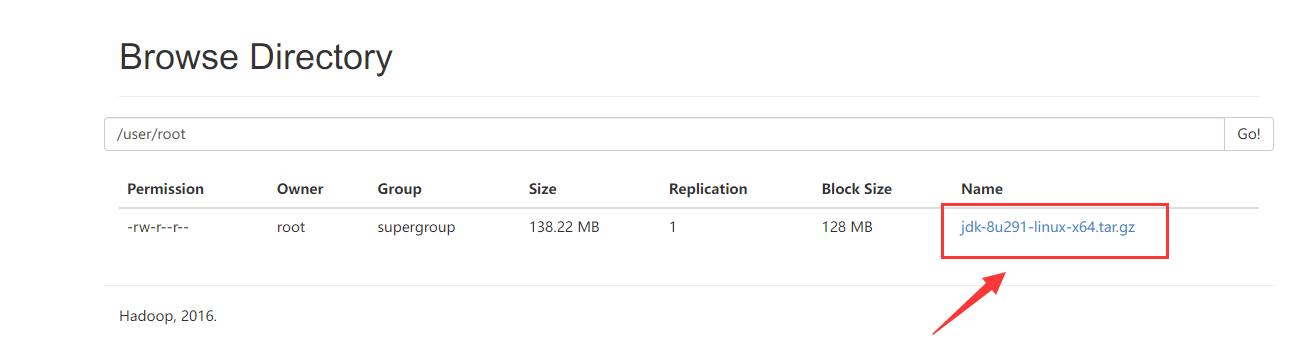
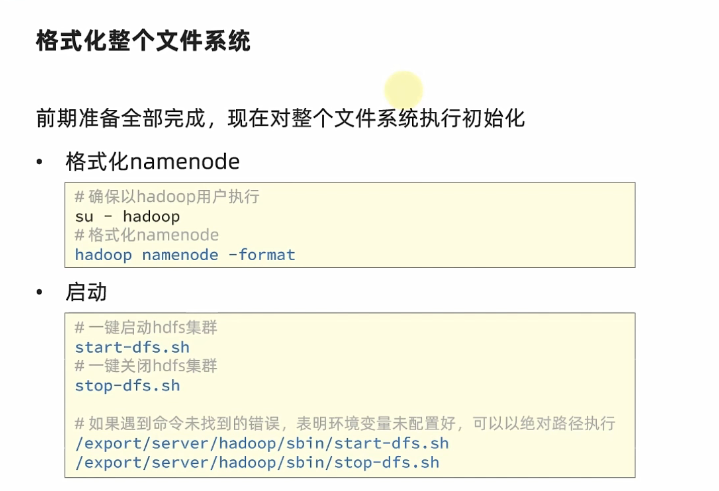
HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建
作者:Grey
原文地址:
博客园:HDFS 伪分布式环境搭建
CSDN:HDFS 伪分布式环境搭建
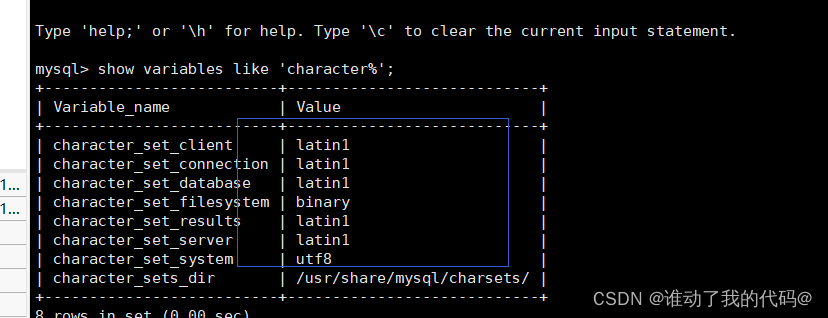
相关软件版本 Hadoop 2.6.5 CentOS 7 Oracle JDK 1.8
安装步骤
在CentOS 下安装 Oracle JDK 1.8
下载地址
将下…
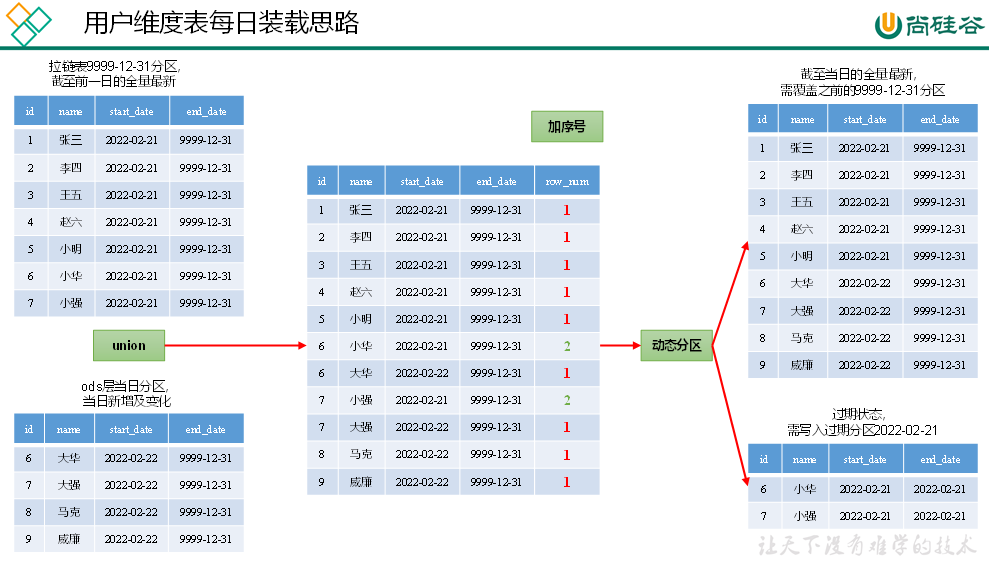
尚硅谷大数据项目《在线教育之离线数仓》笔记003
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili 目录
第8章 数仓开发之DIM层
P039
P040
P041
P042
P043
P044
P045
P046
P047
P048 第8章 数仓开发之DIM层
P039 第8章 数仓开发之DIM层 DIM层设计要点: (1&a…
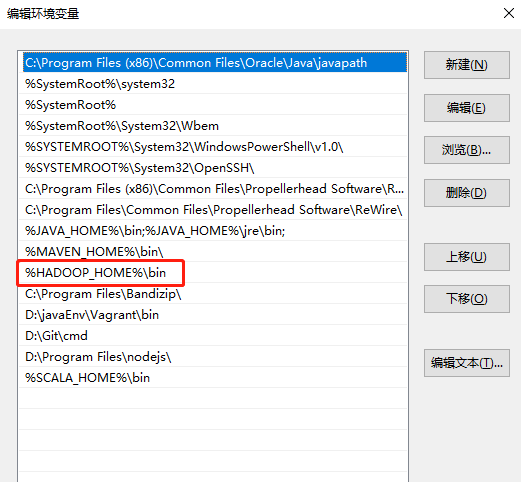
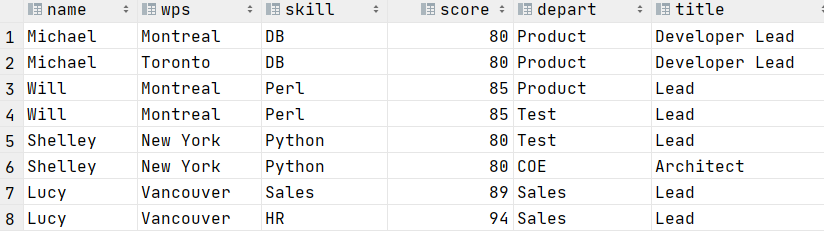
大数据框架之Hadoop:HDFS(三)HDFS客户端操作(开发重点)
3.1 HDFS客户端环境准备
1.根据自己电脑的操作系统拷贝对应的编译后的hadoop jar包到非中文路径(例如:D:\javaEnv\hadoop-2.77),如下图所示。 2.配置HADOOP_HOME环境变量,如下图所示。 3&#…

如何使用Java API读写Hbase
[b][colorolive][sizelarge]Hbase是够建在HDFS之上的半结构化的分布式存储系统,具有HDFS的所有优点,同时也有自己的亮点,支持更快速的随机读写以及更灵活的Scan操作,而在HDFS上这一点我们是远远做不到的,因为HDFS仅支持…

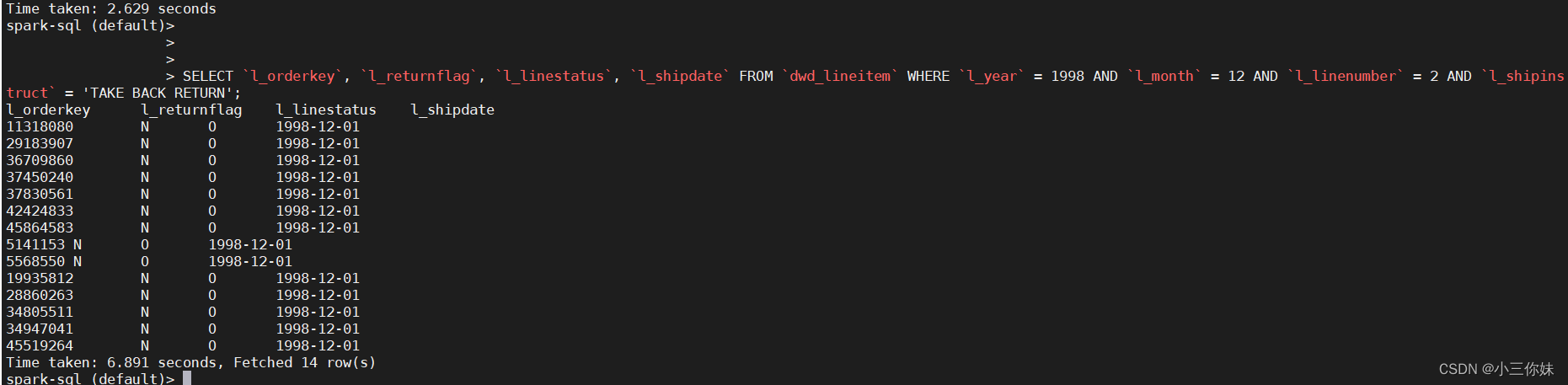
hdfs dfs -du -h 或者 hadoop fs -du -h 输出三列数据的含义
第一列表示该目录下总文件大小
第二列表示该目录下所有文件在集群上的总存储大小 与你的副本数相关,我的副本数是3 , 所以第二列的是第一列的三倍 (第二列内容文件大小*副本数)
第三列表示你查询的目录
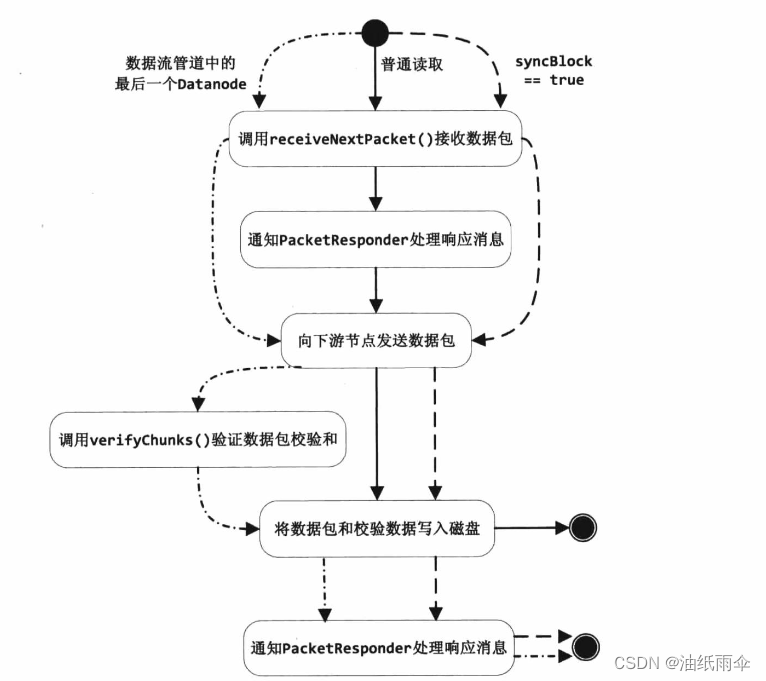
【HDFS】BlockSender发送数据源码详解
本文包含如下内容: 1、BlockSend在发送数据之前读数据文件和meta文件生成的Packet的结构。 2、BlockSender的核心方法:sendBlock和sendPacket。
前言: BlockSender#sendBlock有几处调用场景,分别是: 1、copyBlock,用于balancing; 2、DataTransfer#run,用于pipeline恢复…
![[需要继续修改]MongoDB的简介](https://img-blog.csdnimg.cn/20210623105759561.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hhaWx1bnc=,size_16,color_FFFFFF,t_70)
[需要继续修改]MongoDB的简介
MongoDB是一个开源的,高性能,无模式(没有明显的列)的文档型数据库。它支持的数据结构非常松散,是一种类似于Json的格式叫做bson(二进制json)。 MongoDB的使用场景:传统数据库MySQL无…
HDFS 高可用分布式环境搭建
HDFS 高可用分布式环境搭建
作者:Grey
原文地址:
博客园:HDFS 高可用分布式环境搭建
CSDN:HDFS 高可用分布式环境搭建
首先,一定要先完成分布式环境搭建 并验证成功
然后在 node01 上执行stop-dfs.sh
重新规划每…
Linux文件目录梗概介绍
Linux文件目录梗概介绍
/bin 是Binary的缩写, 这个目录存放着最经常使用的命令
/sbin s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。
/home 存放普通用户的主目录,在Linux中每个用户都有一个自己的目录,一般该目录名…
win10 配置Hadoop 非常详细!
成功启动Hadoop~~
问题:
1.环境变量配置时一定看好是英文输入!注意全角和半角输入区别!!! 2.先替换文件再修改配置 3.hadoop文件路径全英文,不能有中文和空格 4.namenode和datanode路径修改时,注意"/“和”\"的区别,按博主内容格式来! 转载自这里,配置过程请点击查…
Hdoop学习笔记(HDP)-Part.12 安装HDFS
十二、安装HDFS
1.安装libtirpc-devel
HDFS依赖libtirpc-devel,因此需要先安装libtirpc-devel。 创建yml文件,/root/ansible/libtirpc.yml
---
- hosts: allvars:var_package:- libtirpc-devel-0.2.4-0.16.el7.x86_64.rpmtasks:- name: copy install …

Spark-HDFS 删除空文件 合并小文件
一.引言
hive 执行任务后目录下生成过多小文件,过多的小文件会占用 namenode 的内存,对于 HDFS 非常不友好,所以可以通过删除空文件或者合并小文件的方法进行优化。 二.删除空文件
可以看到有很多空的gz,blockSize20。如果是空文…

案例-Shell定时采集数据到HDFS
1. 准备工作
创建日志文件存放的目录 /export/data/logs/log,执行命令:mkdir -p /export/data/logs/log 创建待上传文件存放的目录/export/data/logs/toupload,执行命令:mkdir -p /export/data/logs/toupload 查看创建的目录树结…

大数据——HDFS(分布式文件系统)
一,分布式系统概述
Hadoop的两大核心组件 HDFS(Hadoop Distributed Filesystem):是一个易于扩展的分布式文件系统,运行在成百上千台低成本的机器上。HDFS具有高度容错能力,旨在部署在低成本机器上。HDFS主…

十一、了解分布式计算
1、什么是(数据)计算? 2、分布式(数据)计算
(1)概念 顾名思义,分布式计算,即以分布式的形式完成数据的统计,得到需要的结果。 分布式数据计算,顾名思义,就是…
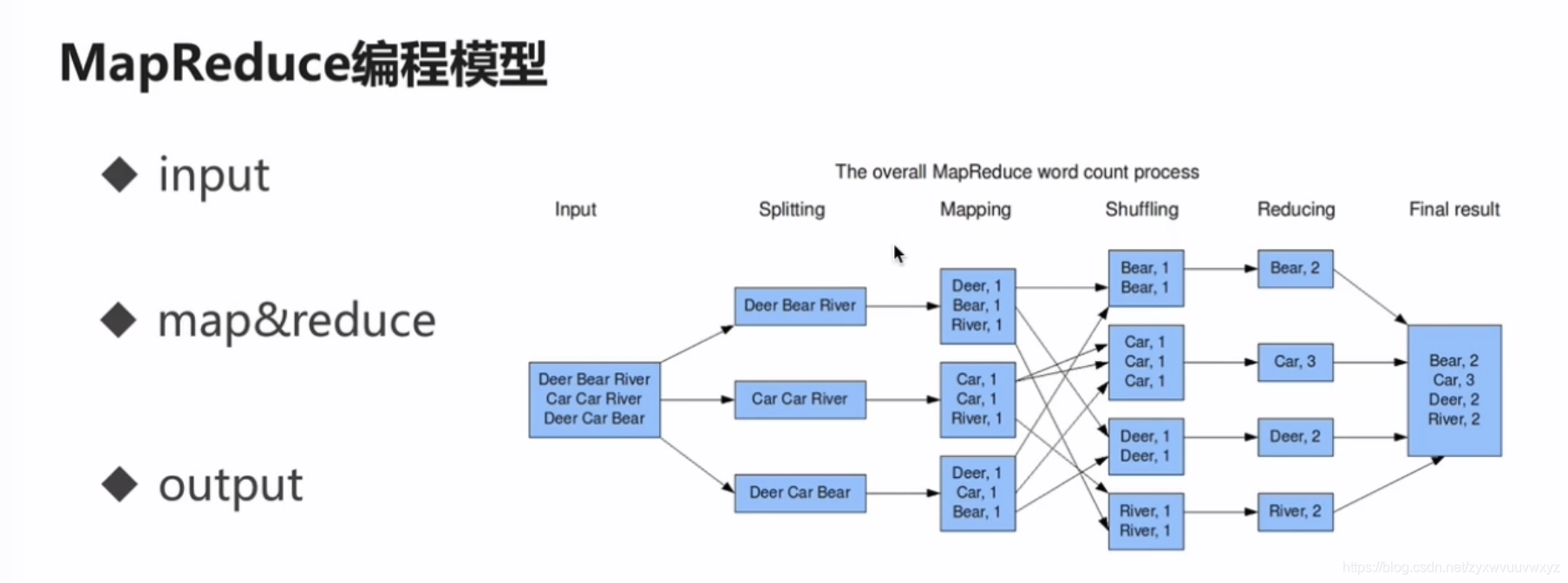
【Spark SQL】1、初探大数据及Hadoop的学习
初探大数据
centos 6.4CDH5.7.0系列http://archive.cloudera.com/cdh5/cdh/5/
生产或测试环境选择对应CDH版本时,一定要采用尾号一样的版本 OOPTB
apache-maven-3.3.9-bin.tar.gzJdk-7u51-linux-x64.tar.gzZeppelin-0.7.1-bin.tgzHive-1.1.0-cdh5.7.0.tar.gzhado…
【大数据之Hive】十、Hive之DML(Data Manipulation Language)数据操作语言
1 Load
将文件导入Hive表中。 语法:
hive>load data [local] inpath filepath [overwrite] into table tablename [partition (partcol1val1, ...)];关键字说明: (1)local:表示从本地加载数据到Hive表;…
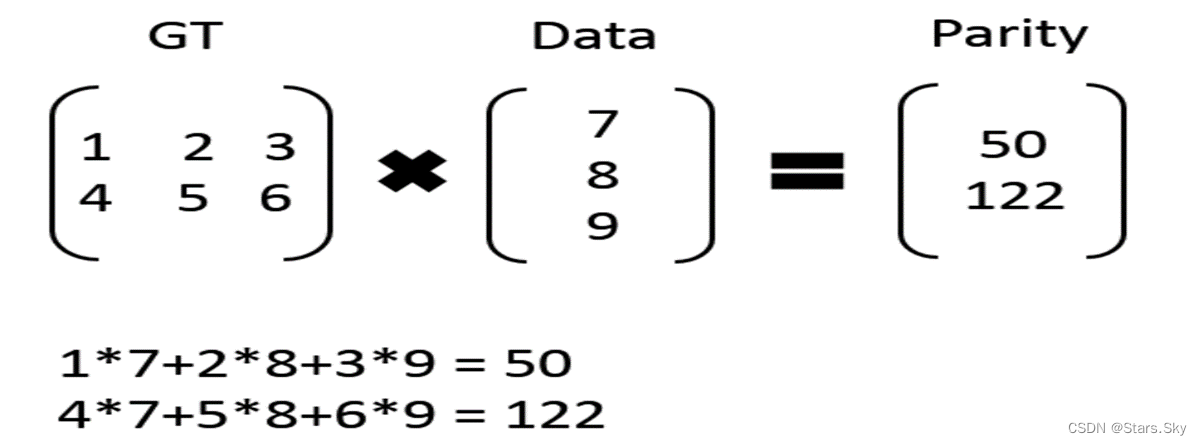
Hadoop容错恢复之纠删码
在HDFS中常见的容错恢复是副本机制,它会在部分文件丢失之后通过心跳机制发数据给NameNode然后寻找未丢失的副本,按照replication进行备份。这样的话会保证数据在绝大多数情况下不丢失。但是造成的问题就是这种机制使得Hadoop的空间利用率会很低。比如说在…
hive表小文件合并
1. 背景
公司的 hive 表中的数据是通过 flink sql 程序,从 kafka 读取,然后写入 hive 的,为了数据能够被及时可读,我设置了 flink sql 程序的 checkpoint 时间为 1 分钟,因此,在 hive 表对应的 hdfs 上&am…
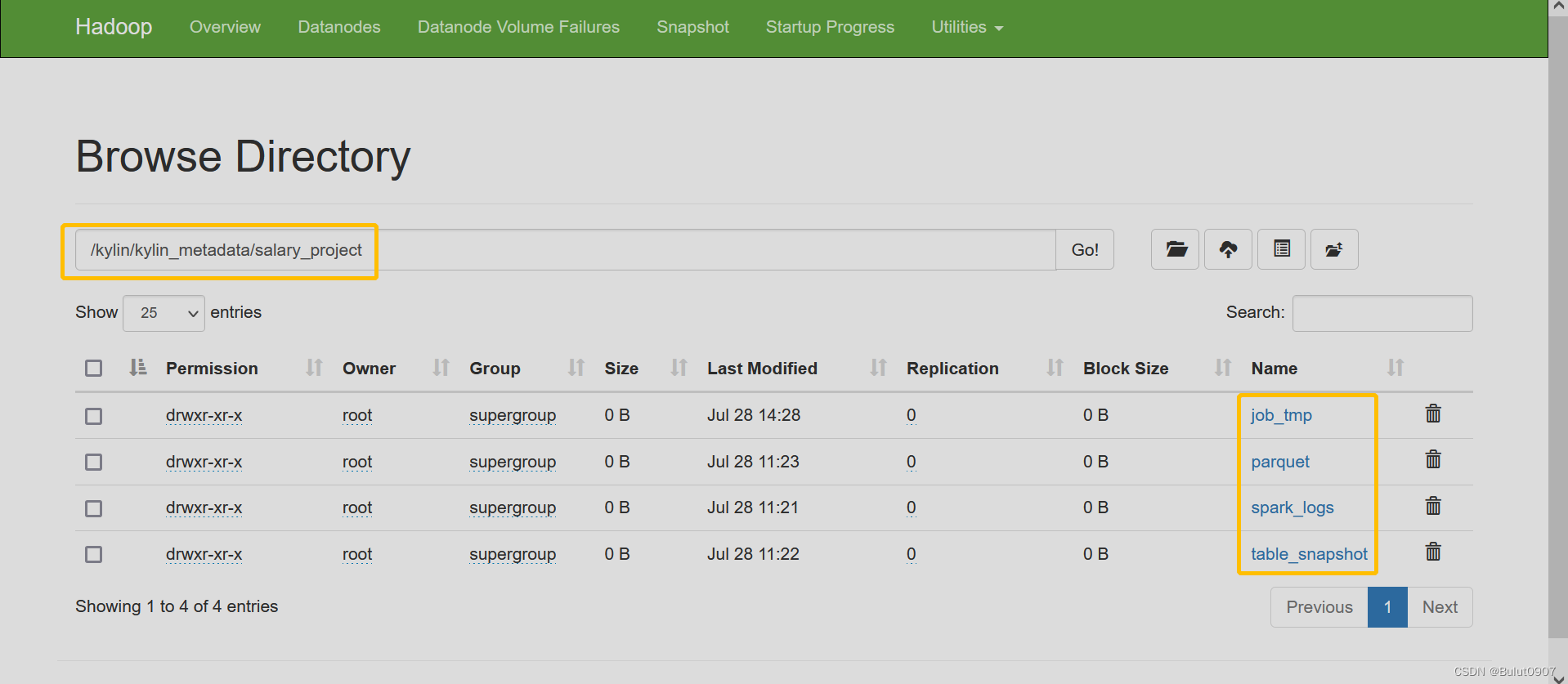
Kylin查询下压的设置、Sparder查询引擎详细介绍、HDFS文件目录含义
目录1. 查询下压设置2. Sparder查询引擎详细介绍3. HDFS文件目录含义1. 查询下压设置
如果未开启查询下压,则查询有很多限制。这是因为只能查询cube中的数据,而不能通过spark sql查询Hive中的源数据
开启查询下压,优先从cube中查询数据&…
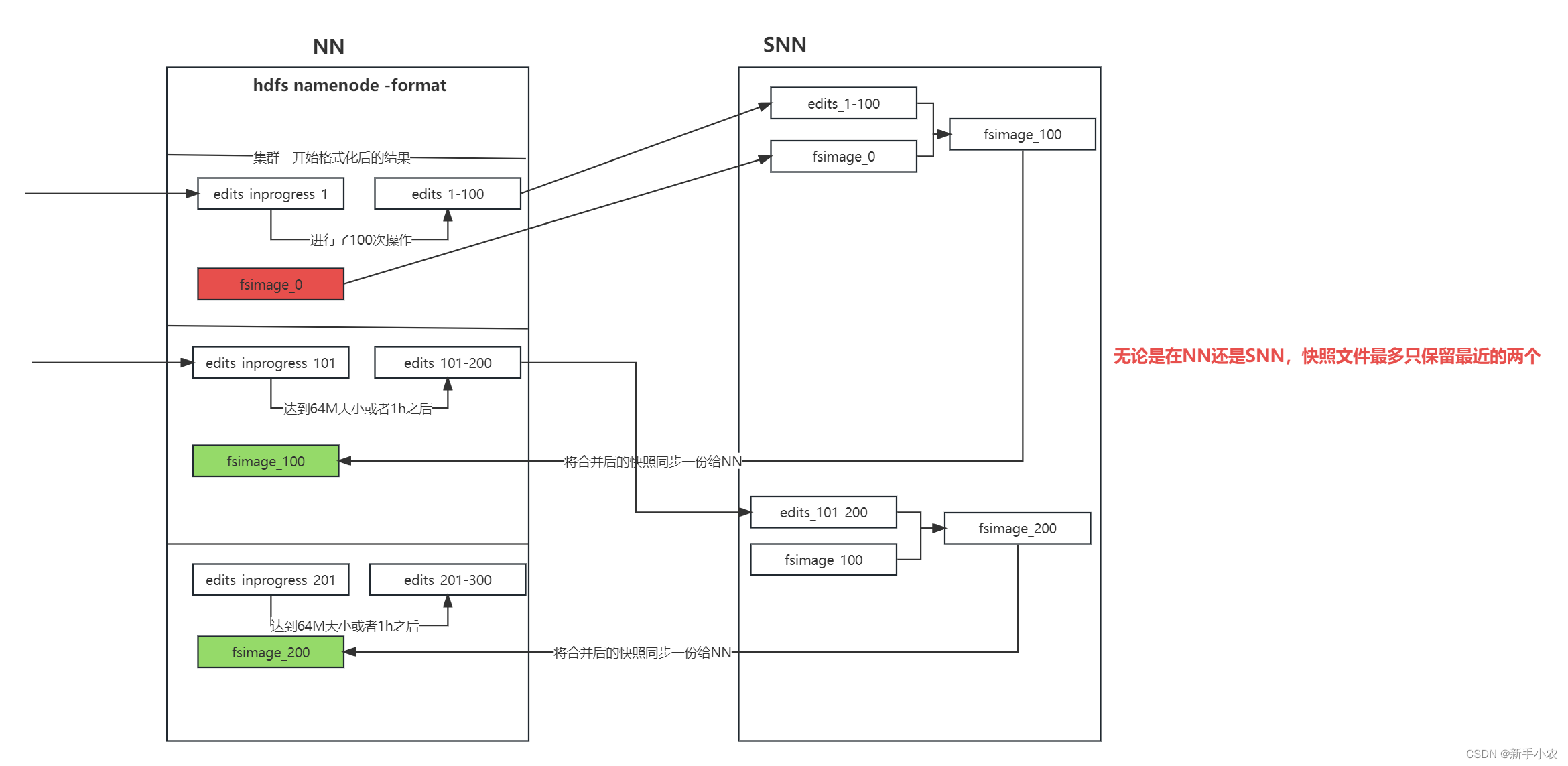
HADOOP::Fsimage和Edits解析
NameNode被格式化之后,将在/opt/module hadoop-3.1.3/data/tmp/dfs/name/curent目录 中产生如下文件 fsimage_ 0000000000000000000 fsimage_ 0000000000000000000.md5 seen_txid VERSION (1) Fsimage文件: HDFS文件系统元数据的一个永久性的检查点࿰…

基于Flink实时数仓——DWS 层的设计访客主题宽表(6)
DWS 层的定位是什么 轻度聚合,因为 DWS 层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。 DWS 层-访客主题宽表的计算 设计一张 DWS 层的表其实…
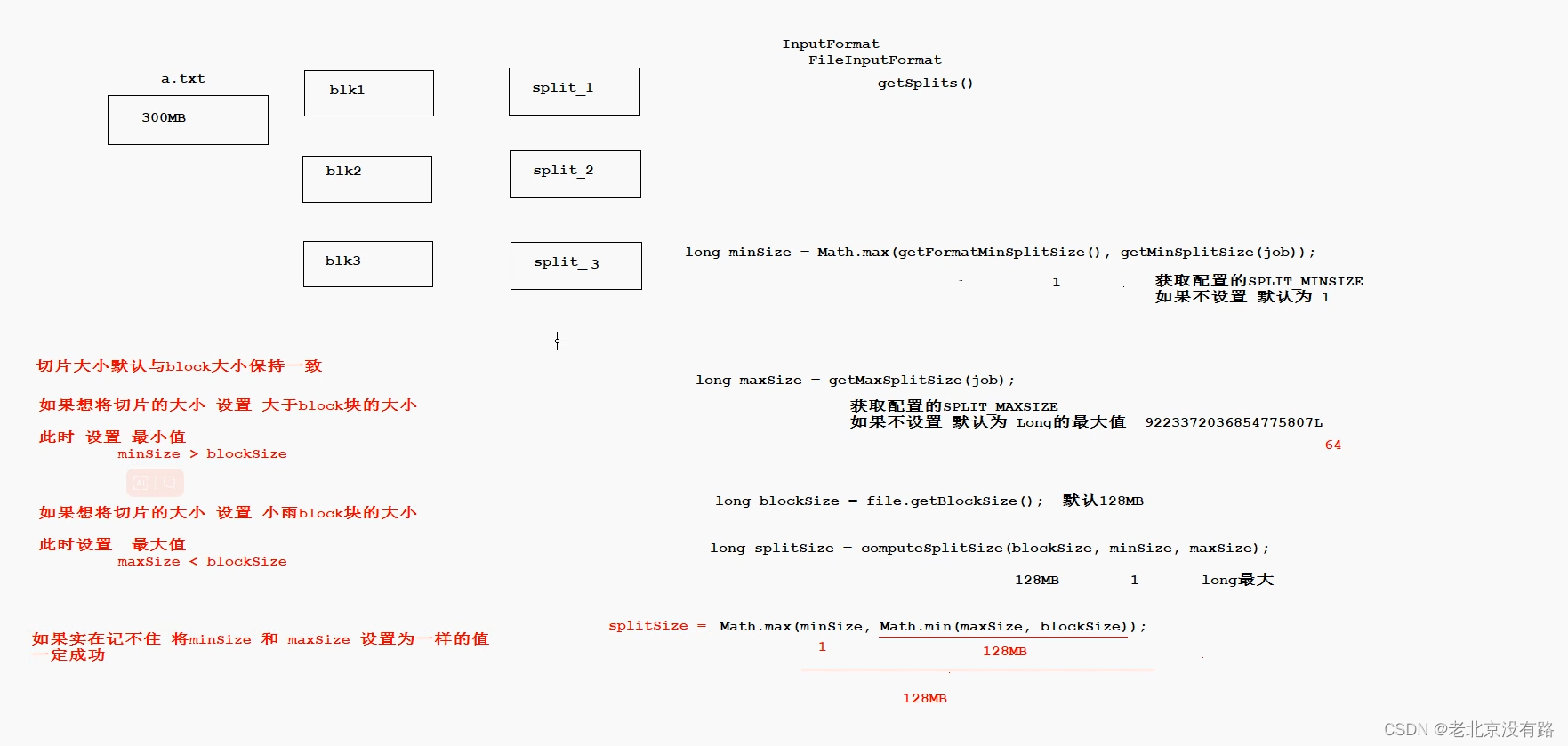
源码阅读笔记 InputFormat、FileInputFormat、CombineTextInputFormat
1. InputFormat
InputFormat是MapReduce框架提供的用来处理job输入的基类 它主要定义了三个功能: 1.验证job输入是否合法 2.对输入文件进行逻辑切片(InputSplit),然后将每个切片分发给单独的MapTask 3.提供切片读取器(Re…
修炼k8s+flink+hdfs+dlink(七:flinkcdc)
一 :flinkcdc官网链接。 https://ververica.github.io/flink-cdc-connectors/release-2.1/content/about.html 二:在flink中添加jar包。
在flink lib目录下增加你所需要的包。 https://kdocs.cn/join/gv467qi?f101 邀请你加入共享群「工作使用重要工具…
用Fluentd实现收集日志到HDFS(下)
本篇主要包含Fluentd的配置文件格式,in_tail输入插件,out_webhdfs输出插件的部分内容。
Fluentd的配置文件主要包含以下字段
source,决定数据来源match,决定输出目的地filter,在输入与输出之间,用来过滤s…
Hadoop HA集群怎么格式化namenode?
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html
1)停止Hadoop集群
2)在所有服务器上执行命令行
rm -rf /home/user/hadoop-3.2.2/tmp/*
rm -rf /home/user/hadoop-3.2.2/journal/ns1/*3)确…
大数据项目实战---电商埋点日志分析(第八部分,用户留存主题(DWS层+ADS层)
1)创建每日留存用户明细表dws_user_retention_day并加载数据。 2)创建每日留存用户数表ads_user_retention_day_count并加载数据。 3)创建每日留存用户比例表ads_user_retention_day_rate并加载数据 为了能够尽快地找到新工作,这个项目先到这…
Tez的简介以及安装配置
Tez简介
Tez是一个Hive的运行引擎,由于没有中间存盘的过程,性能优于MR。Tez可以将多个依赖作业转换成一个作业,这样只需要写一次HDFS,中间节点少,提高作业的计算性能。 Tez的安装步骤
1)下载安装包到hive所在的66服务…
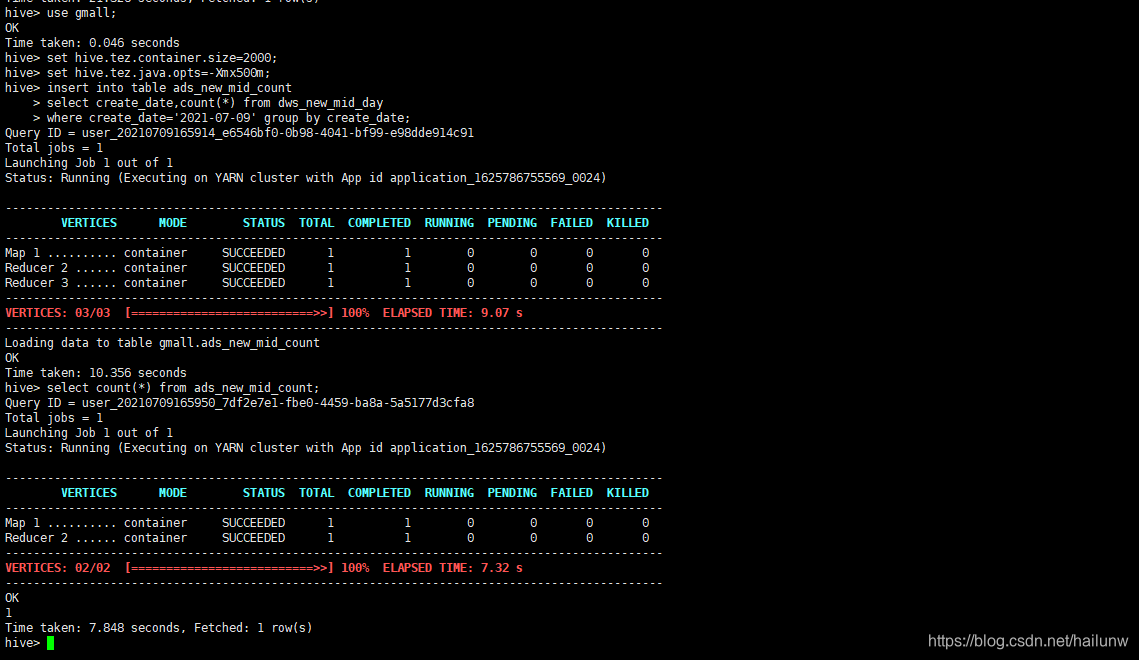
大数据项目实战---电商埋点日志分析(第七部分,每日新增设备主题(DWS层+ADS层)
1)创建设备按天明细表,dws_new_mid_day并加载数据。 2)创建每日新增设备表,ads_new_mid_count并加载数据。 下一章 https://blog.csdn.net/hailunw/article/details/118611510
Hadoop使用教程(1):单节点部署
部署jdk环境 jdk版本:8u311 解压 tar -zxvf /opt/software/jdk-8u311-linux-x64.tar.gz -C /opt/module/ 更改文件名 mv /opt/module/jdk1.8.0_311/ /opt/module/jdk8 添加jdk环境变量 vim /etc/profile 内容添加(文件末尾) #jdk8
export JA…

HDFS系统权限详解
一,HDFS超级用户 启动namenode的用户就是HDFS中的超级用户 如图所示 HDFS中,也是有权限控制的,其控制逻辑和Linux文件系统的完全一致 但是不同的是,两个系统的Supergroup不同(超级用户不同) Linux的操作用户是root HDFS文件系统的…
请小心Hadoop2.5.0和Java Web项目集成bug
[b][colorgreen][sizelarge]今天,散仙在Myeclipse构建的Java的Web项目里使用hadoop2.5的jar包,去连接Linux系统上的HDFS,做一个数据展示的工程,发生了一个莫名其妙的异常,信息如下:[/size][/color][/b]Exce…
![summary.typeQuotaInfos.typeQuotaInfo[3].type](https://img-blog.csdnimg.cn/20210601133619905.png)
summary.typeQuotaInfos.typeQuotaInfo[3].type
文章目录摘要原因一:解决方案:原因二:解决办法一:解决办法二:其他文章答案讨论摘要
在使用工具方法fs.getContentSummary(path)方法获取hbase库表信息时报错,报错如下:
java.io.IOException: …
Hadoop面试题(HDFS篇)
1.HDFS写流程?以及参与的组件?
----------------------流程图---------------------------
A(Client) -- 发送写请求 --> B(NameNode)
B -- 返回可用DataNodes列表 --> A
A -- 选择主节点 --> C(主节点Primary DataNode)
C -- 建立连接 --> A
A -- 发…
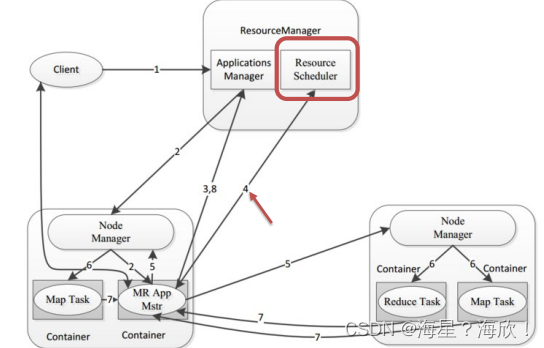
Hadoop YARN
目录Hadoop YARN介绍Hadoop YARN架构、组件程序提交YARN交互流程YARN资源调度器Scheduler调度器策略FIFO SchedulerCapacity SchedulerFair SchedulerHadoop YARN介绍
YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 上图࿱…

使用Java API操作HDFS
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录学习目标(一)了解HDFS Java API1、HDFS常见类与接口2、FileSystem的常用方法(二)编写Java程序访问HDFS1、创建Maven项…
【HDFS】FsDatasetImpl#recoverClose方法
recoverClose的目的recoverClose的过程recoverClose的调用点一、前言
HDFS客户端写文件时,如果某个datanode发生错误或者异常。客户端会把这个datanode从pipeline里踢除,然后进行pipiline recovery,用剩余datanodes去写或者满足一定的条件时补充新的datanode到pipeline中写…

大数据技术实验一-在ubuntu18.04中安装伪分布式Hadoop并使用自带wordcount案例
必要时转载请标明出处 本文是在ubuntu上安装Hadoop的操作,关于如何在centOS上安装Hadoop可参考 https://blog.csdn.net/hgxiaojiujiu/article/details/120382331 实验一 熟悉常用的Linux操作和Hadoop操作
一、 实验目的
(1)掌握Linu虚拟机的…
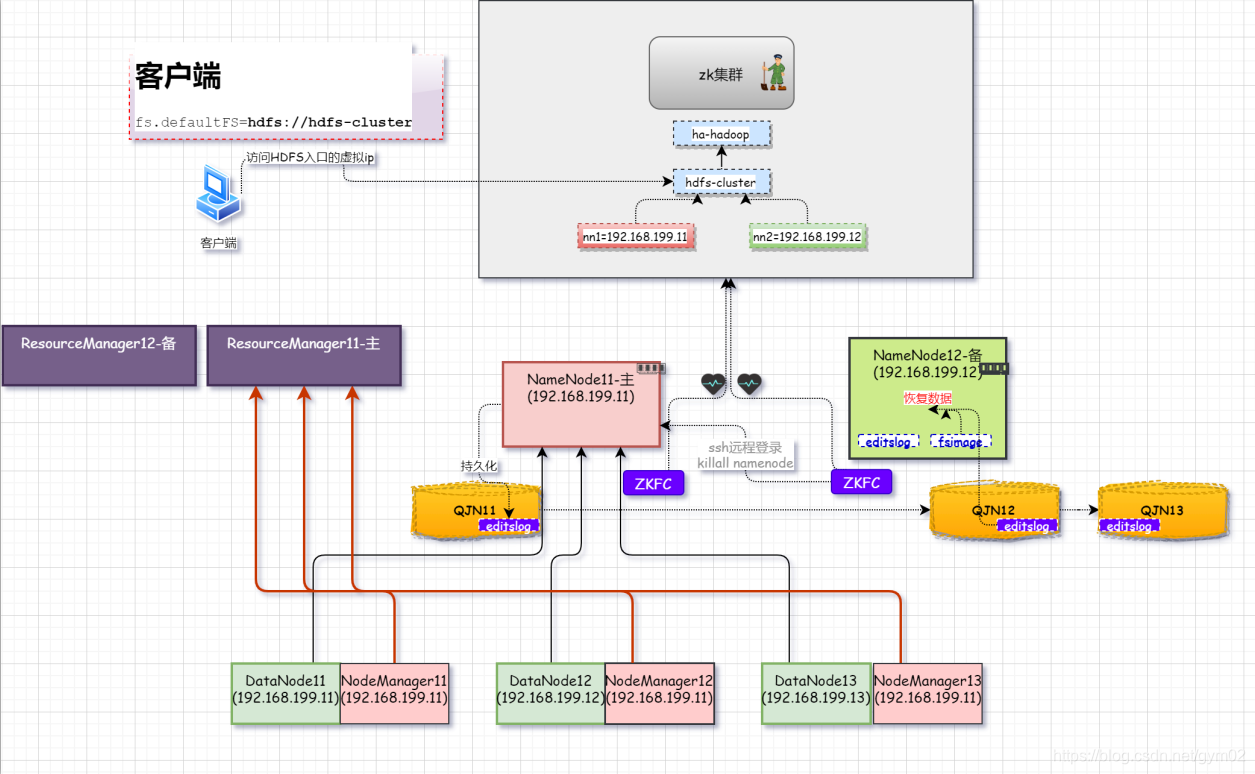
HAHadoop架构分析 (高可用 Hadoop架构)
1.NameNode单点故障
概念:如果NN主机宕机,导致整个HDFS集群中所有节点全部停止工作。 解决思路:为NameNode主机提供一个NameNode备机。
方法: 1.实时监控NameNode11宕机 2.发现NameNode11宕机,触发一段操作。启动Nam…
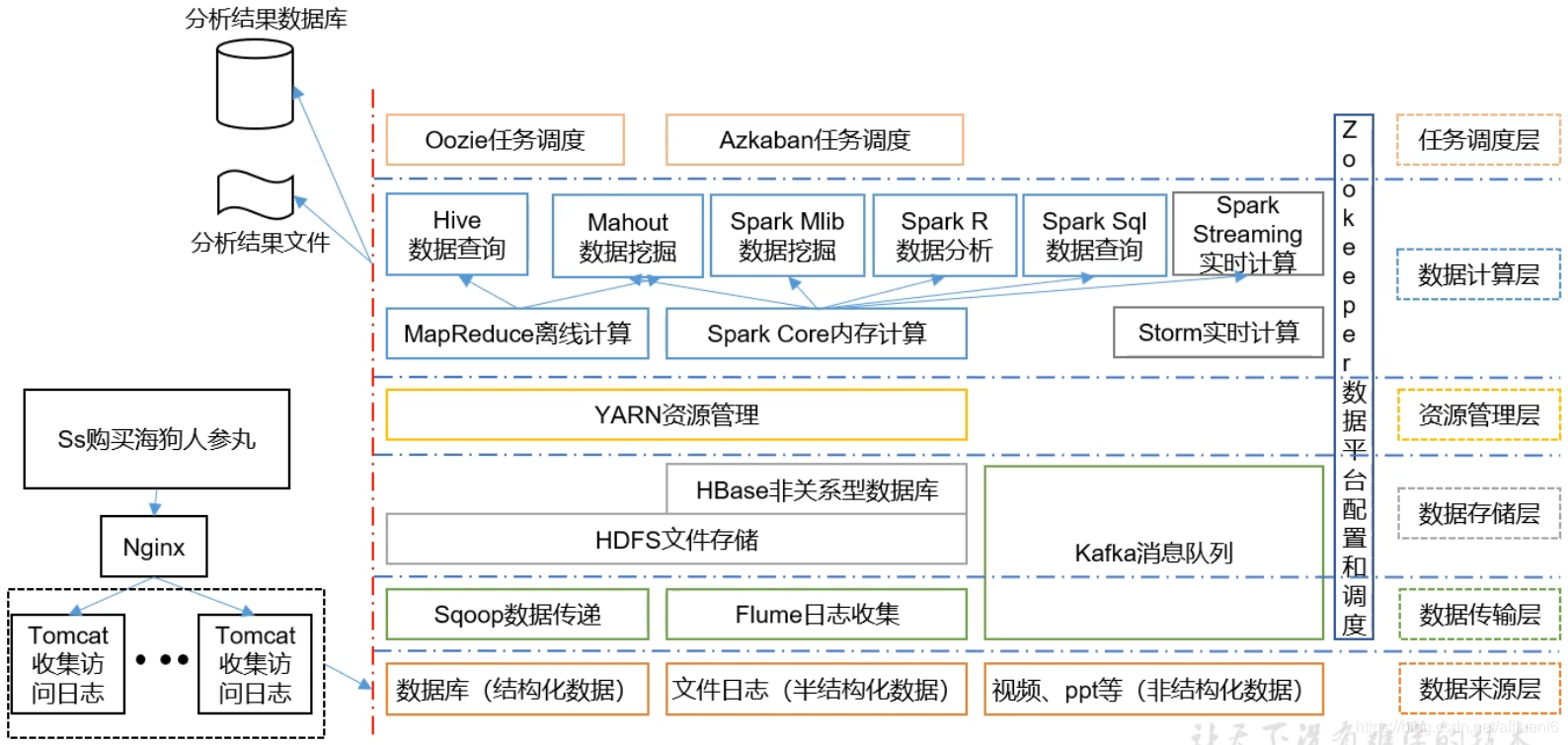
大数据学习框架综述-Hadoop组成、大数据生态、推荐系统技术框架
本文目录如下:大数据学习框架综述大数据学习框架综述
Hadoop的组成 注:YARN之上调用的是MapReduce计算框架,也可调用其它计算框架的资源,如Spark、Flink。 大数据技术生态体系 图中涉及的技术名词解释如下: Sqoop&…
hadoop hdfs读写
hadoop hdfs读写 hdfs读取文件 1.FSDataInputStream,open创建输入流,建立与nameNode的连接 2.调用getBlockLoction获得hdfs文件的数据块位置 3.FSDataInputStream, read根据数据块位置,建立与datanode的连接,读取数据块 4.在读取到…
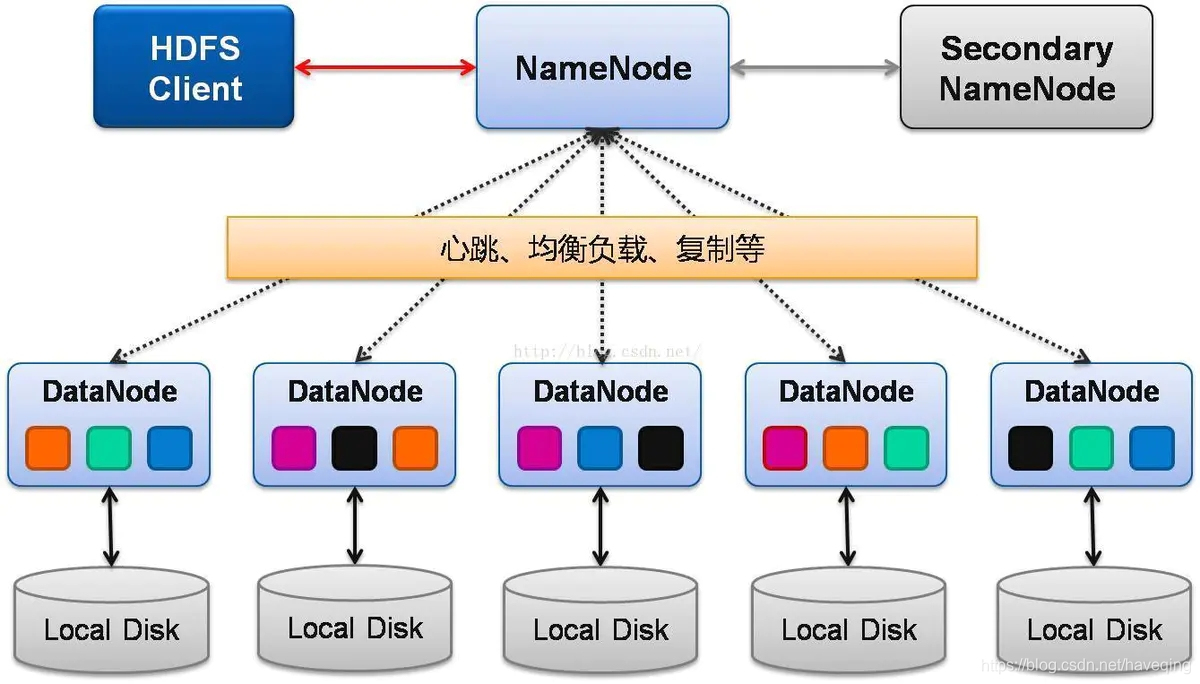
HDFS的NameNode节点信息管理(元数据)
文章目录HDFS的NameNode信息1、NameNode的信息存放地址2、NameNode节点数据查看3、fsimage文件4、edits文件HDFS的NameNode信息
1、NameNode的信息存放地址
NameNode存储DataNode的元数据,NameNode主要是用于维护DataNode信息。它存储在hadoop文件夹下data/dfs/na…
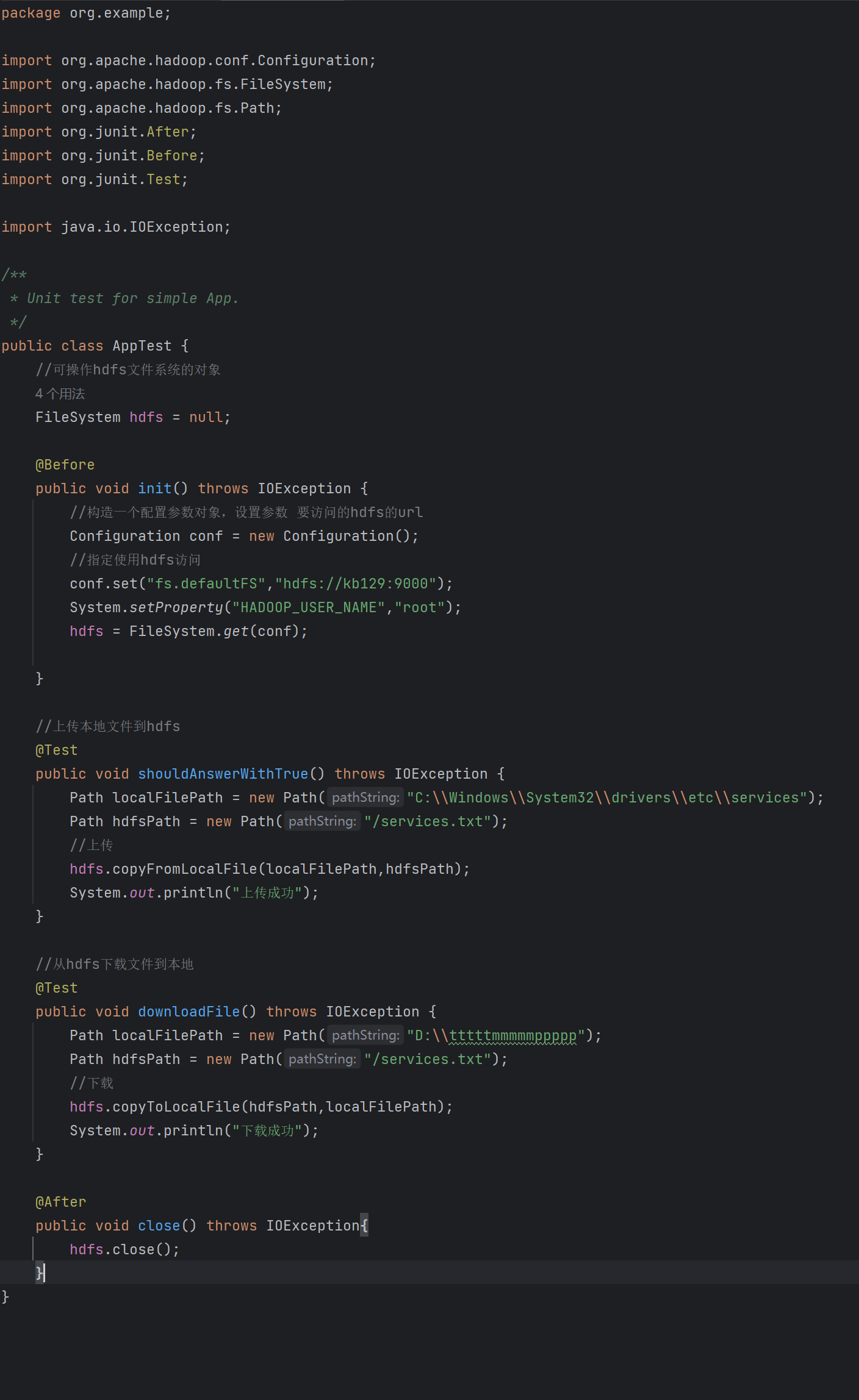
利用Java实现HDFS文件上传下载
文章目录利用Java实现HDFS文件上传下载1、pom.xml配置2、创建与删除3、文件上传4、文件下载利用Java实现HDFS文件上传下载
1、pom.xml配置
<!--配置-->
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.c…
Java 读取UTF-8文件中文乱码
Java 读取UTF-8文件中文乱码 InputStreamReader isr new InputStreamReader(new FileInputStream(file), "UTF-8"); BufferedReader read new BufferedReader(isr); 例如: private static String readUTF8File(String filePath) throws IOException {In…
Hadoop系列文章SpringBoot编程实现HDFS读写文件、MapReduce程序
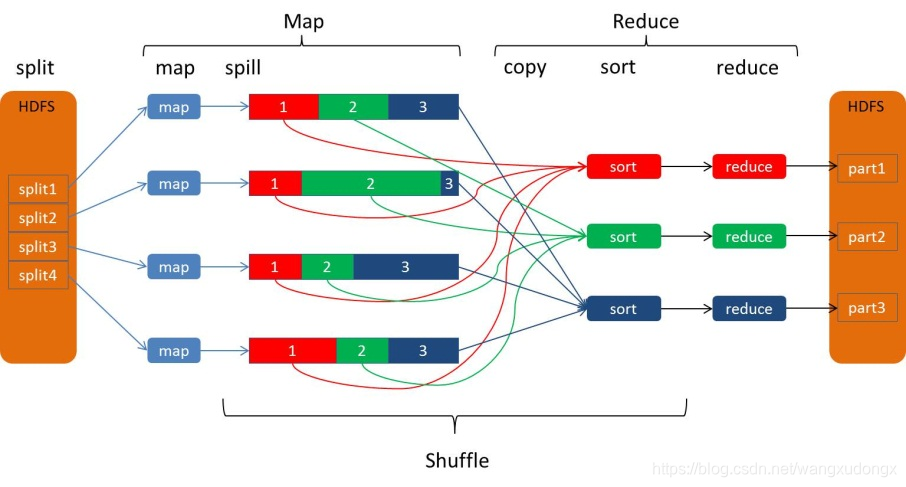
Hadoop系列文章 SpringBoot编程实现HDFS读写文件、MapReduce程序实现HDFS操作引入依赖winutils码代码读取HDFS中的文件写内容到文件中MapReduce操作MapReduce工作过程详解Mapper映射器Input的mapmap的outputmap的数量ReducershuffleSort(排序)二次排序reducePartitionerCounter…
大数据技术之Hadoop:使用命令操作HDFS(四)
目录
一、创建文件夹
二、查看指定目录下的内容
三、上传文件到HDFS指定目录下
四、查看HDFS文件内容
五、下载HDFS文件
六、拷贝HDFS文件
七、HDFS数据移动操作
八、HDFS数据删除操作
九、HDFS的其他命令
十、hdfs web查看目录
十一、HDFS客户端工具
11.1 下载插件…

大数据开发之Hive案例篇12:HDFS rebalance 一例
文章目录 一. 问题描述二. 解决方案2.1 增加节点2.2 rebalance2.3 rebalance引发的问题 一. 问题描述
公司的离线数仓是CDH集群,19个节点,HDFS存储空间大约400TB左右,使用量在200TB左右。 由于历史遗留的问题,数据仓库需要重构&a…
Hadoop 3.x(MapReduce)----【MapReduce 框架原理 三】
Hadoop 3.x(MapReduce)----【MapReduce 框架原理 三】1. OutputFormat接口实现类2. 自定义OutputFormat案例实操1. 需求2. 需求分析3. 案例实操4. 测试输出结果1. OutputFormat接口实现类
OutputFormat 是 MapReduce 输出的基类,所有实现 Ma…

Apache Ranger控制功能
Apache Ranger控制功能# Apache Ranger 是一个在hadoop平台上使用的组件,可以全面监控和管理数据的安全。有关Ranger的安装见我另一篇博客ranger的安装及问题解决。
Apache Ranger目前支持的组件如下 Ranger-usersync用于同步linux的用户和用户组,在ran…
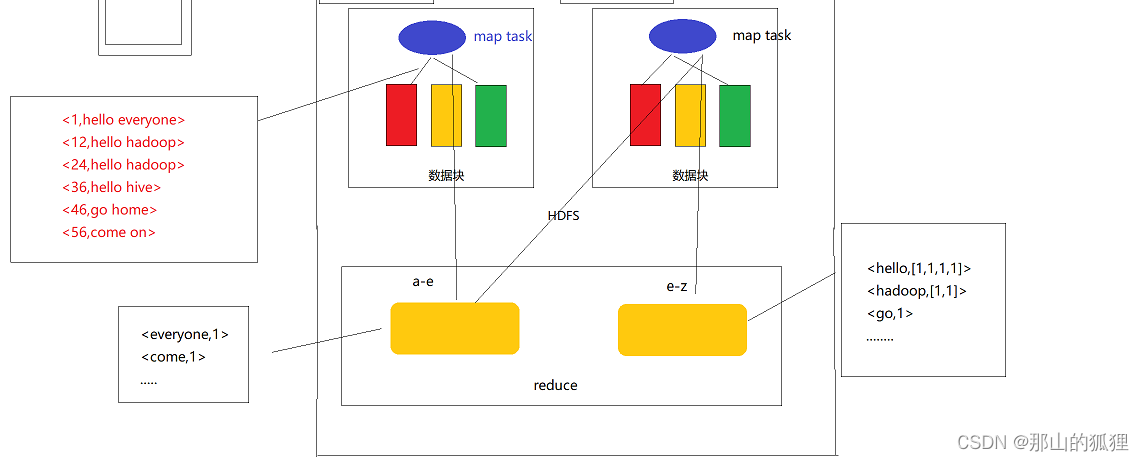
MapReduce原理
MapReduce 编程规范
MapReduce 的开发一共有八个步骤, 其中 Map 阶段分为 2 个步骤,Shuffle 阶段 4 个步骤,Reduce 阶段分为 2 个步骤Map 阶段 2 个步骤
设置 InputFormat 类, 将数据切分为 Key-Value(K1和V1) 对, 输入到第二步自定义 Map 逻辑, 将第一…
HDFS工作流程和机制
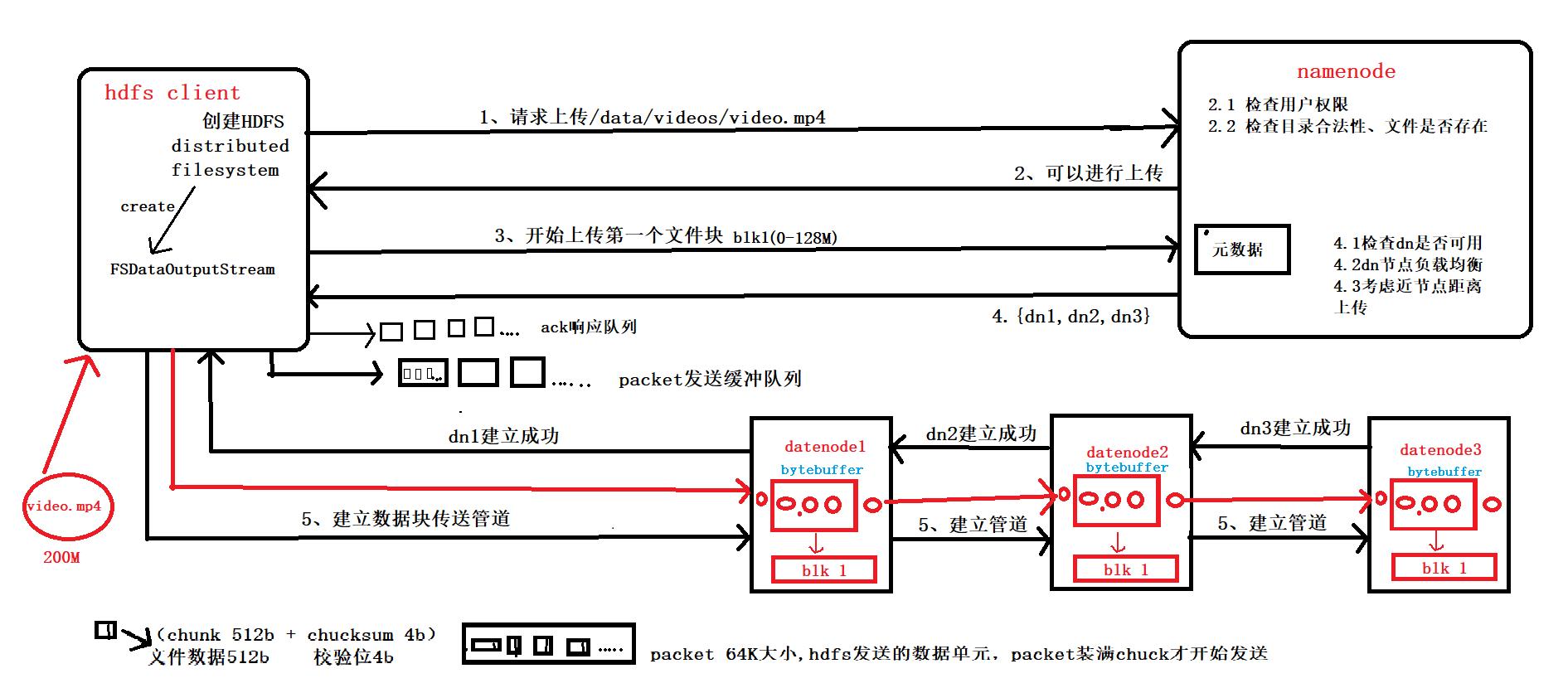
HDFS写数据流程(上传文件)
核心概念--Pipeline管道
HDFS在上传文件写数据过程中采用的一种传输方式。
线性传输:客户端将数据写入第一个数据节点,第一个数据节点保存数据之后再将快复制到第二个节点,第二节点复制给…

详细记录Linux服务器搭建Hadoop3高可用集群
详细记录Linux服务器搭建Hadoop3高可用集群搭建Hadoop3高可用集群下载Hadoop修改集群环境修改配置文件修改环境变量分发软件到其他节点启动Zookeeper启动JournalNode格式化NameNode启动ZKFC启动HDFS启动yarn查看进程主备切换测试作业测试搭建Hadoop3高可用集群
Hadoop节点Name…
消费flume的数据无法上传到HDFS
问题:打开hadoop102:9870发现没有出现flume的数据
检查采集flume这部分,在kafka里可以读取到数据,说明是消费flume这部分出错,检查日志信息。
使用消费flume启动停止脚本,可以看到日志信息是在 /opt/module/flume/lo…
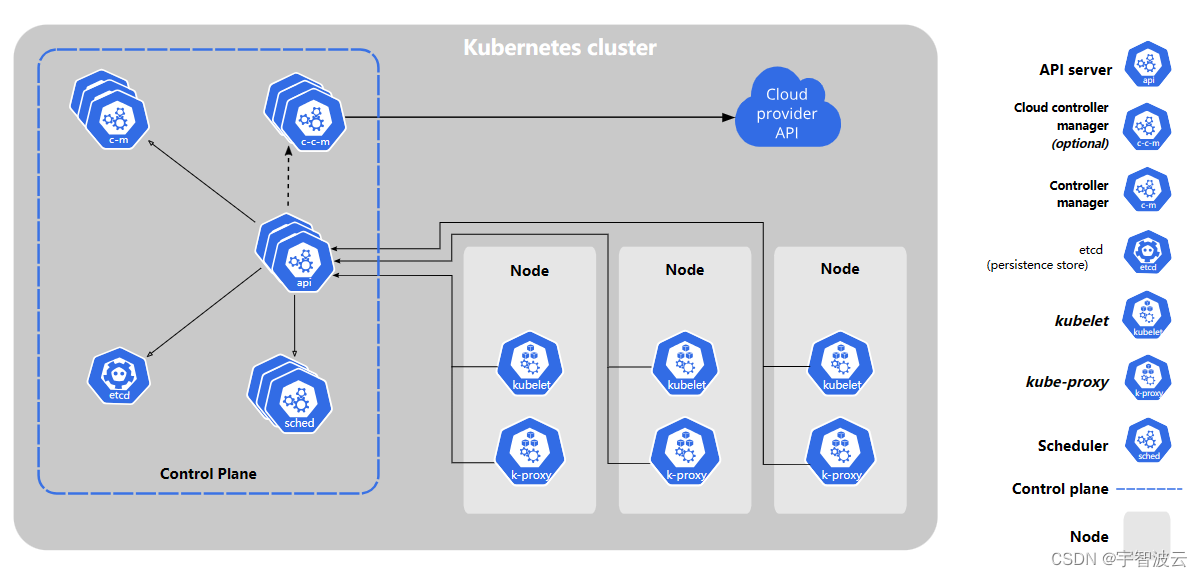
修炼k8s+flink+hdfs+dlink(四:k8s(二)组件)
一:控制平面组件。
控制平面组件会为集群做出全局决策,比如资源的调度。 以及检测和响应集群事件,例如当不满足部署的 replicas 字段时, 要启动新的 pod)。
1. kube-apiserver。
该组件负责公开了 Kubernetes API&a…
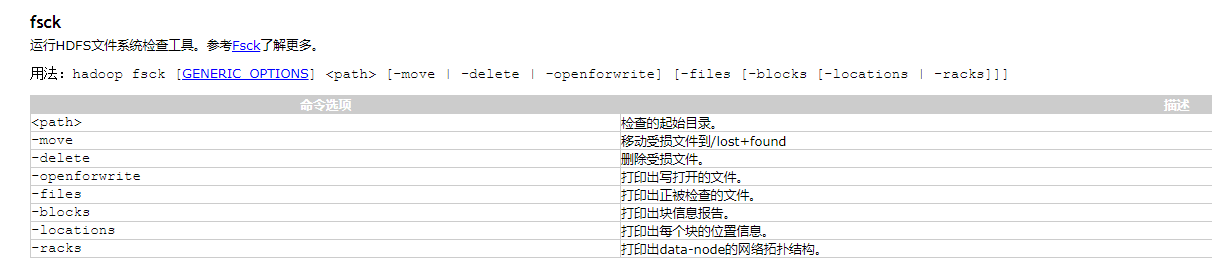
hdfs——简单操作
来记录一些hdfs命令 #将test.txt文件上传到hdfs的根路径下 hdfs dfs -put test.txt / #显示目录内容 hdfs dfs -ls / #显示占用空间 hdfs dfs -du -h / #递归显示目录内容 hdfs dfs -ls -R / #显示文件内容 hdfs dfs -cat /test.txt hdfs dfs -text /test.txt #下载到本地 hd…

分布式对象存储——Apache Hadoop Ozone
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 1. 概述 Ozone是Apache Hadoop项目的子项目…
HDFS系统操作命令大全
一,前言 HDFS作为分布式存储的文件系统,有其对数据的路径表达方式 HDFS同linux系统一样,均是以/作为根目录的组织形式 linux:/usr/local/hello.txt HDFS:/usr/local/hello.txt 二,如何区分呢? L…

头歌Educoder云计算与大数据——实验三 分布式文件系统HDFS
实验三 分布式文件系统HDFS第1关:HDFS的基本操作任务描述相关知识HDFS的设计分布式文件系统NameNode与DataNodeHDFS的常用命令编程要求测试说明代码实现第2关:HDFS-JAVA接口之读取文件任务描述相关知识FileSystem对象FSDataInputStream对象编程要求测试说…
Hadoop环境的基准测试----自己电脑搭虚拟机的话就别测了,我电脑的主板差点烧了。
写文件测试
[userNewBieMaster sbin]$ hadoop jar /home/user/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 8MB
2021-07-03 15:28:52,823 INFO fs.TestDFSIO: TestDFSIO.1.8
2021-07-03 …
技术文章 | Hadoop常见错误和处理方式
本文来源于阿里云-云栖社区,原文点击这里。 常见问题及处理 mysql版本,必须是MYSQL5.1。 查询办法mysqladmin version 在建立hive数据库的时候,最好是:create database hive; oozie的数据库,同样:create database oozi…

HDFS小文件问题分析与解决方案(面试层面~)
会造成的影响
(1)存储层面:
在HDFS中,每个block,文件或者目录在内存中均以对象的形式存储 1个文件块,占用namenode多大内存150字节 1亿个小文件*150字节 1个文件块 * 150字节 这样会使namenode内存容量严…
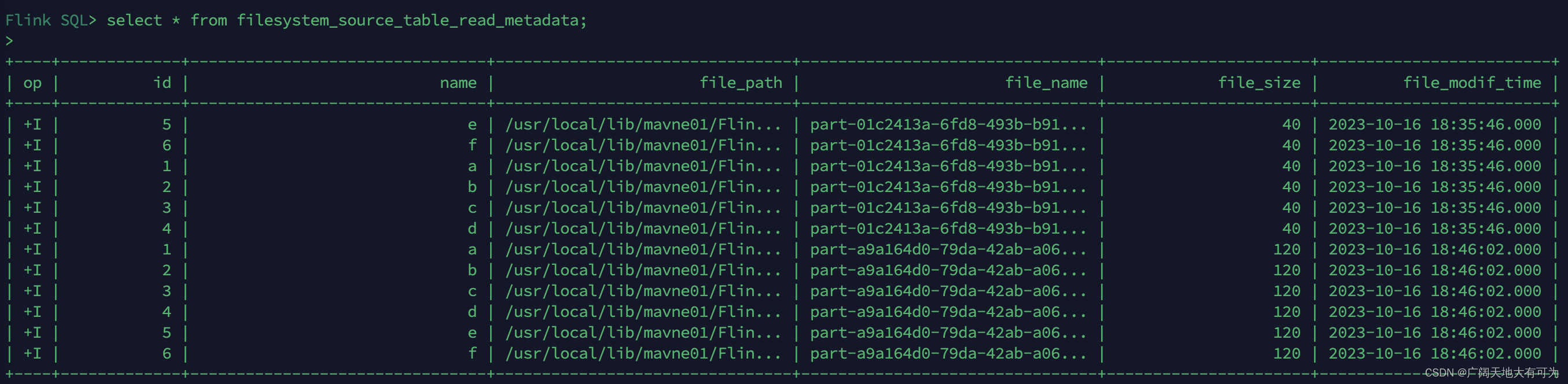
2.2 如何使用FlinkSQL读取写入到文件系统(HDFS\Local\Hive)
目录
1、文件系统 SQL 连接器
2、如何指定文件系统类型
3、如何指定文件格式
4、读取文件系统
4.1 开启 目录监控
4.2 可用的 Metadata
5、写出文件系统
5.1 创建分区表
5.2 滚动策略、文件合并、分区提交
5.3 指定 Sink Parallelism
6、示例_通过FlinkSQL读取kafk…
HDFS中block的大小
block的大小与修改
Hadoop2.x/3.x版本中Block的默认大小为128M,早前版本中默认为64M,开发人员可以在hdfs-site.xml中添加如下标标签进行修改。
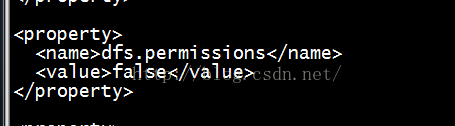
<!-- hdfs-site.xml -->
<property><name>dfs.blocksize</name>#value值代表blo…
大数据技术原理与应用介绍
大数据技术原理与应用
概述
大数据不仅仅是数据的“大量化”,而是包含“快速化”、“多样化”和“价值化”等多重属性。
两大核心技术:分布式存储和分布式处理
大数据计算模式
批处理计算流计算图计算查询分析计算
大数据具有数据量大、数据类型繁…
HDFS集群NameNode高可用改造
文章目录 背景高可用改造方案实施环境准备配置文件修改应用配置集群状态验证高可用验证 背景
假定目前有3台zookeeper服务器,分别为zk-01/02/03,DataNode服务器若干;
目前HDFS集群的Namenode没有高可用配置,Namenode和Secondary…

修炼k8s+flink+hdfs+dlink(四:k8s(一)概念)
一:概念
1. 概述
1.1 kubernetes对象.
k8s对象包含俩个嵌套对象字段。 spec(规约):期望状态 status(状态):当前状态 当创建对象的时候,会按照spec的状态进行创建,如果…

大数据项目实战---电商埋点日志分析(第五部分,DWS层之用户活跃主题)
1)创建用户按天明细表,dws_uv_detail_day并加载数据。 2)创建用户按周明细表,dws_uv_detail_wk并加载数据。 3)创建用户按月明细表,dws_uv_detail_mn并加载数据。 下一章 https://blog.csdn.net/hailunw/ar…
Java大数据开发之HDFS详解
Java大数据开发——HDFS详解
1. HDFS 介绍• 什么是HDFS 首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件。 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务…
海量数据分布式存储技术-作业三
1.HDFS的名称节点和数据节点的具体功能;
2.HDFS如何减轻中心节点的负担;
3.HDFS设置唯一一个名称节点的局限性表现在哪些方面;
4.HDFS如何探测错误发生以及如何进行恢复;
5.HDFS不发生故障的情况下读文件的过程;
…
大数据小白初探HDFS从零到入门(一)
目录
1. 前言
2. 大数据的诞生
3.发展趋势及应用
4.离线计算和实时计算
5.大数据的特性 1. 前言 前两天把Hbase的初级入门知识整理了下,在文章中提到了“HDFS”这个大数据的基础,有同事小伙伴想要了解下这方面的知识,今天我把之前整理的内容也给同事讲了下,顺便我把他…
Hadoop之MapReduce的使用示例
MapReduce的基本使用
添加依赖 <dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.3</version></dependency><dependency><groupId>or…
报错:Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop102:10000
报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop102:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException)…

MapReduce将HDFS文本数据导入HBase中
HBase本身提供了很多种数据导入的方式,通常有两种常用方式:
使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase另一种方式就是使用HBase原生Client API
本文就是示范如何通过MapReduce作业从一个文件读取数据并…

python读写hdfs文件的实用解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…
大数据周会-本周学习内容总结03
目录
01【大数据导论与Linux基础】
02【Apache Hadoop、HDFS】
03【Hadoop MapReduce与Hadoop YARN】
04【数据仓库基础与Apache Hive入门】
05【Apache Hive DML语句与函数使用】
06【Hadoop生态综合案例:陌陌聊天数据分析】 01【大数据导论与Linux基础】 大…
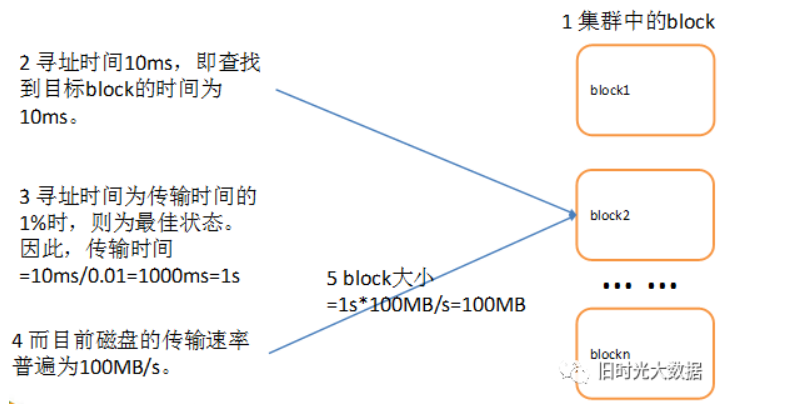
4.Hadoop三件套(1)
如果说HDFS是存储,则Yarn就是cpu和内存,mapreduce就是程序。 1.HDFS文件块大小
HDFS中的文件在物理.上是分块存储(Block) ,block默认保存3份块的大小可以通过配置参数(dfs blocksize)来规定,默认大小在Hadoop2 .x版本中是128M,老版本中是64M。
解释:块的大小:10ms*100*…

java使用hbase、hadoop报错举例
文章目录摘要情况1:NoClassDefFoundError情况2:使用hbase报错:NullPointerException情况3:summary.typeQuotaInfos.typeQuotaInfo[3].type摘要
总结自己springboot项目使用hbase、hadoop中出现的莫名奇怪的依赖使用报错
hbase …
hadoop-HDFS
1.HDFS简介 2.1 Hadoop分布式文件系统-HDFS架构 2.2 HDFS组成角色及其功能 (1)Client:客户端 (2)NameNode (NN):元数据节点 管理文件系统的Namespace元数据 一个HDFS集群只有一个Active的NN ÿ…

HDFS读写数据流程、NameNode与DataNode工作机制
文章目录 HDFS 写数据流程HDFS 读数据流程HDFS 节点距离计算HDFS 机架感知HDFS NN和2NN工作机制HDFS FsImage镜像文件HDFS Edits编辑日志HDFS 检查点CheckPoint时间设置HDFS 退役旧数据节点HDFS DataNode多目录配置HDFS DataNode工作机制HDFS 数据完整性HDFS 掉线时限参数设置 …
HDFS和MapReduce综合实训
文章目录 第1关:WordCount词频统计第2关:HDFS文件读写第3关:倒排索引第4关: 网页排序——PageRank算法 第1关:WordCount词频统计
测试说明 以下是测试样例:
测试输入样例数据集:文本文档test1…
玩转大数据开发工具--上下全篇
为了降低大数据应用开发的门槛,简化开发过程,星环随Transwarp Data Hub 5.0开发出了大数据开发套件Transwarp Studio。Studio由一套PaaS产品构成,提供从提取、存储、计算、展示的全链路大数据开发服务,全面覆盖大数据开发流水线上…
怎样成为一名真正的数据科学家?这10本书就是答案
导读:社交、出行、办公、购物、娱乐……一个生活在2020年的人,每天要产生多少数据?这些数据将怎样改变我们的生活、工作和思维方式?将创造哪些价值?这些价值又该怎样挖掘?
数据科学家被《哈佛商业评论》称…

hadoop-Yarn资源调度器【尚硅谷】
大数据学习笔记 Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行与操作系统之上的应用程序。 (也就是负责MapTask、ReduceTask等任…
java遍历hdfs路径信息,报错EOFException
文章目录代码代码 FileSystem fsFileSystem.get(new URI("hdfs://192.168.20.91:9000"), new Configuration(), "hdfs");ContentSummary in fs.getContentSummary(new Path("/apps/hbase/data/data/default"));报错原因:指定的hdfs端…

Hadoop入门篇02---HDFS学习与简单使用
Hadoop入门篇02---HDFS学习与简单使用 存储系统概念认识硬盘,RAID小结 存储架构DAS,NAS,SAN对比 文件系统 大数据存储大数据存储面临的问题如何解决小结 HDFSHDFS的起源和发展HDFS的设计目标HDFS的应用场景HDFS的特性命令行实践常用命令 Java客户端API使…
实验七 MapReduce编程进阶
实验七 MapReduce编程进阶答案在链接里https://blog.csdn.net/weixin_45818379/article/details/117790528
【HDFS】BlockReceiver#flushOrSync方法
此方法的功能就是把块数据和元数据文件从datanode缓冲区flush到操作系统缓冲区,如果isSync为true的话,还会做fsync系统调用把文件数据和元数据持久化到磁盘上。
参数: boolean isSync :是否进行同步(涉及到的底层系统调用是fsync)long seqno :packet的序列号(在本方法…

Hadoop使用hdfs指令查看hdfs目录的根目录显示被拒
背景
分布式部署hadoop,服务机只有namenode节点,主机包含其他所有节点
主机关机后,没有停止所有节点,导致服务机namenode继续保存
再次开启主机hadoop,使用hdfs查看hdfs根目录的时候显示访问被拒 解决方案
1.主机再次开启hadoop并继续执行关闭
2.服务器再次开启hadoop并继…
hadoop 编写开启关闭集群脚本, hadoop hdfs,yarn开启关闭脚本。傻瓜式hadoop脚本 hadoop(九)
1. 三台机器: hadoop22, hadoop23, hadoop24
2. hdfs在22机器启动,yarn在hadoop23机器
3. 脚本需要hadoop用户启动才可以
4. 脚本:
#!/bin/bashHADOOP_PATH"/opt/module/hadoop-3.3.4"# 检查脚本执行用户是否为 hadoop
if [ &q…
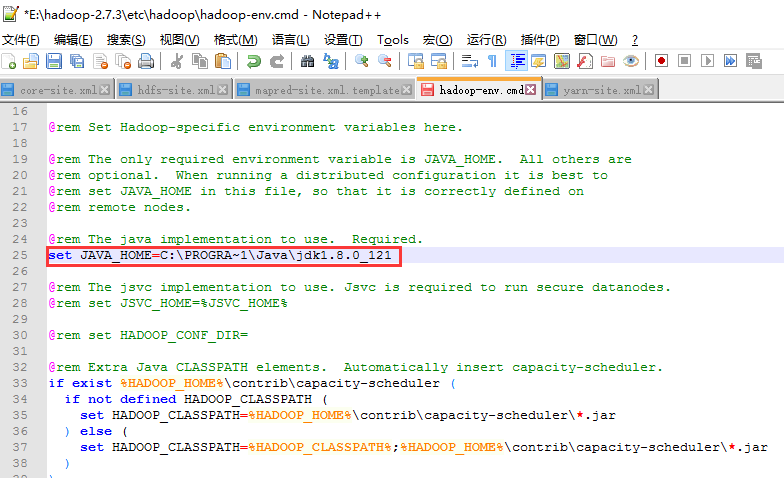
Error: JAVA_HOME is incorrectly set. Please update F:\hadoop\conf\hadoop-env.cmd解决方法
在控制台中输入hdfs后提示Error: JAVA_HOME is incorrectly set. Please update F:\hadoop\conf\hadoop-env.cmd错误如下图 如果你的JAVA_HOME环境变量配置也没问题,在控制台中输入java -version得到如下输出则说明没问题: 打开E:\hadoop-2.7.3\etc\had…
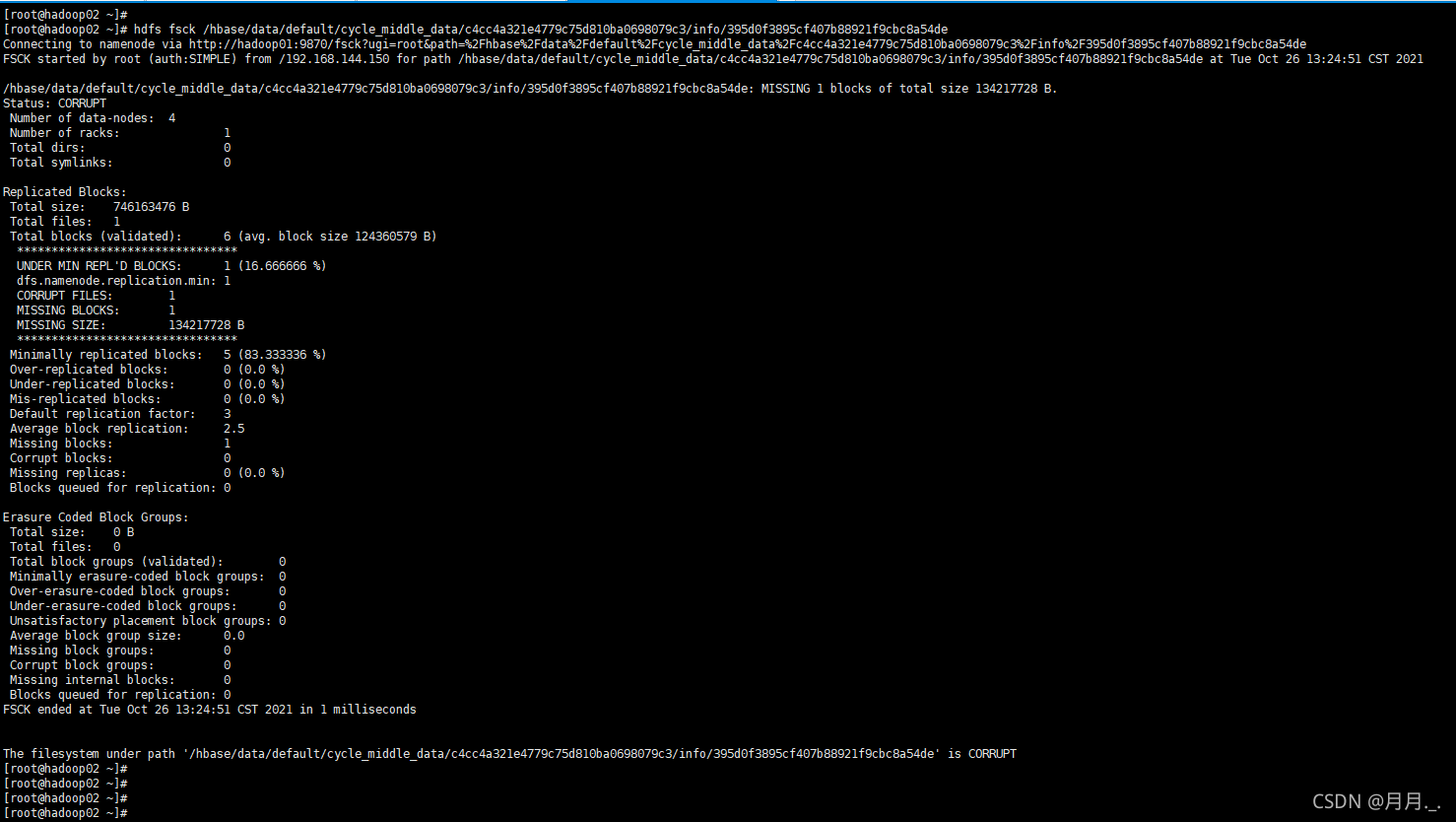
Hive执行异常org.apache.hadoop.hdfs.BlockMissingException
今天hive在执行的时候出现了报错,内容如下:
Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-2040810143-192.168.144.145-1612269795515:blk_1077591653_3851069 file/hbase/data/default/cycle_middle_data/c4…
Hadoop Streaming使用简介
一、Hadoop Streaming 它是hadoop的一个工具,用来创建和运行一类特殊的map/reduce作业。所谓的特殊的map/reduce作业可以是可执行文件或脚本本件(python、PHP、c等)。Streaming使用“标准输入”和“标准输出”与我们编写的Map和Reduce进行数据…

Hadoop 3.x(生产调优手册)----【HDFS--多目录】
Hadoop 3.x(生产调优手册)----【HDFS--多目录】1. NameNode多目录配置2. DataNode多目录配置3. 集群数据均衡之磁盘间数据均衡1. NameNode多目录配置
NameNode 的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性 具…
03.hadoop上课笔记之hdfs环境的搭建和使用
1.启动网络 在windows任务管理器启动服务vm Dhcp
#由动态ip变为静态 #启动网卡ifup ens33#修改网卡配置文件vi /etc/sysconfig/network-scripts/ifcfg-ens33BOOTSTRAPstaticIPADDR192.168.202.101NETMASK255.255.255.0GATEWAY192.168.202.2DNS1192.168.202.2#重启网络 servic…
Hadoop与Linux常用交互命令
交互命令
一般,在linux命令前加hadoop fs或者hdfs dfs即可
切换为hdfs用户,一般hdfs用户有hdfs文件的权限
[roothadoop01 ~]# su - hdfshadoop fs -mkdir -p 目录:在hdfs上创建目录
[roothadoop01 ~]# hadoop fs -mkdir -p /data/testhad…

Call From master.hadoop/192.168.31.149 to master.hadoop:8020 failed on connection exception: java.ne
学习hadoop新手易犯错误:Call From master.hadoop/192.168.31.149 to master.hadoop:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused 产生此错误的原因是had…
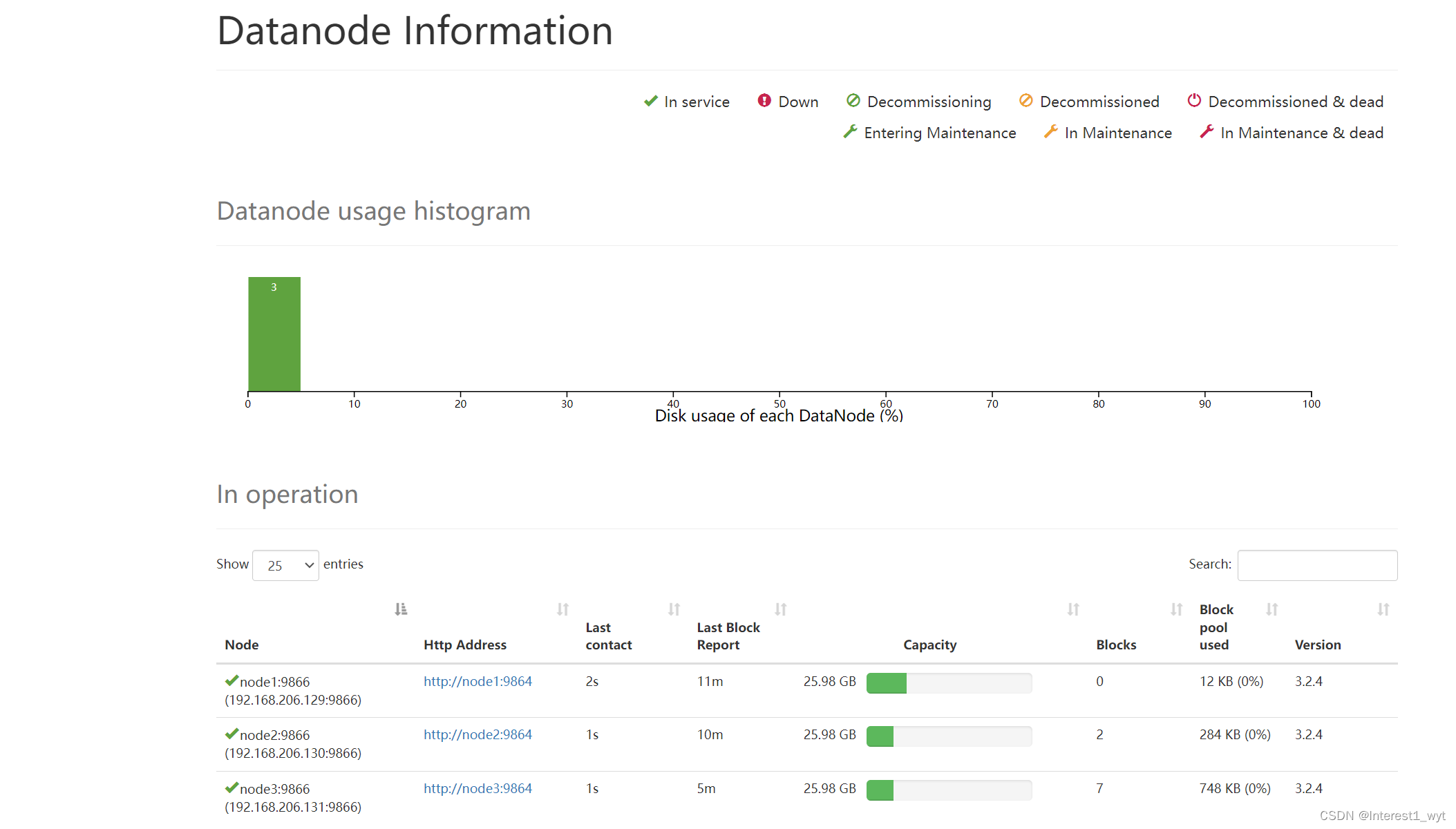
在Web端查看各节点状态(总结)
本文目录如下:5 在Web端查看各节点状态(总结)5.1 Web端查看HDFS的NameNode5.2 Web端查看HDFS的DataNode5.3 Web端查看HDFS的SecondaryNameNode5.4 Web端查看YARN的ResourceManage5.5 查看HDFS上传的文件5.6 查看历史服务器信息5.7 查看日志聚集信息5 在Web端查看各节…
Hadoop_API文件下载文件删除文件移动、更名
1、完整代码
package com.atguigu.hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
…
《聚焦人脸识别的大数据测试系统》赛题讲解
竞赛:21年浙江省服务外包竞赛,题目:《聚焦人脸识别的大数据测试系统》,获得奖项:二等奖
一、赛题介绍
此题目要以虹软公司人脸识别SDK产品为例,开展针对人脸识别产品的大数据测试。
(1&#…
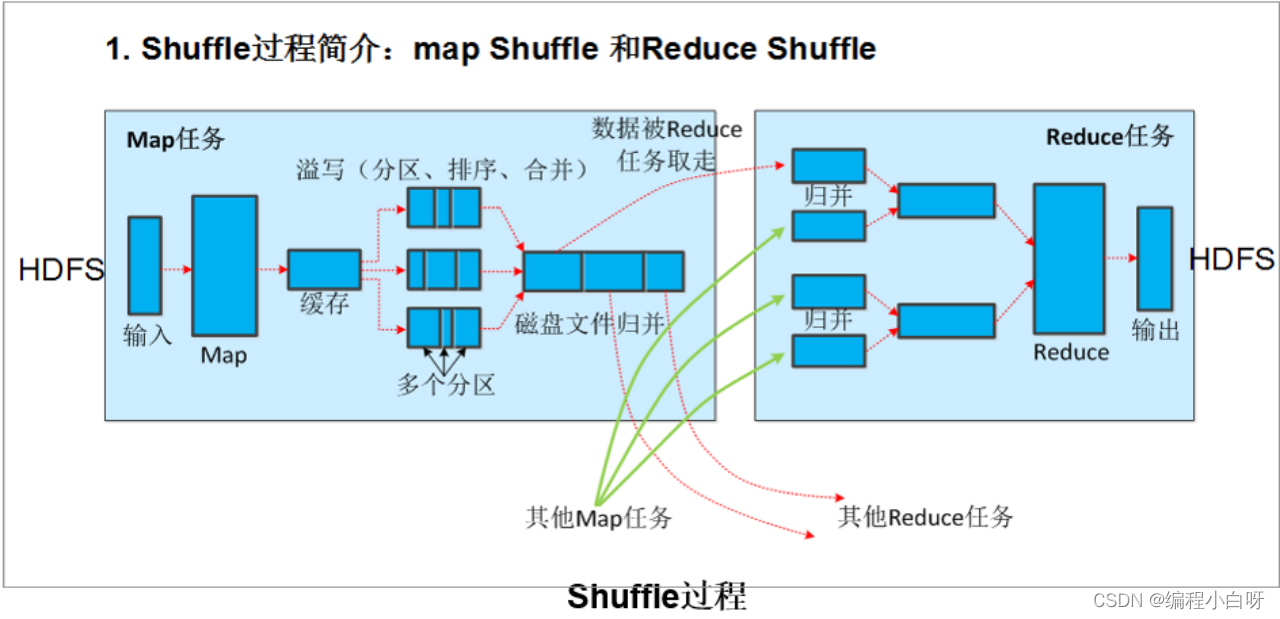
【大数据】Hadoop总结
本文对于Hadoop中的HDFS和MapReduce的相关面试重点进行了总结,下篇将介绍调优、数据倾斜等进阶知识。 Hadoop总结 一、概述1. Hadoop特性2. HDFS结构HDFS 架构 二、HDFS分布式文件系统1 概述2. HDFS存储数据架构图NameNodeDataNode 3 HDFS优点4 HDFS缺点(…
hadoop集群启动之后safe mode is on问题解决_2020-09-16
问题描述 当启动hadoop集群的时候,没有报错,进入hadoop:50070端口也正常,但是在Summary中,安全模式提示为on。不知为何。。。。
当启动hive的时候,会报错:namenode safemode is on
然后看其他博客说是因为…
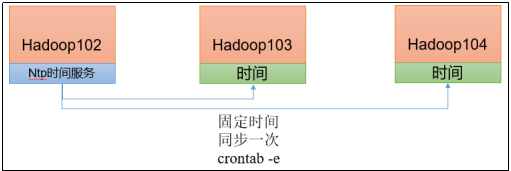
Hadoop入门常见面试题与集群时间同步操作
目录 一,常用端口号
Hadoop3.x :
Hadoop2.x:
二,常用配置文件:
Hadoop3.x:
Hadoop2.x:
集群时间同步:
时间服务器配置(必须root用户):
(1)…

PiflowX组件 - Filter
Filter组件
组件说明
数据过滤。
计算引擎
flink
组件分组
common
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子conditioncondition“”无是过滤条件。age > 50 or age < 20
Filter示例…
大数据开发之Hadoop(完整版+练习)
第 1 章:Hadoop概述
1.1 Hadoop是什么
1、Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 2、主要解决,海量数据的存储和海量数据的分析计算问题。 3、Hadoop通常是指一个更广泛的概念-Hadoop生态圈
1.2 Hadoop优势(4高…
![[Hadoop] 期末答辩问题准备](https://img-blog.csdnimg.cn/img_convert/12b1e2d154fda054afd4484a1fe96a61.jpeg)
[Hadoop] 期末答辩问题准备
0.相关概念
1.什么是NameNode?
NameNode是整个文件系统的管理节点,它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。并接收用户的操作请求。
2.SecondaryNameNode的主要作用?
SecondaryNameN…

阿语python4-2 美多商城v5.0商品-准备商品数据之第6.2.4节录入商品数据和图片数据...
1. SQL脚本录入商品数据$ mysql -h127.0.0.1 -uroot -pmysql meiduo_mall < 文件路径/goods_data.sql2. FastDFS服务器录入图片数据1.准备新的图片数据压缩包2.删除 Storage 中旧的data目录3.拷贝新的图片数据压缩包到 Storage,并解压# 解压命令
sudo tar -zxvf …
【Ambari】HDFS基于Ambari的常规运维
🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁…
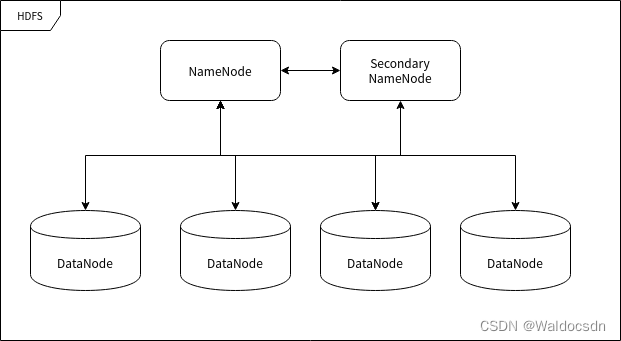
Hadoop学习笔记(一)分布式文件存储系统 —— HDFS
概念
HDFS (Hadoop Distributed File System),Hadoop分布式文件系统,用来存超大文件的。
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
NameNode : 负责执行有关 文件系统命名空间…
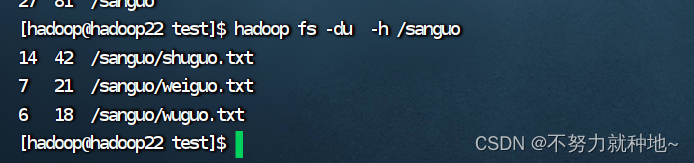
hadoop shell操作 hdfs处理文件命令 hdfs上传命令 hadoop fs -put命令hadoop fs相关命令 hadoop(十三)
hadoop fs -help rm 查看rm命令作用
hadoop fs 查看命令 1. 创建文件夹:
# hdfs前缀也是可以的。更推荐hadoop
hadoop fs -mkdir /sanguo
2.上传至hdfs命令: 作用: 从本地上传hdfs系统 (本地文件被剪切走,不存在了&…
Hadoop --- HDFS配置与操作
hadoop的配置文件存放目录在 {HADOOP_HOME}/etc/hadoop 下, 与 hdfs相关的配置: core-site.xml、hdfs-site.xml
core-site.xml: core-site 配置详解
新增属性信息: fs.defaultFS
fs.defaultFS表示指定集群的文件系统类型是分布…
利用python将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
注意的点 (1)先判断写入的txt文件是否存在,如果不存在就需要创建路径 (2)如果txt文件已经存在,那么先将对应的文件进行…

Hadoop——HDFS、MapReduce、Yarn期末复习版(搭配尚硅谷视频速通)
一、HDFS 1.HDFS概述 1.1 HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自…

HDFS操作实验(hdfs文件上传、使用JavaAPI判断文件存在,文件合并)
此博客为博主学习总结,内容为博主完成本周大数据课程的实验内容。实验内容分为两部分。
1. 在分布式文件系统中创建文件并用shell指令查看;
2. 利用Java API编程实现判断文件是否存在和合并两个文件的内容成一个文件。
感谢厦门大学数据库实验室的实验…
Hadoop的生成经验调优和基准测试
文章目录(1)项目经验之HDFS存储多目录(2)项目经验之集群数据均衡(3)项目经验之Hadoop参数调优(4)项目经验之支持LZO压缩配置(5)项目经验之LZO创建索引&#x…

一个例子带你了解MapReduce
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…
3.HDFS的客户端操作—环境准备(Windows10上安装与配置 Hadoop3.2 环境)、API操作、I/O流操作
本文目录如下:3.HDFS的客户端操作—环境准备、API操作、I/O流操作3.1 HDFS客户端环境准备3.1.1 在Win10上安装Hadoop并配置环境变量3.1.2 创建一个Maven工程Hdfs-0100-HelloWorld3.1.3 导入相应的依赖、配置日志文件3.1.4 创建包名:com.xqzhao.hdfs3.1.5…

Windows 开启 Kerberos 的火狐 Firefox 浏览器访问yarn、hdfs
背景:类型为IPA或者MIT KDC,windows目前只支持 firefoxMIT Kerberos客户端的形式,其他windows端浏览器IE、chrome、edge,没有办法去调用MIT Kerberos Windows客户端的GSSAPI验证方式,所以均无法使用 Windows 开启 Kerb…
Linux服务器搭建单机版Hive与搭建Hive集群
Linux服务器搭建单机版Hive与搭建Hive集群HiveHive概述Hive架构Hive计算引擎Linux安装Hive下载Hive解压及重命名配置hive-env.sh创建hive-site.xml配置日志添加驱动包配置环境变量初始化数据库启动HiveHive的交互方式使用bin/hive使用hiveServer2使用sql语句或者sql脚本Hive集群…

从零开始的Hadoop学习(二)| Hadoop介绍、优势、组成、HDFS架构
1. Hadoop 是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通常是指一个更广泛的概念—Hadoop生态圈。
2. Hadoop 的优势
高可靠性:Hadoop底层维护多…

Hive 中数据仓库默认位置配置及库表关系
1、原始位置的默认配置
hive中的Default(默认)数据仓库的最原始位置是在hdfs上的 /user/hive/warehouse(以下默认Hive的HDFS根目录为/user/hive)路径下,这个原始位置是本地的/usr/local/hive/conf/hive-default.xml.t…
纯手动搭建hadoop集群记录001_搭建虚拟机_调通网络_配置静态IP_安装JDK---大数据之Hadoop3.x工作笔记0162
1.首先准备机器,172.19.126.115 172.19.126.116 172.19.126.117 我准备了3台 Windows机器
2.然后我打算在Windows机器上使用虚拟机,搭建3台Centos虚拟机来进行安装hadoop
3.这里我们的3台windows机器中的,3台linux虚拟机也使用了3个IP,分别是
172.19.126.120 172.19.126.1…

Hadoop之hdfs查看fsimage和edits
/opt/module/hadoop-3.1.3/data/dfs/name/current (1) Fsimage文件: HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。 (2) Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有…

HDFS、MapReduce原理--学习笔记
1.Hadoop框架
1.1框架与Hadoop架构简介
(1)广义解释 从广义上来说,随着大数据开发技术的快速发展与逐步成熟,在行业里,Hadoop可以泛指为:Hadoop生态圈。 也就是说,Hadoop指的是大数据生态圈整…
HDFS配置lzo压缩
参考 https://www.cnblogs.com/caoshouling/p/14091113.html, 做了验证,很好的文档。 1) 停止hdfs集群
2)安装配置maven
https://blog.csdn.net/hailunw/article/details/117996934
3)生成lzo压缩程序包
3.1)安装前…
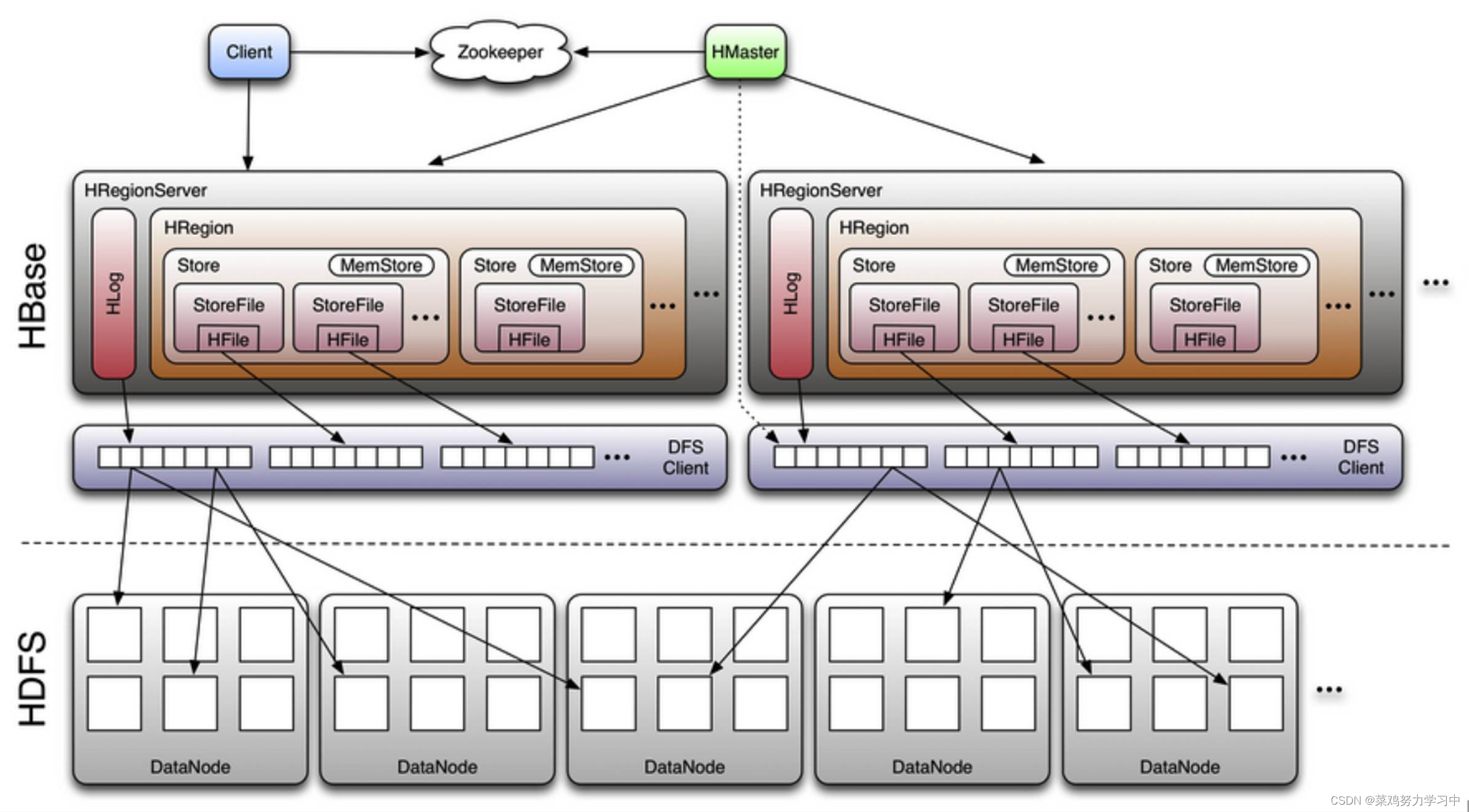
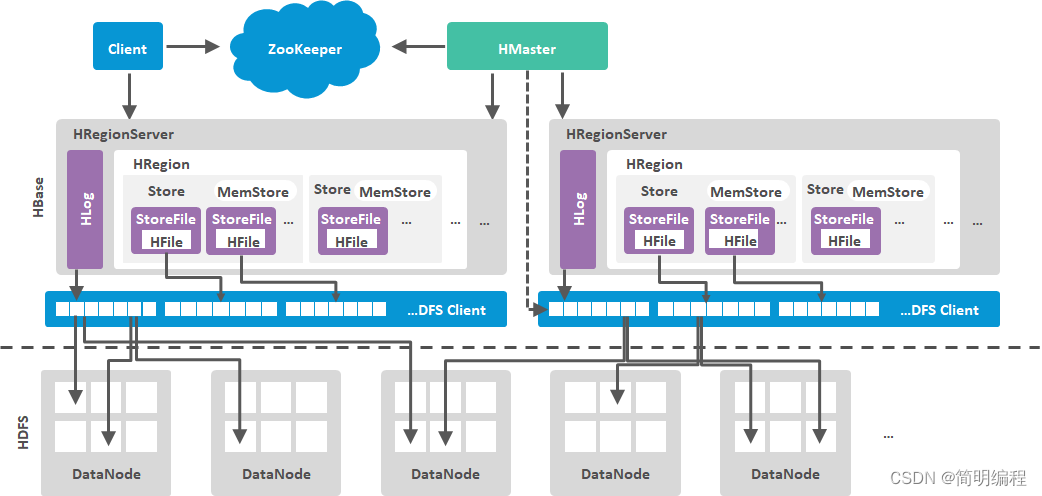
HBase架构中各组件功能及联系
文章目录1. 架构图2. 各组件功能作用1.Client2. zookeeper3. HMaster4. RegionServer5. Hlog6. Region7. Store8. MemStore9. StoreFile10. HFile1. 架构图 2. 各组件功能作用
1.Client 整个HBase集群的访问入口,并维护cache来加快对HBase的访问 使用HBase RPC机制…
hadoop环境新手安装教程
1、资源准备:
(1)jdk安装包:我的是1.8.0_202
(2)hadoop安装包:我的是hadoop-3.3.1
注意这里不要下载成下面这个安装包了,我就一开始下载错了
错误示例: 2、主机网络相…

多次重新初始化hadoop namenode -format后,DataNode或NameNode没有启动
多次重新初始化hadoop namenode -format后,DataNode或NameNode没有启动
在搭建完hadoop集群后,需要对主节点进行初始化(格式化)
其本质是清理和做一些准备工作,因为此时的HDFS在物理上还是存在的。
而且主节点格式化…
HDFS 教程(超详细)
文章目录1. HDFS 介绍1.1 HDFS 背景及定义1.2 HDFS 的优缺点1.3 HDFS 组成架构1.4 HDFS 文件块大小2. HDFS 的 Shell 操作3. HDFS 客户端操作3.1 HDFS 客户端环境准备3.2 HDFS 的 API 操作3.2.1 HDFS 文件上传、下载、删除、更名3.2.2 HDFS 文件详情查看3.2.3 HDFS 文件和文件夹…
20201221linux 启动hbase 脚本
一般,我们启动hbase的步骤是: (1)
./hadoop-2.9.2/sbin/start-all.sh(2) 启动hbase和yarn(先将终端切换到hbase)(其实不需要启动yarn)
./hbase-1.6.0/./bin/start-hbase.sh(3)启动hbase shell
./hbase-1…
基于Linux安装Hive
Hive安装包下载地址
Index of /dist/hive
上传解压
[rootmaster opt]# cd /usr/local/
[rootmaster local]# tar -zxvf /opt/apache-hive-3.1.2-bin.tar.gz重命名及更改权限
mv apache-hive-3.1.2-bin hivechown -R hadoop:hadoop hive配置环境变量
#编辑配置
vi /etc/pro…

![Hadoop中怎么解决Starting secondary namenodes [0.0.0.0]](https://img-blog.csdnimg.cn/20201108204145537.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0MTc2MzQz,size_16,color_FFFFFF,t_70#pic_center)
Hadoop中怎么解决Starting secondary namenodes [0.0.0.0]
对于Ubtuntu安装的Hadoop的补充,安装教程见博客:https://blog.csdn.net/qq_44176343/article/details/106824922 我在安装过程中遇到一个这么的错误,这个问题怎么解决呢? 解决办法: 1.打开用于设置HDFS分布式文件系统…
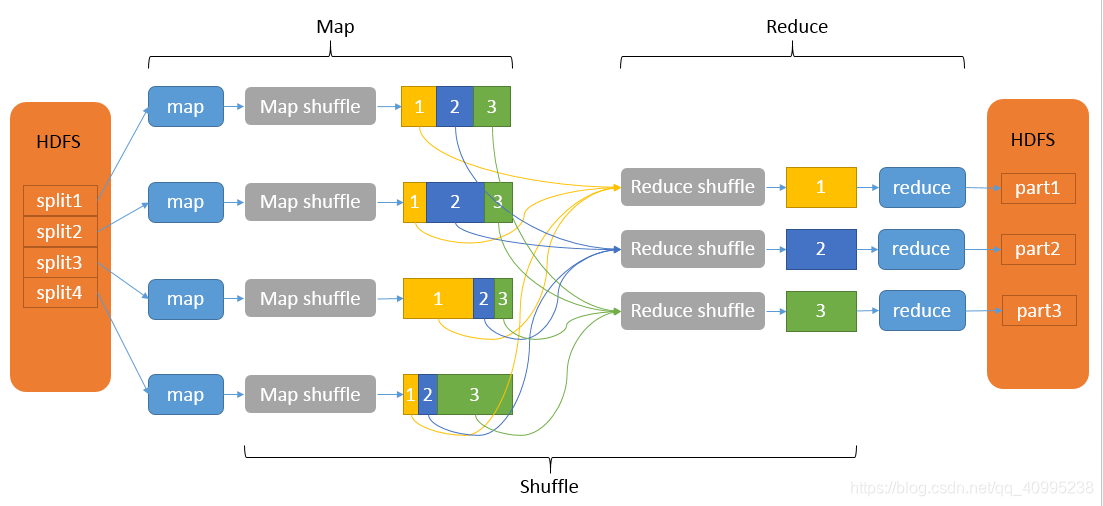
Hadoop基本架构
说说你对集群概念的理解?
集群是多个服务器组成的一个群体,这些服务器做相同类型任务。好比饭店做饭一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系是集群;切菜,备菜࿰…

大数据踩坑合集(三)
大数据踩坑合集(三)之swp交换文件
今天在练习shell脚本时,需要vim一个脚本,修改其中的一个配置,结果vim时出现了下面这种结果: 像我这种身兼几十种强迫症的人怎么可以忍得了呢? 排查之后发现这…
【橋本菜菜子】Linux上搭建Hadoop的常见问题
1.1 引言
之前学云计算的时候只是单纯在实验室操作了一下,很多步骤都忘记了,找攻略的时候也很杂,于是记录最近在自己电脑上搭建Hadoop的时候遇到的一些问题以及相关的解决方案。
在安装Hadoop的同时,我发现hadoop-3.x版本中的ha…

大数据技术原理与应用 复习一 大数据基础+hadoop
大数据概述
1.1 大数据时代 第三次信息化浪潮 2010年前后 解决信息爆炸的问题 原因:存储设备容量不断增加、CPU处理能力大幅提升、网络宽带不断增加 数据产生方式:运营式系统阶段->用户原创内容阶段(web2.0)->感知式系统阶…
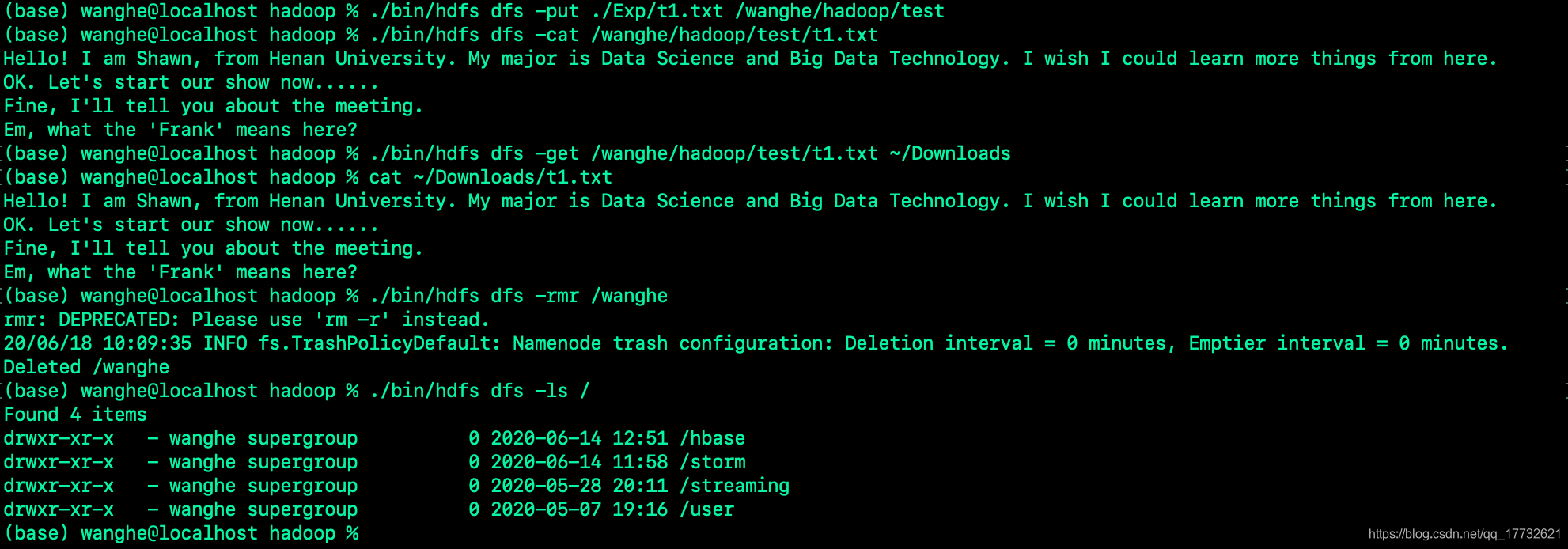
Hadoop学习篇(二)——HDFS实践操作
上篇博客中,我们学习了HDFS的理论基础,了解了HDFS的架构模式,并且是如何进行读写操作的。那么本篇就要开始HDFS的实战操作了。(实战操作将以伪分布式为例)
上篇链接:Hadoop学习篇(二)——HDFS
Hadoop学习…

【hadoop——HDFS操作常用的Shell命令】
1.Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,我们已经安装好了Hadoop 2.7.1,其中已经包含了HDFS组件,不需要另外安装
最基本的shell命令: HDFS既然是Hadoop的组件&…
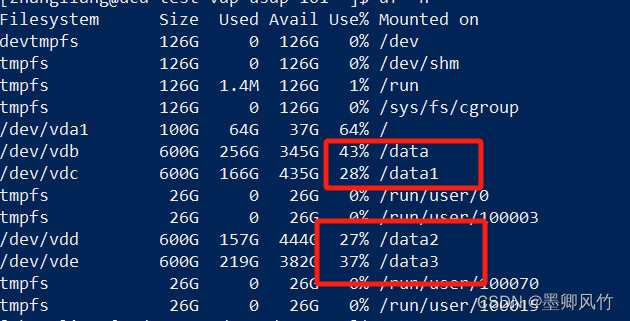
大数据集群增加数据盘,平衡数据盘HDFS Disk Balancer
大数据集群增加数据盘,平衡数据盘HDFS Disk Balancer
官网:https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-hdfs/HDFSDiskbalancer.html hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.jsonhdfs diskbalancer -q…
【HDFS】BlockReceiver#receivePacket方法详解
BlockReceiver#receivePacket:
接收并处理一个packet,这个packet可能包含多个chunks。 返回值是packet的数据字节数。
receivePacket这个方法的代码有250+行。非常长。需要我们去一点一点拆解: private int receivePacket() throws IOException {// 从输入流in里读下一个p…
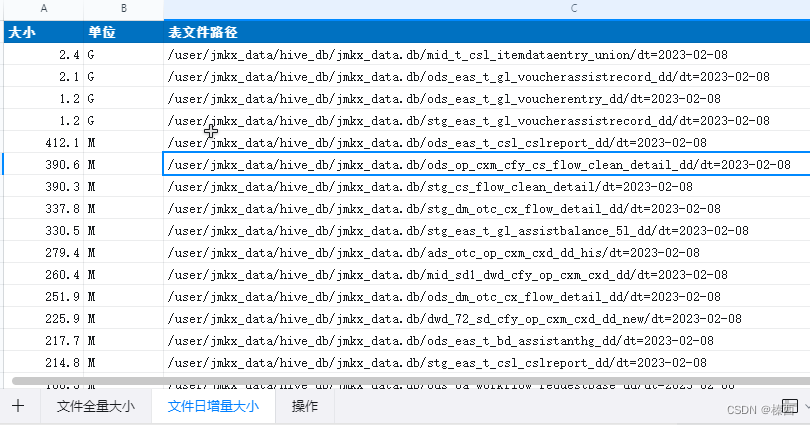
统计hive-hdfs文件大小日常腾出磁盘
1 home目录下 klist -kt hdfs.keytab
2 kinit -kt hdfs.keytab hdfs/p-nc1mutapp02.jemincare.comNC1MUTAPP.JEMINCARE.COM
3 hdfs dfs -du -h /user/jmkx_data/hive_db/jmkx_data.db/ > ./a.txt 全量大小
4 hdfs dfs -du -s -h /user/jmkx_data/hive_db/jmkx_data.db/*/…
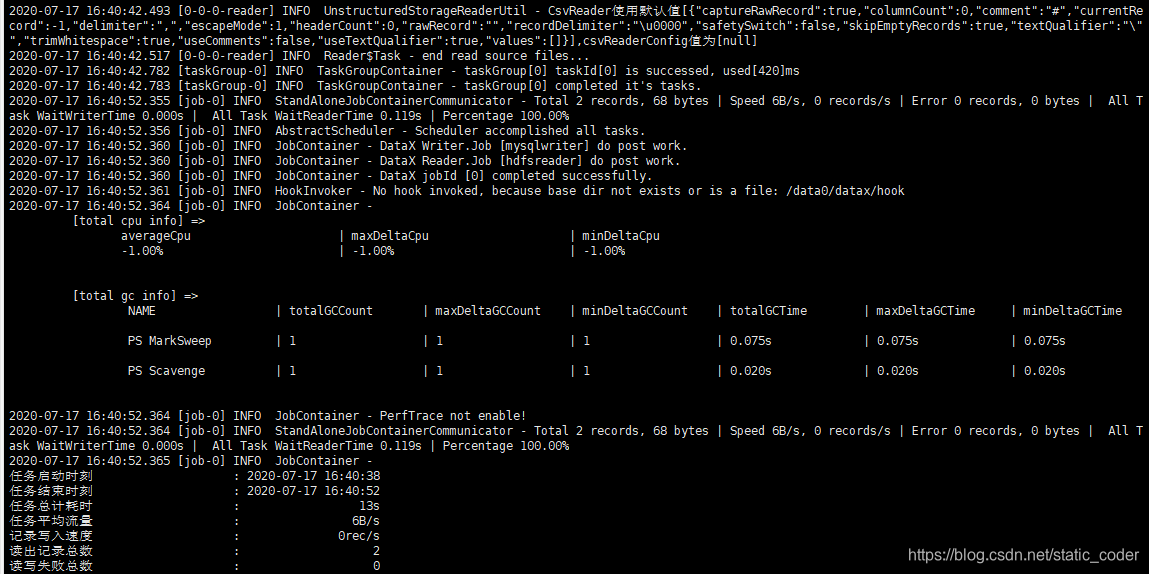
大数据之使用datax完成rds到hdfs,hdfs到rds的导入导出
1、前言 mysql等数据存储技术,随着海量数据的不断增加,已经不能满足正常的业务需求。大数据技术带来的数据仓库为此带来很多解决方案。今天基于京东云的环境简单的搭建一个数据数据仓库,使用阿里出品的datax完成数据的导入和导出。
2、导入导…
pyspark 检测任务输出目录是否空,避免读取报错
前言
在跑调度任务时候,有时候子任务需要依赖前置任务的输出,但类似读取 Parquet 或者 Orc 文件时,如果不判断目录是否为空,在输出为空时会报错,所以需要 check 一下,此外Hadoop通常在写入数据时会在目录中…
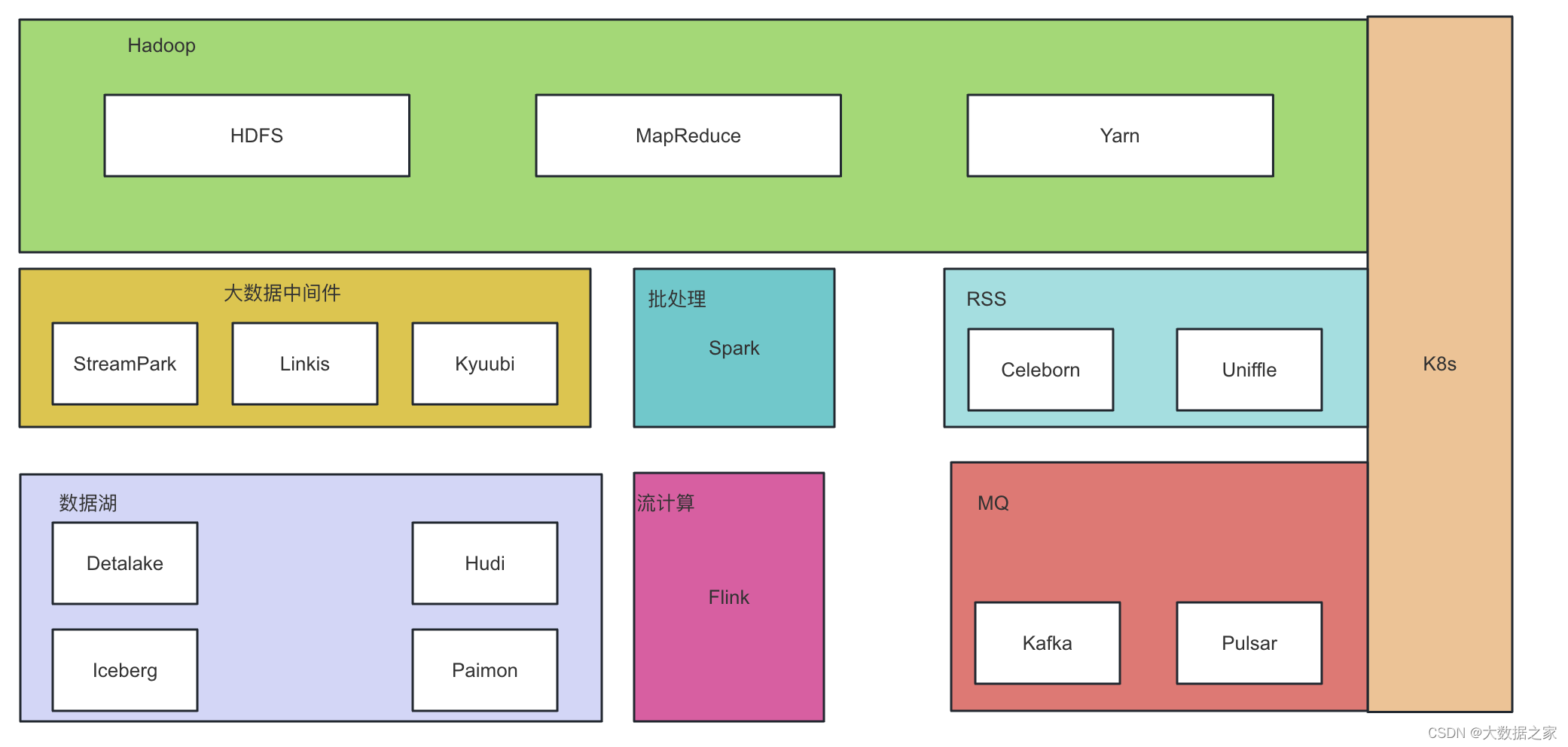
深入浅出hdfs-hadoop基本介绍
一、Hadoop基本介绍
hadoop最开始是起源于Apache Nutch项目,这个是由Doug Cutting开发的开源网络搜索引擎,这个项目刚开始的目标是为了更好的做搜索引擎,后来Google 发表了三篇未来持续影响大数据领域的三架马车论文: Google Fil…

大数据存储与处理技术探索:Hadoop HDFS与Amazon S3的无尽可能性【上进小菜猪大数据】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。
大数据时代带来了数据规模的爆炸性增长,对于高效存储和处理海量数据的需求也日益迫切。本文将探索两种重要的大数据存储与处理技术:Hadoop HDFS和Amazon S3…

1. hadoop环境准备
环境准备
准备三台虚拟机,配置最好是 2C 4G 以上
本文准备三台机器的内网ip分别为
172.17.0.10
172.17.0.11
172.17.0.12本机配置/etc/hosts
cat >> /etc/hosts<<EOF
172.17.0.10 hadoop01
172.17.0.11 hadoop02
172.17.0.12 hadoop03
EOF本机设置与…
使用sqoop操作HDFS与MySQL之间的数据互传
一,数据从HDFS中导出至MySQL中
1)开启Hadoop、mysql进程
start-all.sh/etc/init.d/mysqld start/etc/init.d/mysqld status
2)将学生数据stu_data.csv传到HDFS的/local_student目录下
在hdfs中创建目录
hdfs dfs -mkdir /local_student
上…
Hadoop 集群小文件归档 HAR、小文件优化 Uber 模式
文章目录 小文件归档 HAR小文件优化 Uber 模式 小文件归档 HAR
小文件归档是指将大量小文件合并成较大的文件,从而减少存储开销、元数据管理的开销以及处理时的任务调度开销。
这里我们通过 Hadoop Archive (HAR) 来进行实现,它是一种归档格式…

大数据周会-本周学习内容总结07
目录
01【hadoop】
1.1【编写集群分发脚本xsync】
1.2【集群部署规划】
1.3【Hadoop集群启停脚本】
02【HDFS】
2.1【HDFS的API操作】
03【MapReduce】
3.1【P077- WordCount案例】
3.2【P097-自定义分区案例】
历史总结 01【hadoop】
1.1【编写集群分发脚本xsync】…

2.Hadoop运行模式-本地式、伪分布式 (仅用于测试) | 历史服务器、日志聚集
本文目录如下:Hadoop运行模式-本地式、伪分布式2.本地运行模式2.1 官方Grep案例2.2 官方WordCount案例3 伪分布式运行模式 (仅用于测试)3.1 启动HDFS并运行MapReduce程序3.1.1 配置集群3.1.2 启动集群3.1.3 查看集群3.1.4 操作集群3.2 启动YARN并运行MapReduce程序3…

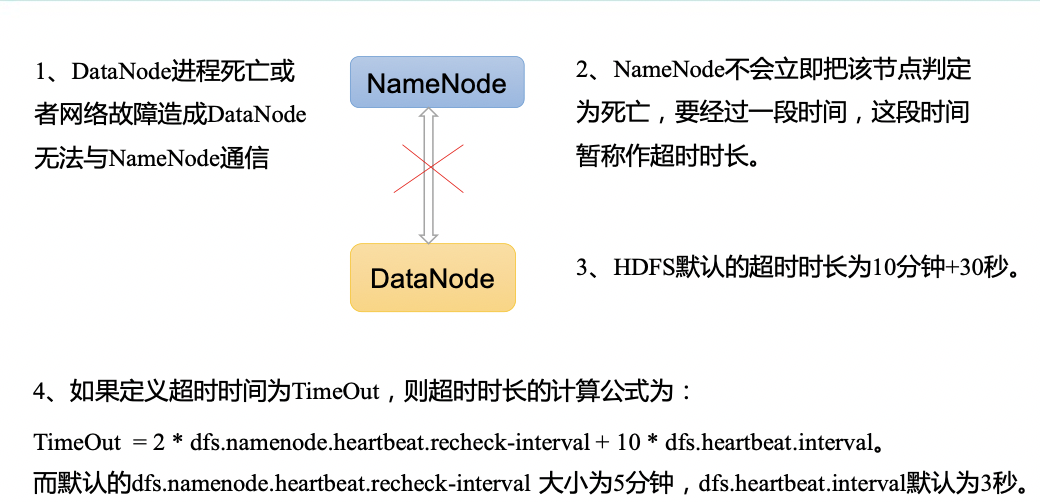
5.DataNode工作机制、数据完整性、数据结点服役退役
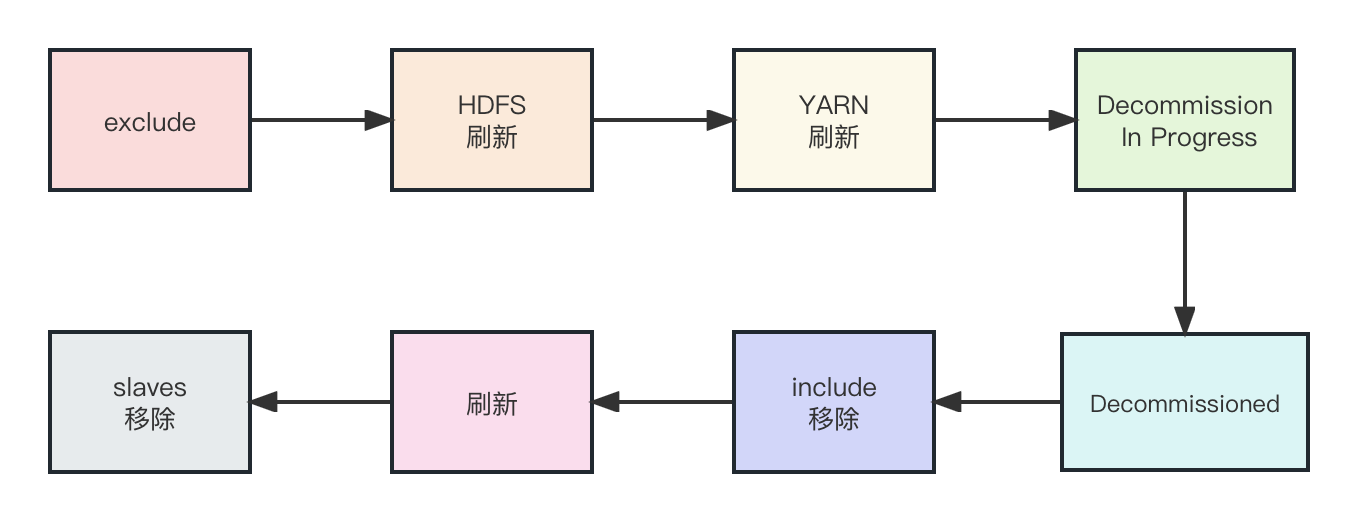
本文目录如下:第9章 DataNode(面试开发重点)9.1 DataNode工作机制9.2 数据完整性9.3 掉线时限参数设置9.4 服役新数据节点9.4.1 环境准备9.4.2 服役新节点具体步骤9.5 退役旧数据节点9.5.1 添加白名单9.5.2 如果数据不均衡,可以用…
在配置HDFS环境时遇到的一些坑
启动datanode、namenode时未启动 使用jps命令查看,未启动datanode,切换到logs目录下,使用tail命令打开刚刚生成的日志查看错误一定要查看配置文件,看看有没有单词拼写错误!!!!克隆的…
flume的配置与安装
一.flume的配置与案例1 下载flume包
http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz1.将压缩包放在ubunta下
cd ~
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C ~ln -s apache-flume-1.8.0-bin/ flumevi ~/.bashrc
source ~/.bashrc…

Chapter2 大数据处理架构Hadoop
2.1 Hadoop简介和版本演变
2.1.1 Hadoop简介
Hadoop是Apache软件基金会旗下开源软件,为用户提供高层接口,为用户提供了底层细节透明的分布式基础架构。 Hadoop是基于java语言开发的,具有很好的跨平台性,但是它支持多种语言&…
【大数据面试题】007 谈一谈 Flink 背压
一步一个脚印,一天一道面试题(有些难点的面试题不一定每天都能发,但每天都会写)
什么是背压 Backpressure
在流式处理框架中,如果下游的处理速度,比上游的输入数据小,就会导致程序处理慢&…

Docker多节点部署Minio分布式文件系统并测试
文章目录 一、前提准备二、文件配置1. .env2. env/minio.env3. docker-compose-minio.yml 三、测试四、Java测试1. 引入依赖2. 增删改 一、前提准备
准备如下文件夹和文件
./
├── docker-compose-minio.yml
├── .env
├── env
│ ├── minio.env
├── minio
│…
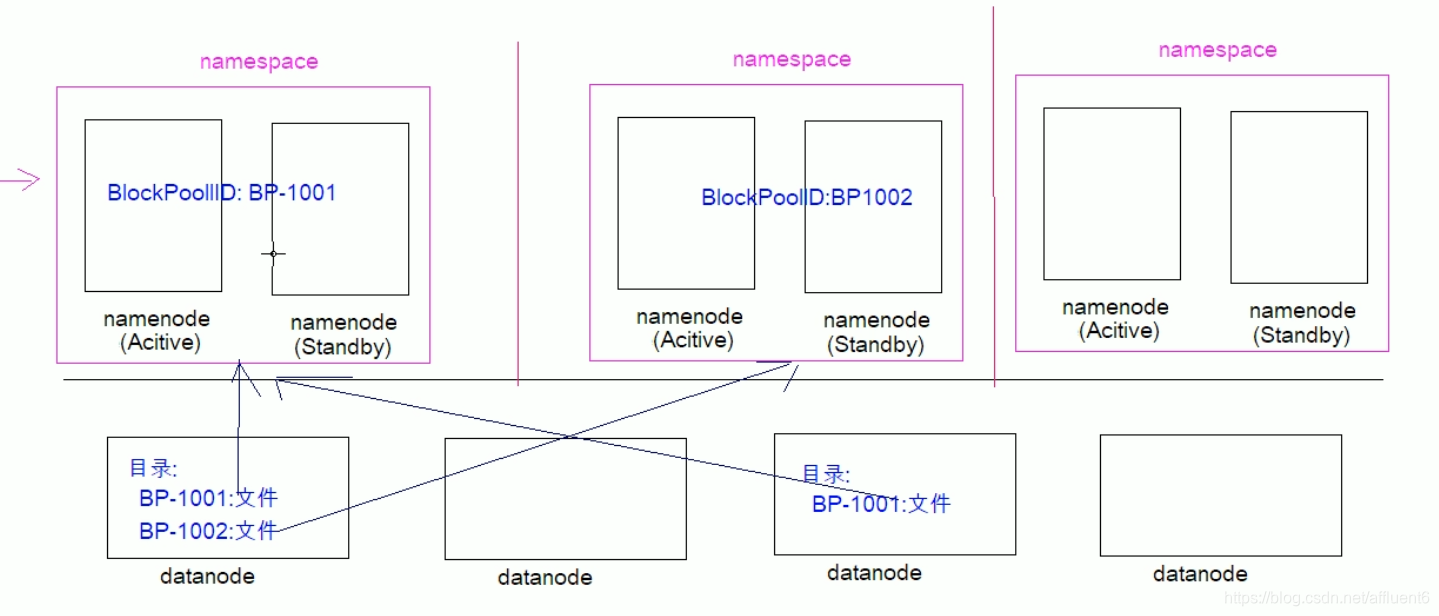
4.HDFS的高可用机制、联邦机制
本文目录如下:7 HDFS的高可用机制7.1 HDFS高可用介绍7.2 组件介绍7.3 高可用机制-工作原理7.4 分布式环境搭建8 HDFS的联邦机制8.1 背景概述8.2 Federation架构设计7 HDFS的高可用机制
7.1 HDFS高可用介绍
在Hadoop中,NameNode所处的位置是非常重要的&…
HDFS读写数据流程和NameNode工作机制
HDFS文件系统写数据
1.步骤
文件上传步骤:
向NameNode请求上传文件文件路径(验证请求身份,写权限)响应可以上传文件请求上传第一个Block(0-128M), 请返回DataNode返回dn1,dn2,dn3节点,表示采用这三个节点存储数据
NameNode节点选择存储节…
通信协议 远程调用RPC
1.通讯协议 所有的HDFS通讯协议都是建立在TCP/IP协议之上。 客户端通过一个可配置的TCP端口连接到Namenode,通过ClientProtocol协议与Namenode交 互。而Datanode使用DatanodeProtocol协议与Namenode交互。 一个远程过程调用(RPC)模型被抽象出来封装ClientProtoc…

mac系统上hdfs java api的简单使用
文章目录1、背景2、环境准备3、环境搭建3.1 引入jar包3.2 引入log4j.properties配置文件3.3 初始化Hadoop Api4、java api操作4.1 创建目录4.2 上传文件4.3 列出目录下有哪些文件4.4 下载文件4.5 删除文件4.6 检测文件是否存在5、完整代码1、背景
在上一节中,我们简…
2024.1.5 Hadoop各组件工作原理,面试题
目录 1 . 简述下分布式和集群的区别
2. Hadoop的三大组件是什么?
3. 请简述hive元数据服务配置的三种模式?
4. 数据库与数据仓库的区别?
5. 简述下数据仓库经典三层架构?
6. 请简述内部表和外部表的区别?
7. 简述Hive的特点,以及Hive 和RDBMS有什么异同
8. hive中无…
HDFS中dfsadmin命令的使用
在hadoop中,管理员可以通过dfsadmin管理HDFS,常用的两个命令如下:
-report 显示文件系统的基本数据
-safemode 维护HDFS的安全模式

Hadoop3教程(三十五):(生产调优篇)HDFS小文件优化与MR集群简单压测
文章目录 (168)HDFS小文件优化方法(169)MapReduce集群压测参考文献 (168)HDFS小文件优化方法
小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度…
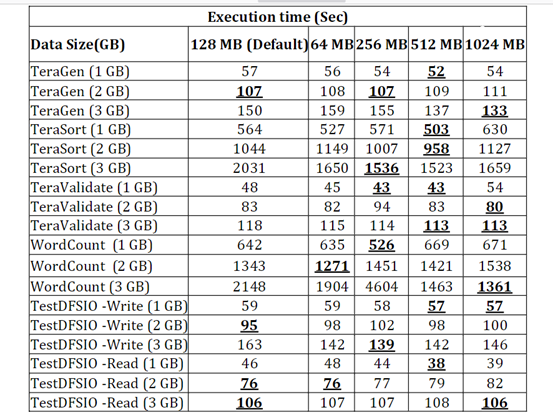
一百五十九、Kettle——Kettle9.2通过配置Hadoop clusters连接Hadoop3.1.3(踩坑亲测、附流程截图)
一、目的
由于kettle的任务需要用到Hadoop(HDFS),所以就要连接Hadoop服务。
之前使用的是kettle9.3,由于在kettle新官网以及博客百度等渠道实在找不到shims的驱动包,无奈换成了kettle9.2,kettle9.2的安装…
面试官把我问懵了....
感谢兄弟们的关注与支持,如果觉得有帮助的话,还请来个点赞、收藏、转发三操作
该文章已更新到语雀中,后台回复“语雀”可获取公众号:进击吧大数据整个职业生涯持续更新的所有资料
在前面介绍了Hadoop三部曲搞起~,简单…
大数据中的分布式文件系统HDFS的选择题
一. 单选题(共10题,50分)
(单选题)分布式文件系统指的是什么? A. 把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群 B. 用于在Hadoop与传统数据库之间进行数据传递 C. 一个高可用的,高可靠的,分布式的海量日志采集、聚…
【HDFS】ActiveNamenodeResolver#getNamespaces 方法调用点梳理
获取所有的注册在router里的active状态的集群。 /*** Get a list of all namespaces that are registered and active in the* federation.** @return List of name spaces in the federation* @throws IOException Throws exception if the namespace list is not* av…
专利引用关系数据集分析
专利引用关系数据集分析这次实验的两个题目,一个可以由词频统计代码改编,一个由倒排索引改编,改编的重点是将每一排的两个输入分开。 输出专利被引用次数统计结果: 根据题目要求需要输出被引用的专利和它的次数,在word…

【Hadoop】三分钟快速了解Hadoop
一Hadoop初见
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。Hadoop的核心是:分布式文件系统HDFS 分布式计算模型MapReduceHadoo…
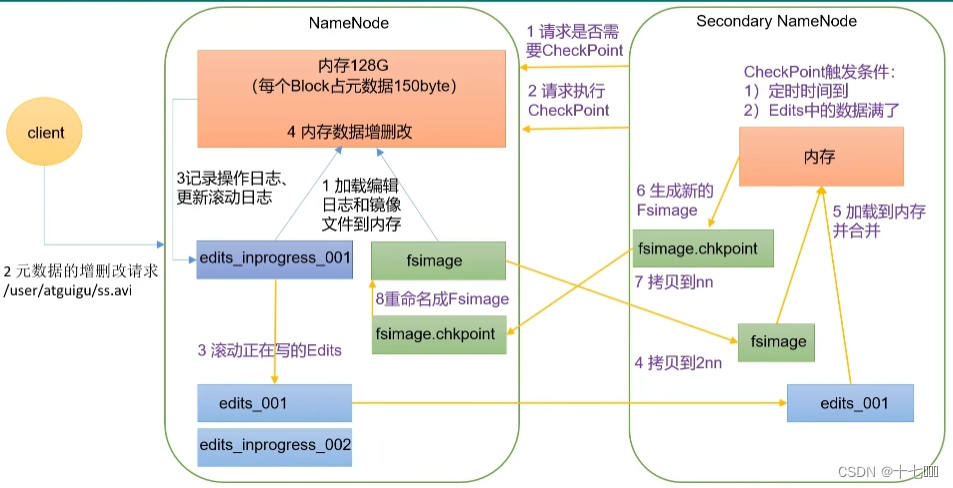
2.HDFS文件读写过程、元数据管理-Fslmage和Edits详解 、SecondaryNameNode详解
本文目录如下:3 HDFS的文件写入过程4 HDFS的文件读取过程5 HDFS的元数据管理5.1 Fslmage和Edits详解5.1.1 fsimage中的文件信息查看5.1.2 edits中的文件信息查看5.2 SecondaryNameNode详解5.2.1SecondaryNameNode如何辅助管理fsimage与edits文件?。5.3 NameNode故障…
校招面试重点汇总之Hadoop中的HDFS(不多但都是高频面试题)
一、介绍下什么是 HDFS(Hadoop Distributed File System)?它的特点是什么?
Hadoop Distributed File System(HDFS)是Apache Hadoop生态系统的一个核心组件,是一个可扩展的分布式文件系统&#…
《Hadoop技术内幕:深入解析Hadoop和HDFS》一、1.1什么是Hadoop
数据!数据!数据!
今天,我们正被数据包围。全球 43 亿部电话、20 亿位互联网用户每秒都在不断地产生
大量数据,人们发送短信给朋友、上传视频、用手机拍照、更新社交网站的信息、转发微
博、点击广告等,使…
Hadoop3.0大数据处理学习2(HDFS)
一、简介
HDFS:Hadoop Distributed File System。Hadoop分布式存储系统 一种允许文件通过网络在多台主机上分享的文件系统,可以让多机器上的用户分享文件和存储空间。 两大特性:通透性、容错性
分布式文件管理系统的实现很多,HD…
HDFS的Shell操作与API操作
HDFS的Shell操作与API操作 1、HDFS的Shell操作 1.1、基本语法1.2、上传1.3、下载1.4、HDFS 直接操作 2、HDFS的API操作 2.1、获取文件系统2.2、javaAPI操作HDFS
1、HDFS的Shell操作
1.1、基本语法
hadoop fs 具体命令hdfs dfs 具体命令 具体命令 [-appendToFile … ] [-ca…
Pig-使用PigLatin操作员工表和部门表
前提条件: 安装好hadoop2.7.3(Linux系统下) 安装好pig(Linux系统下)
准备源数据:
打开终端,新建emp.csv文件
$ nano emp.csv输入内容如下,保存退出。
7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,198…

【大数据】图解 Hadoop 生态系统及其组件
图解 Hadoop 生态系统及其组件 1.HDFS2.MapReduce3.YARN4.Hive5.Pig6.Mahout7.HBase8.Zookeeper9.Sqoop10.Flume11.Oozie12.Ambari13.Spark 在了解 Hadoop 生态系统及其组件之前,我们首先了解一下 Hadoop 的三大组件,即 HDFS、MapReduce、YARN࿰…
Hadoop 怎么委任和解除节点?
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 正文 Hadoop 集群的管理员经常需要向集群中添加节点…

基于Hadoop的豆瓣电影的数据抓取、数据清洗、大数据分析(hdfs、flume、hive、mysql等)、大屏可视化
目录 项目介绍研究背景国内外研究现状分析研究目的研究意义研究总体设计数据获取网络爬虫介绍豆瓣电影数据的采集 数据预处理数据导入及环境配置Flume介绍Hive介绍MySQL介绍Pyecharts介绍环境配置及数据加载 大数据分析及可视化豆瓣影评结构化分析豆瓣电影类型占比分析豆瓣电影…


基于Flink实时数仓——DWS 层-商品主题宽表的计算(7)
代码实现:
public class ProductStatsApp {public static void main(String[] args) throws Exception {//TODO 1.获取执行环境StreamExecutionEnvironment env StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//1.1 设置CK&状…
修炼k8s+flink+hdfs+dlink(一:安装hdfs)
一:安装jdk,并配置环境变量。
在对应的所有的节点上进行安装。
mkdir /opt/app/java
cd /opt/app/java
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24http%3A%2F%2Fwww.oracle.com%
2F; oraclelicenseaccept-securebackup…
安装和使用分布式HDFS系统在CentOS 8上进行文件上传操作
文章目录 实验目的和背景实验目的实验背景 实验过程步骤1:安装Java步骤2:下载hadoop-3.3.1.tar.gz步骤3:创建一个普通用户来运行Hadoop Hadoop 概念Hadoop 整体设计HDFSHDFS 的节点命名节点 (NameNode)数据节点 (DataNode)副命名节点 (Second…

hdfs删除后空间不是释放,trash回收机制
一、现象 hdfs删除后,3天了还不删除,故排查排查问题 二、排查过程及原理 Trash机制,叫做回收站或者垃圾桶,默认情况下是不开启的。启用 Trash 功能后,从 HDFS 中删除某些内容时,文件或目录不会立即被清除&a…
2.2 HDFS shell操作
2.2 HDFS shell操作 调用文件系统(FS)Shell命令应使用 bin/hadoop fs 的形式 ls 使用方法:hadoop fs -ls 如果是文件,则按照如下格式返回文件信息: 文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID 如果是目录ÿ…
HDFS多文件Join操作
最近在用Java做HDFS文件处理之时,遇到了多文件Join操作,其中包括:All Join以及常用的Left Join操作,
下面是个简单的例子;采用两个表来做left join其中数据结构如下:
A 文件:
a|1b|2|c
B文件…

HDFS入门笔记------架构以及应用介绍
引言—HDFS的重要性: Hadoop的定义:适合大数据的分布式存储与计算的一个平台,其中大数据的分布式存储就是由HDFS来完成的,因此掌握好HDFS的相关概念与应用非常重要! 本篇博客将从以下几个方面讲述HDFS: 1、…
Hadoop学习篇(二)——HDFS编程操作1
在前两篇文章中,我们已经介绍了HDFS的理论基础以及命令行的基本操作。
但是,在实际中我们使用HDFS的平台时,是不可能全部进行命令行操作的。一定是要与编程结合起来进行的。所以,本篇将介绍HDFS相关的一些编程操作。
上篇链接&a…

2023.11.14-hive的类SQL表操作之,4个by区别
目录 1.表操作之4个by,分别是
2.Order by:全局排序
3.Cluster by
4.Distribute by :分区
5. Sort by :每个Reduce内部排序
6.操作练习
步骤一.创建表
步骤二.加载数据 步骤三.验证数据 1.表操作之4个by,分别是
order by 排序字段名
cluster by 分桶并排序字段名
dis…
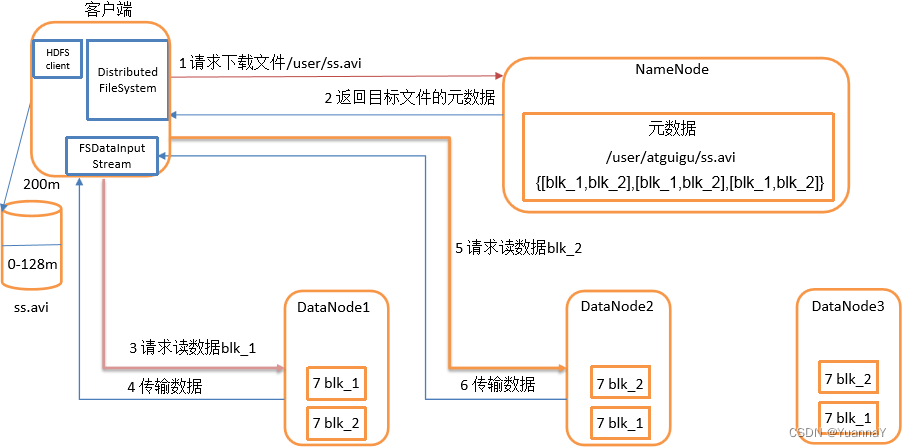
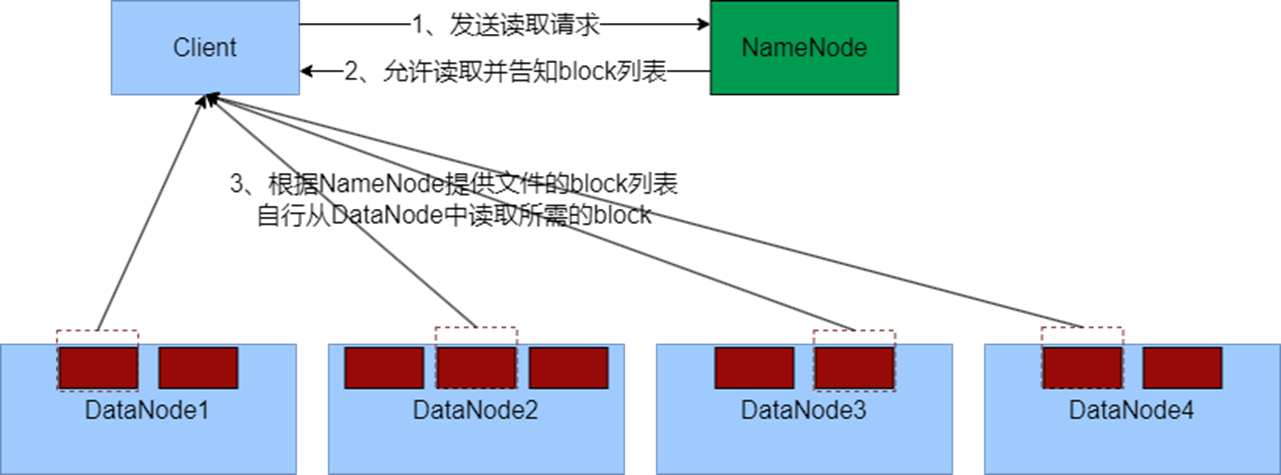
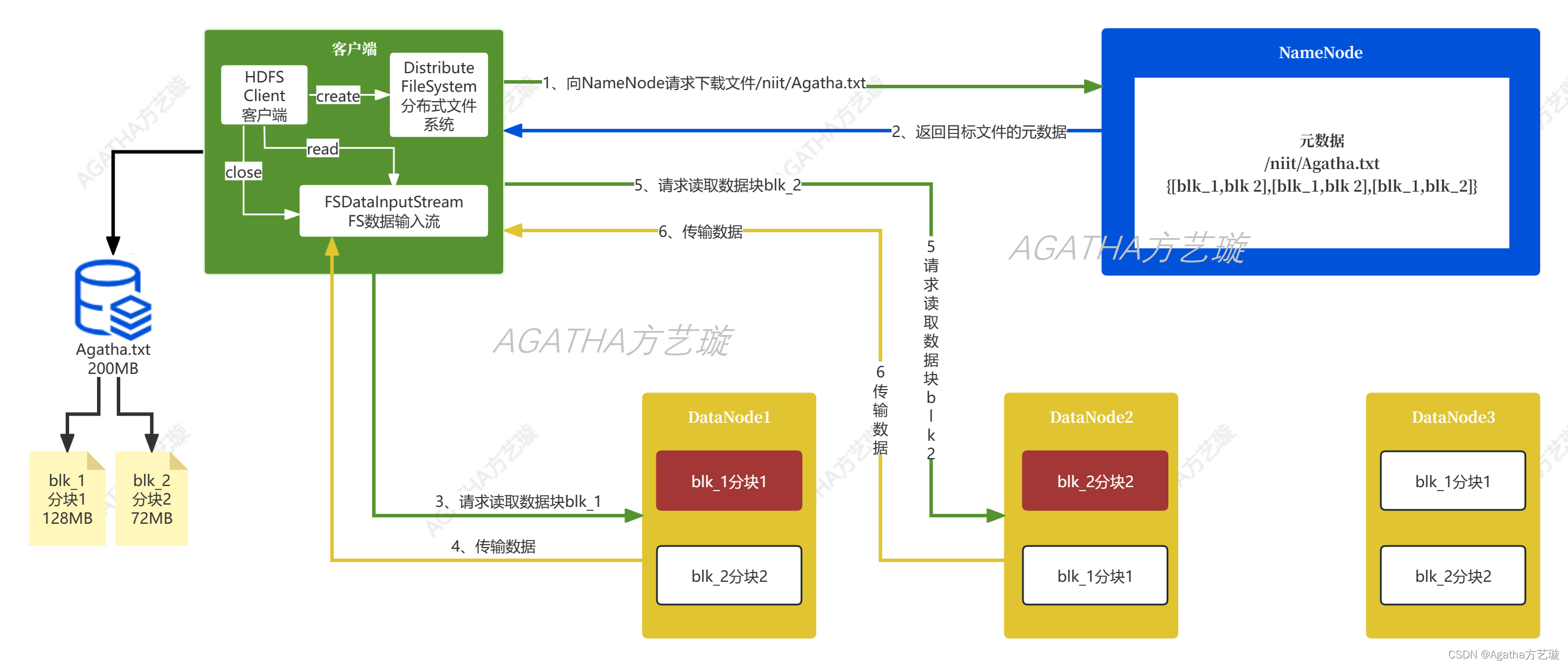
hdfs的读写数据流程
读: (1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机&…

Hadoop-02(HDFS)
文章目录第1章 HDFS概述1.1 HDFS产出背景及定义1.2 HDFS优缺点1.3 HDFS组成架构第2章 HDFS的Shell操作(开发重点)1. 基本语法2. 命令大全3. 常用命令实操第3章 HDFS客户端操作(开发重点)3.1 HDFS客户端环境准备3.2 HDFS的API操作3…
Flume多进程传输
1.Flume介绍
Flume 是一种分布式、可靠且可用的服务,用于高效收集、聚合和移动大量日志数据。它具有基于流数据流的简单而灵活的架构。它具有鲁棒性和容错性,具有可调的可靠性机制和许多故障转移和恢复机制。它使用简单的可扩展数据模型,允许…
Kafka数据到Hdfs
找时间总结整理了下数据从Kafka到Hdfs的一些pipeline,如下
1> Kafka -> Flume –> Hadoop Hdfs
常用方案,基于配置,需要注意hdfs小文件性能等问题.
GitHub地址: https://github.com/apache/flume
2> Kafka -> Kafka Hadoop Loader ->Hadoop …
HDFS的命令行操作
在成功部署Hadoop的基础上
创建目录
语法:hadoop fs -mkdir <目录名/路径>
hadoop fs -mkdir /user/hadoop
hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2查看列表文件
语法:hadoop fs -ls <参数>
hadoop fs -ls /user/hadoop…
hadoop 3.3大数据集群搭建系列1-安装hadoop
文章目录一. 软硬件配置1.1 主机配置及规划1.2 软件配置1.3 安装常用的工具二. 安装前准备2.1 设置主机名2.2 设置hosts2.3 关闭防火墙2.4 ssh免密登陆2.5 ntpdate时间同步三. 安装3.1 安装hadoop3.1.1 下载hadoop并解压3.1.2 配置hadoop_home环境变量3.1.3 编辑etc/hadoop/had…
HDFS WebHDFS 读写文件分析及HTTP Chunk Transfer Coding相关问题探究
文章目录 前言需要回答的问题DataNode端基于Netty的WebHDFS Service的实现 基于重定向的文件写入流程写入一个大文件时WebHDFS和Hadoop Native的块分布差异 基于重定向的数据读取流程尝试读取一个小文件尝试读取一个大文件 读写过程中的Chunk Transfer-Encoding支持写文件使用C…
HDFS HA 集群搭建 - 基于Quorum Journal Manager(hadoop2.7.1)
0、前置概念
0.1 checkpoint 检查点
在Hadoop分布式文件系统(HDFS)中,检查点(Checkpointing)是一个关键的过程,它涉及到将文件系统的命名空间状态持久化到磁盘。这个状态由两部分组成:EditLogs和FsImage。 EditLogs:记录了自FsImage生成后对文件系统所做的所有修改。…

Linux使用Eclipse编写WordCount时没有out结果
创作不易,转载请注明出处 文章目录一、报错信息二、原因分析三、解决方法另附一、报错信息
2020-12-05 18:22:17,680 WARN util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... usi…
利用Spark解析Tomcat日志,并将统计结果存入Mysql数据库
本文试图实现的需求场景为:以学习Spark知识点为目的,编写Scala利用Spark解析800M的tomcat日志文件,打印一段时间内ERROR级别记录的前10行,统计每分钟的日志记录数,并将统计结果存入mysql数据库中。之前曾用JAVA写过一次…
![[AIGC 大数据基础] 浅谈hdfs](https://img-blog.csdnimg.cn/img_convert/19fb698dcd7bf051b8d1a057ce063c81.jpeg)
[AIGC 大数据基础] 浅谈hdfs
HDFS介绍 什么是HDFS?
HDFS(Hadoop Distributed File System)是Apache Hadoop生态系统的一部分,是一个分布式文件系统。它被设计用于存储和处理大规模数据集,并且能够容错、高可靠和高性能地处理文件。
HDFS是为了支…

【Hadoop】 | 搭建HA之报错锦集
知识目录 一、写在前面✨二、Hadoop的active结点无法主备切换🔥三、Hadoop Web端无法上传文件🍉四、hdfs创建文件夹报错🍭五、IDEA操作Hdfs无法初始化集群🔥六、Java无法连接Hdfs🍭七、找不到Hadoop家目录🔥…
「大数据-2.0」安装Hadoop和部署HDFS集群
目录 一、下载Hadoop安装包 二、安装Hadoop 0. 安装Hadoop前的必要准备 1. 以root用户登录主节点虚拟机 2. 上传Hadoop安装包到主节点 3. 解压缩安装包到/export/server/目录中 4. 构建软链接 三、部署HDFS集群 0. 集群部署规划 1. 进入hadoop安装包内 2 进入etc目录下的hadoop…
【HDFS】ListenableFuture在HDFS中的应用
AsyncLogger、QuorumCall IPCLoggerChannel(它是AsyncLogger的子类)
一、ListenableFuture的基本使用
ListenableFuture 是 Guava 库中提供的一个接口,它扩展了 JDK 中的 Future 接口,并添加了异步任务完成后的回调机制。
ListenableFuture 提供了以下功能: 异步任务的…
【大数据】HDFS的使用与集群角色(学习笔记)
一、HDFS Shell
1、介绍
命令行界面(CLI)是指用户通过键盘输入指令,计算机接收到指令后,予以执行一种人际交互方式。
Hadoop提供了文件系统的shell命令行客户端
hadoop fs [generic options]2、文件系统协议
HDFS Shell CLI支…
(五)HDFS容错机制
设置
关键性的参数 replication factor(复制因子),是每个block要复制几份副本到其他的机器上去,如果某台机器挂了,其他机器上有一模一样的block副本。这个replication factor可以整体设置一下,也可以对每个文件设置一下,后续还可以修改
过程
写文件的时候,假如说默…
hadoop入门两道面试题
1.常用端口号 hadoop3.x HDFS NameNode 内部常用端口:8020/9000/9820 HDFS NameNode 对用户的查询端口:9870 Yarn查看任务运行情况的端口:8088 历史服务器:19888 hadoop2.x HDFS NameNode 内部常用端口:8020/9000 HDFS…
【大数据技术Hadoop+Spark】HDFS Shell常用命令及HDFS Java API详解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~ 一、HDFS的Shell介绍
Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。
文件系统…
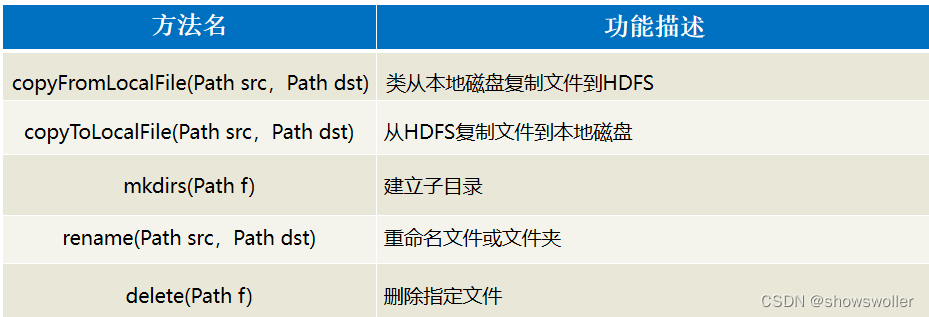
三表相连 mapjoin
三表相连 mapjoin要求输出的样式三张表score.csvstudent.csvsubject.csv创建三个类StudentScgetset方法实现类MapJoinDriver用mapjoin不需要reduceMapJoinMapper运行结果要求
输出的样式 三张表 score.csv student.csv subject.csv 创建三个类 StudentSc getset方法
插入gets…
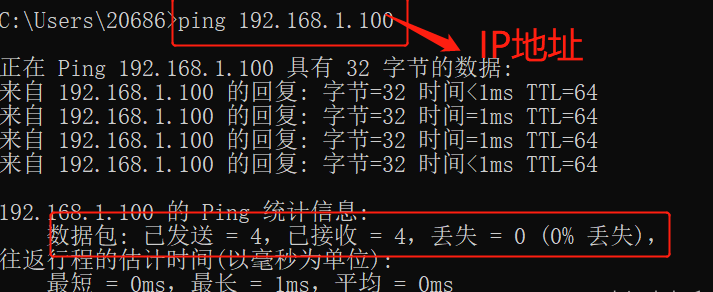
Hadoop环境搭建(1)
一、在已安装的虚拟机上面进行修改(以CentOS 7为例)①修改主机名查看自己主机名,命令hostname第一种修改主机名方法,命令vi /etc/hostname第二种修改主机名方法,命令hostnamectl set -hostname 自定义主机名可以更改为…
hadoop-hdfs简介及常用命令详解(超详细)
文章目录 前言一、HDFS概述1. HDFS简介2. HDFS架构3. HDFS文件操作 二、HDFS命令介绍1. hdfs命令简介2. HDFS命令的基本语法3. 常用的HDFS命令选项 三、HDFS常用命令1. 列出指定路径下的文件和目录。2. 创建一个新的目录。3. 将本地文件或目录上传到 HDFS。4. 从 HDFS 下载文件…
【Hadoop-HDFS-S3】HDFS 和存储对象 S3 的对比
【Hadoop-HDFS-S3】HDFS 和存储对象 S3 的对比 1)可扩展性2)数据的高可用性3)成本价格4)性能表现5)数据权限6)其他限制 虽然 Apache Hadoop 以前都是使用 HDFS 的,但是当 Hadoop 的文件系统的需…
[spark] 存储到hdfs时指定分区
在 SparkSQL 中指定多个分区字段进行数据存储: 类似hive 分区存储 文章目录 代码示例 代码
import org.apache.spark.sql.SparkSessionval spark SparkSession.builder().appName("MultiPartitionedWriteExample").getOrCreate()// 假设你有一个 DataFr…
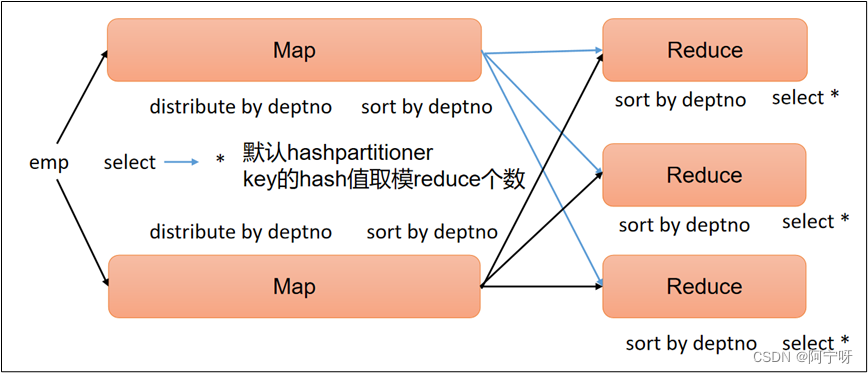
【大数据之Hive】十二、Hive-HQL查询之分组、join、排序
一、分组
1 group by 语句 group by 通常和聚合函数一起使用,按照一个或多个列的结果进行分组,任何对每个租执行聚合操作。 用group by时,select中只能用在group by中的字段和聚合函数。
--计算emp每个部门中每个岗位的最高薪水&#x…
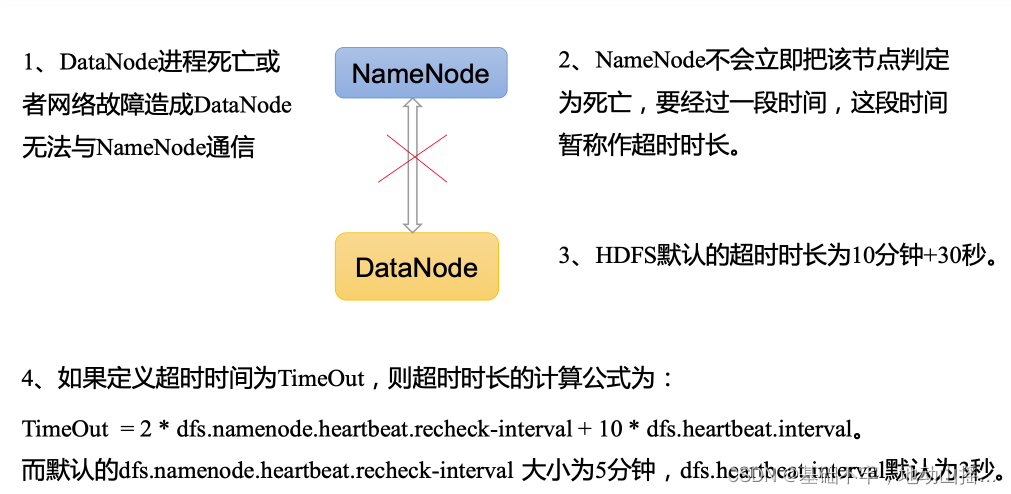
Hadoop之HDFS
目录
1.HDFS概述
1.1HDFS产出背景及定义
1.2 HDFS优缺点
1.3 HDFS组成架构
1.4 HDFS文件块大小
2. HDFS的Shell操作
2.1 基本语法
2.2 命令大全
2.3 常用命令实操
2.3.1 准备工作
2.3.2 上传
2.3.3 下载
2.3.4 HDFS直接操作
3. HDFS的API操作
3.1 客户端环境准备…

(三)HDFS架构原理
目录 架构图
Datanode 从节点(slave)
元数据(Metadata)
元数据信息持久化
Block 架构图 Namenode 主节点(master)
管理HDFS文件系统的命名空间,维护元数据信息, 处理客户端读写请求
Datanode 从节点(slave)
存储数据(Block)…

Hive:从HDFS回收站恢复被删的表
场景 一张手工维护的内部表,本来排查没有使用,然后删掉了,发现又需要使用,只能恢复这张表了。
1.确认HDFS是否开启回收站功能 2.查看回收站中的数据
被删除的数据会放在删除数据时使用的用户目录下,如:使…
Hadoop3教程(二):HDFS的定义及概述
文章目录 (40)HDFS产生的背景和定义(41)HDFS的优缺点(42)HDFS组成架构(43)HDFS文件块大小(面试重点)参考文献 (40)HDFS产生的背景和定…

hdfsClient_java对hdfs进行上传、下载、删除、移动、打印文件信息尚硅谷大海哥
Java可以通过Hadoop提供的HDFS Java API来控制HDFS。通过HDFS Java API,可以实现对HDFS的文件操作,包括文件的创建、读取、写入、删除等操作。 具体来说,Java可以通过HDFS Java API来创建一个HDFS文件系统对象,然后使用该对象来进…
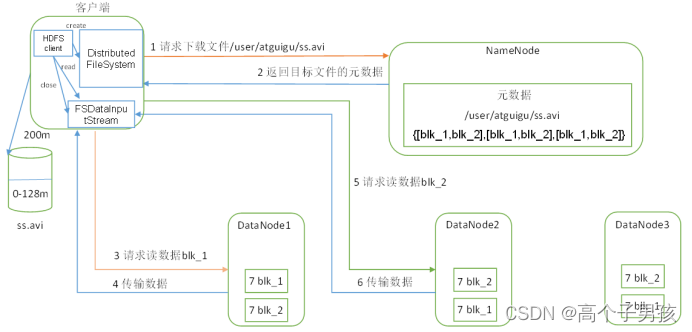
【大数据】HDFS管理员命令行(Administration Commands)详细使用说明
Administration Commands 概览命令详解balancercacheadmincryptodatanodedfsadmindfsrouterdfsrouteradmindiskbalancerechaadminjournalnodemovernamenodenfs3portmapsecondarynamenodestoragepolicieszkfc)概览
所有的HDFS命令都是执行bin/hdfs脚本,当执行此脚本…
Hive建表高阶语句
CTAS -as select方式建表CREATE TABLE ctas_employee as SELECT * FROM employee;CTE (CTAS with Common Table Expression)CREATE TABLE cte_employee AS
WITH
r1 AS (SELECT name FROM r2 WHERE name Michael),
r2 AS (SELECT name FROM employee WHERE gender Male),
r3 …

Flume多路复用模式把接收数据注入kafka 的同时,将数据备份到HDFS目录
启动hadoop、在hdfs中创建需要访问的目录配置Hadoop的核心配置文件core-site.xml:设置Hadoop的核心配置参数,例如NameNode的地址、数据块大小、副本数量等。示例配置如下:<configuration><property><name>fs.defaultFS<…
Hadoop场景案例参数调优
目录
1 需求
2 HDFS参数调优
(1)修改:hadoop-env.sh
(2)修改hdfs-site.xml
(3)修改core-site.xml
(4)分发配置
3 MapReduce参数调优
(1)修…
大数据3 -Hadoop HDFS-分布式文件系统
目录
1.为什么需要分布式存储?
2. HDFS的基础架构
3. HDFS存储原理
4. NameNode是如何管理Block块的
5. HDFS数据的读写流程 1.为什么需要分布式存储? •数据量太大,单机存储能力有上限,需要靠数量来解决问题•数量的提升带…
Fix potential FSImage corruption.
HDFS 添加 降级所需代码分析 背景
Namenode从 hadoop 3.3.4 降级回公司版本会出现 NameNode不能启动,加载image出现遗产,
基础知识 位域"或"位字段
将一个Interger 按二进制数位不同区域表示不同信息的方法,通常被称为"位域…

大数据:Shell的操作
文章目录HDFS常用命令一、创建目录1、创建单层目录2、创建多层目录查看目录三、上传本地文件到HDFS四、查看文件内容五、下载HDFS文件到本地六、删除HDFS文件七、删除HDFS目录HDFS常用命令
启动Hadoop集群命令:start-all.sh
一、创建目录
1、创建单层目录
命令…
【大数据入门核心技术-Hbase】(二)HBase数据模型
目录
一、NameSpace
二、Region
三、Row
四、Column
五、Cell
六、RowKey
七、Store
八、TimeStamp 一、NameSpace 命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase 有两个自带的命名空间,分别是 hbase…
一百零八、Kettle采集Kafka数据到HDFS(踩坑,亲测有效)
Kafka到HDFS,除了用Kafka API和flume之外,还可以用kettle,最大优点是不用写代码!
版本:Kettle版本:8.2、Hadoop版本:3.1.3
前提: 详情请看鄙人的一百零一、Kettle8.2.0连接Hive…

大数据面试题集锦-Hadoop面试题(二)-HDFS
你准备好面试了吗?这里有一些面试中可能会问到的问题以及相对应的答案。如果你需要更多的面试经验和面试题,关注一下"张飞的猪大数据分享"吧,公众号会不定时的分享相关的知识和资料。 1、 HDFS 中的 block 默认保存几份?
默认保存…
hadoop02--Apache Hadoop集群搭建与介绍
文章目录本文重点内容大纲一、Apache Hadoop入门1.1、Hadoop介绍1.2、Hadoop起源发展1.3、Hadoop特性优点二、Apache Hadoop集群搭建2.1、发行版本2.2、Hadoop集群2.3、Hadoop部署模式、集群规划2.4、Hadoop源码编译三、Hadoop具体安装部署3.1、服务器基础环境准备3.2、安装包目…
Hadoop 复习 ---- chapter04
Hadoop 复习 ---- chapter04HDFS 的特性 1:它是一个分布式文件系统,适用于一次写入,多次读取的场景。 2:它是一个主从结构体系,由 namenode datanode (secondaryNamenode) 3:namen…

【大数据之Hadoop】三十、HDFS故障排除
使用3台服务器,恢复yarn快照。
1 NameNode故障处理 出现NameNode进程挂了并且存储的数据也丢失了,怎么恢复NameNode。 故障模拟:
(1)kill掉NameNode的进程:
kill -9 进程ID(2)删…
大数据---Hadoop安装Hadoop简易版
编写自动安装Hadoop的shell脚本
完整流程: 大数据—Hadoop安装教程(二) 文章目录编写自动安装Hadoop的shell脚本上传压缩包编写shell脚本vim hadoopautoinstall.sh运行上传压缩包
在opt目录下创建连个目录install和soft 将压缩包上传到install目录下 …
自学大数据第四天~hadoop集群的搭建
Hadoop集群安装配置
当hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,此时HDFS名称节点和数据节点位于不同的机器上; 数据就可以分布到多个节点,不同的数据节点上的数据计算可以并行执行了,这时候MR才能发挥其本该有的作用;
没那么多机器怎么办~~~~多几个虚拟…
Hadoop之block切片
切片是一个逻辑概念 在不改变现在数据存储的情况下,可以控制参与计算的节点数目 通过切片大小可以达到控制计算节点数量的目的 有多少个切片就会执行多少个Map任务
hdfs上数据存储的一个单元,同一个文件中块的大小都是相同的 因为数据存储到HDFS上不可变࿰…
大数据技术之Hadoop集群配置
作者简介:大家好我是小唐同学(๑><๑),好久不见,为梦想而努力的小唐又回来了,让我们一起加油!!! 个人主页:小唐同学(๑><๑)的博客主页 目前…
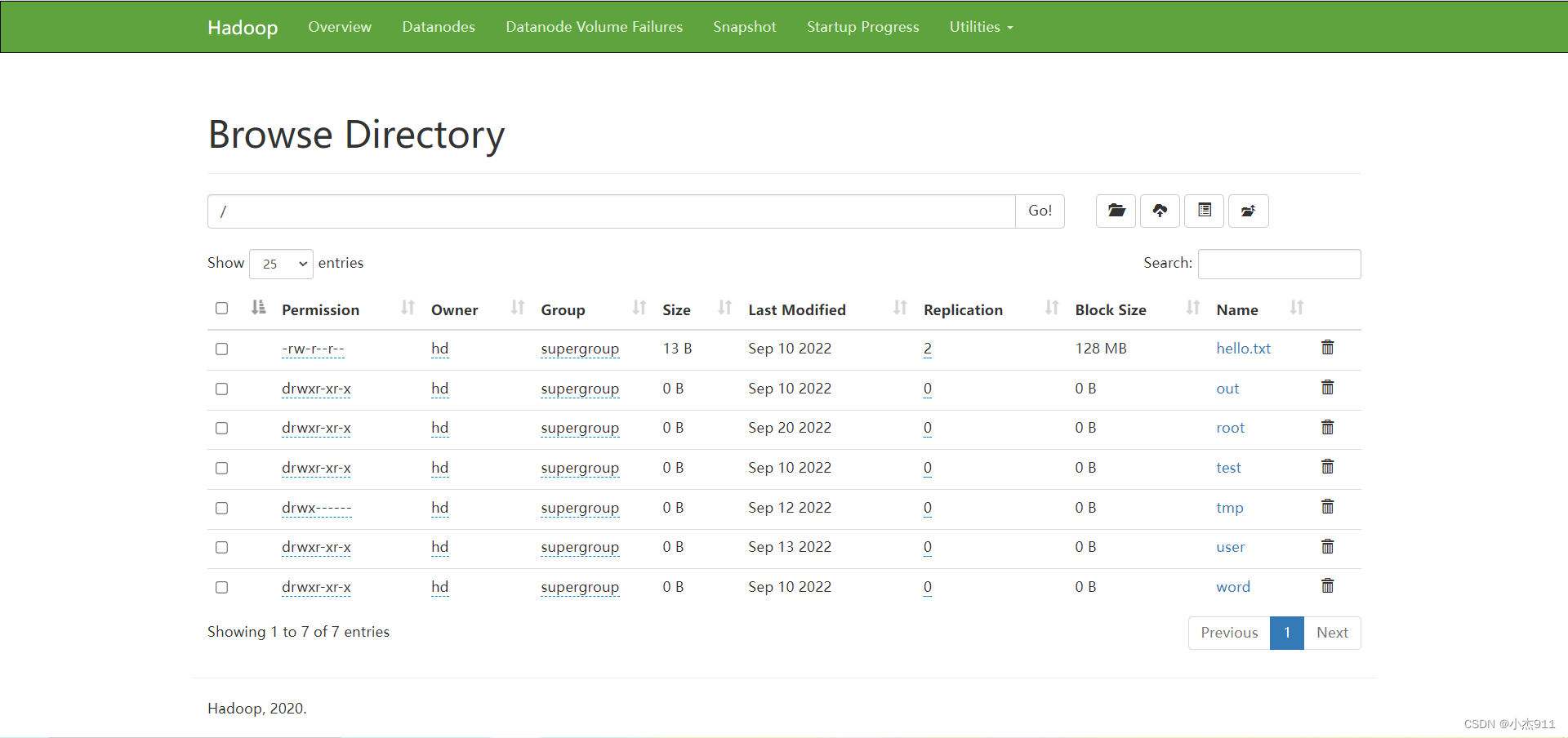
【大数据学习篇3】HDFS命令操作与MR单词统计
1. HDFS命令使用
[rootmaster bin]# su hd[hdmaster bin]$ #查看/目录[hdmaster bin]$ hdfs dfs -ls /
5
#在/目录创建一个为test名字的文件夹[hdmaster bin]$ hdfs dfs -mkdir /test#查看/目录[hdmaster bin]$ hdfs dfs -ls Found 1 itemsdrwxr-xr-x - hd supergroup …
DataWhale 大数据处理技术组队学习task5
六、期中大作业
1. 面试题
1.1 简述Hadoop小文件弊端
当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。小文件过多,在进行M…

ImportError: Can not find the shared library: libhdfs3.so解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…
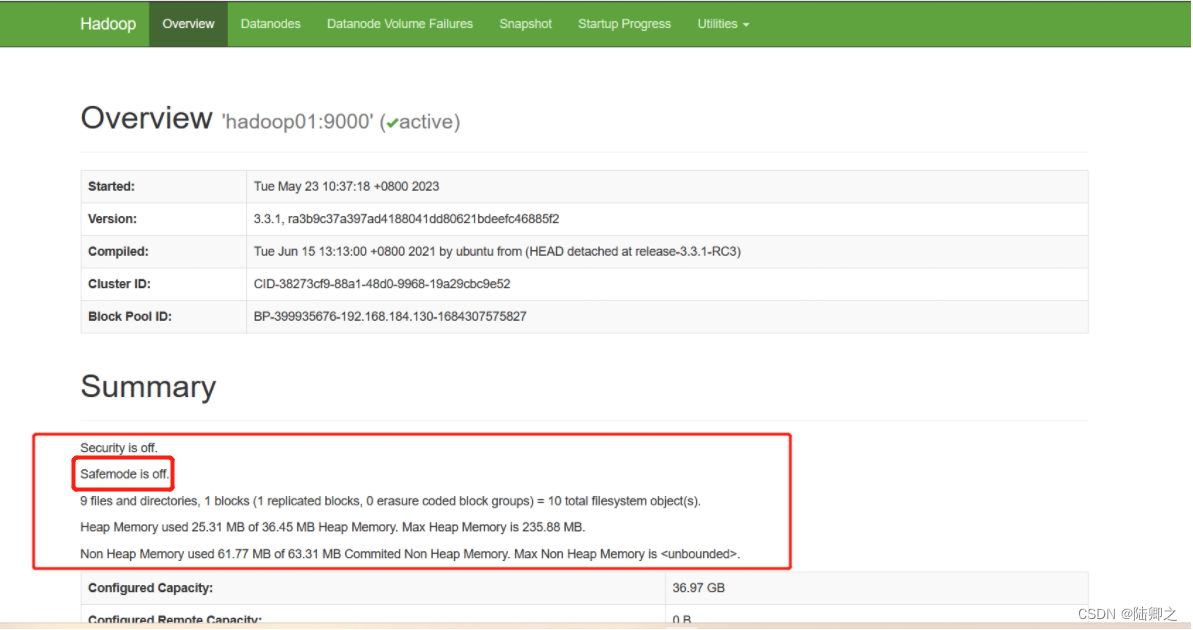
Hadoop的基础操作
Hadoop的基础操作
HDFS是Hadoop的分布式文件框架,它的实际目标是能够在普通的硬件上运行,并且能够处理大量的数据。HDFS采用主从架构,其中由一个NameNode和多个DataNode NameNode负责管理文件系统的命名空间和客户端的访问DataNode负责存储实…
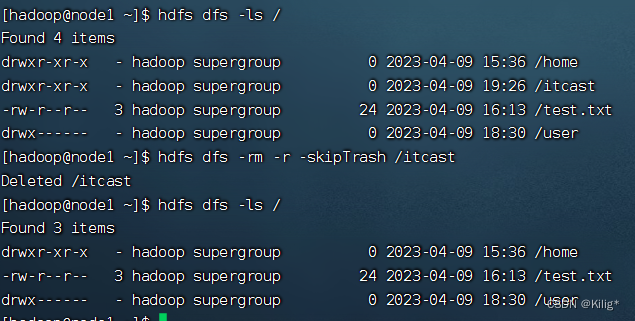
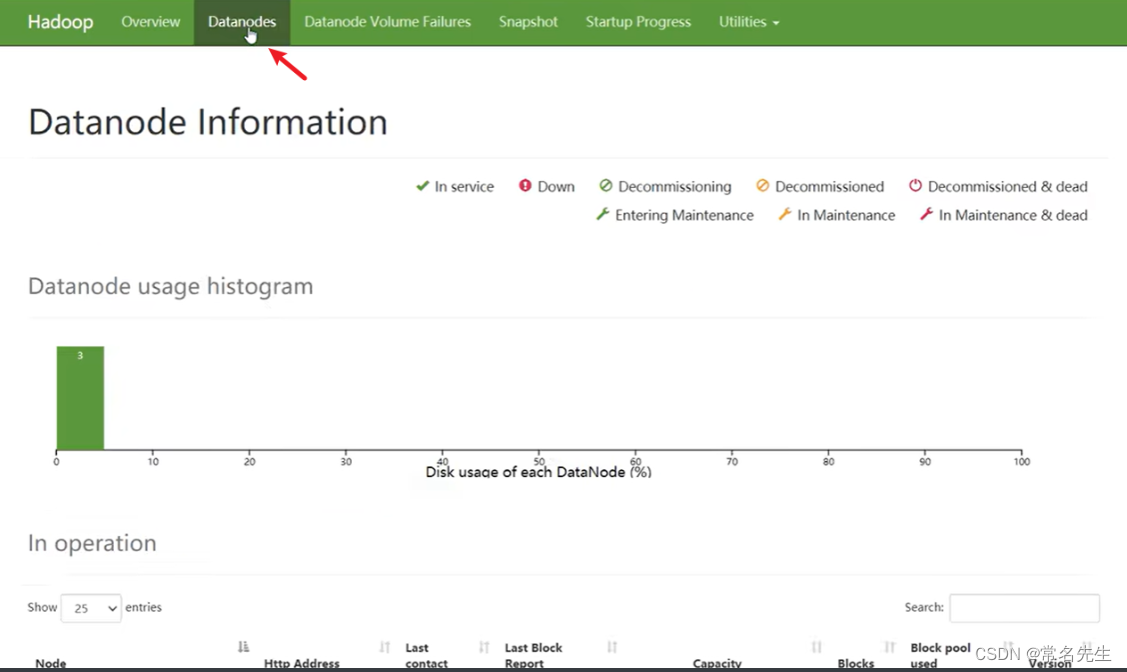
Hadoop-hdfs操作
进程启停相关指令 文件操作相关指令 HDFS WEB UI端口
打开 node1:9870 可以在UI界面浏览文件 可以看到,与linux终端显示一致。
练习题 1在hdfs中创建文件夹:/itcast/itheima,如存在请删除(跳过回收站)
沿路径创…
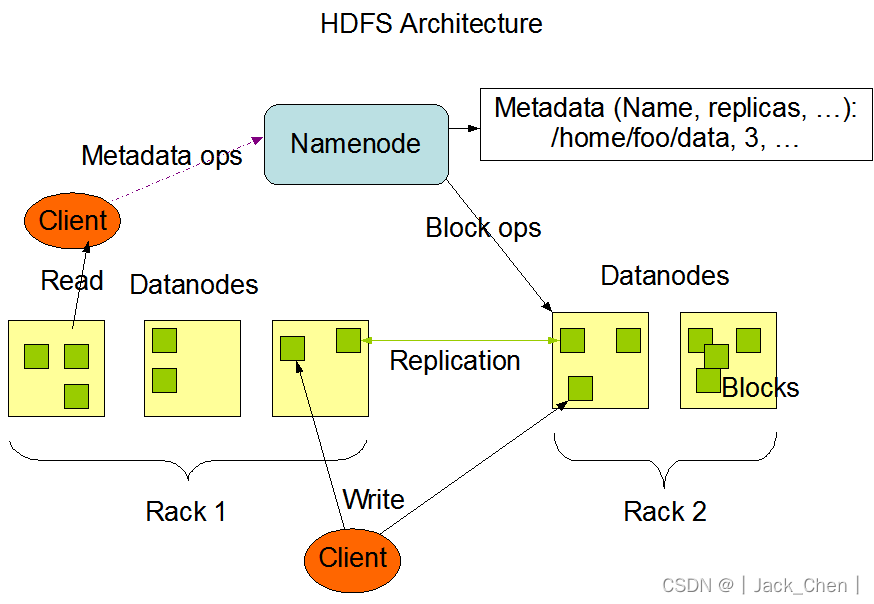
分布式存储系统HDFS之Java API操作
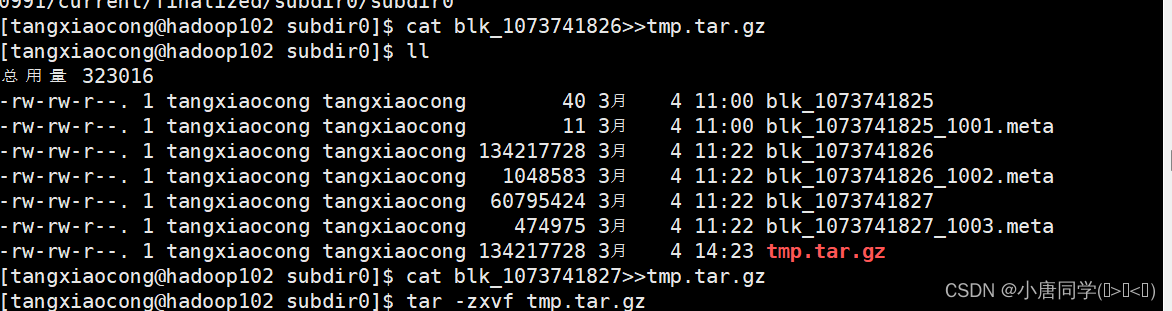
分布式存储系统HDFS之Java API操作安装HadoopHDFS架构设计API操作添加依赖获取FileSystem遍历所有文件文件权限问题创建文件夹及文件删除文件夹及文件文件上传文件下载小文件合并安装Hadoop
Docker安装Hadoop
Linux服务器搭建Hadoop3.X完全分布式集群环境
HDFS架构设计 HDFS…
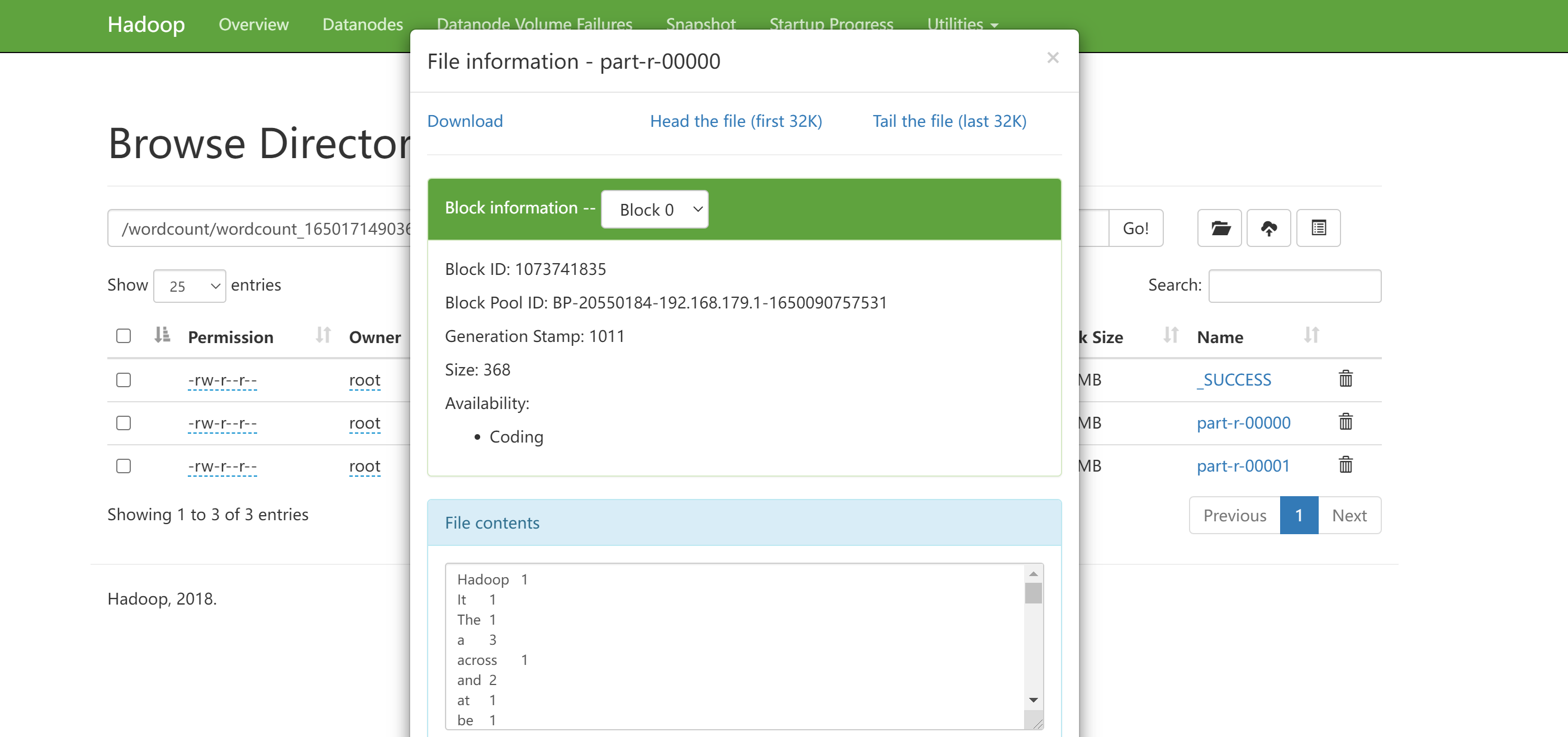
Windows安装Hadoop3.x及在Windows环境下本地开发
Windows安装Hadoop3.x及在Windows环境下本地开发
下载安装
官网:https://hadoop.apache.org/
访问:https://archive.apache.org/dist/hadoop/common/ 下载hadoop.tar.gz并解压到指定目录
访问https://github.com/cdarlint/winutils选择合适版本对应的…
详细记录Linux服务器搭建Hadoop3.X完全分布式集群环境
详细记录Linux服务器搭建Hadoop3.X完全分布式集群环境
Hadoop节点NameNodeSecondary NameNodeDataNodeResource ManagerNodeManagernode001****node002***node003**
下载Hadoop
下载地址:https://archive.apache.org/dist/hadoop/core/
cd /usr/local/programwge…
彷徨 | HDFS初始化创建一个新的集群(将原集群格式化)
学习过程中 , 有时候我们的集群存储空间会满 , 这时候我们可以一个一个删除文件 , 也可以直接格式化集群 , 这样比较方便 , 下面详细介绍个格式化集群的步骤方法:
第一步:先将集群关闭 第二步:删除datanode
因为namenode中存放着文件与数据块列表的对应信息 , 所以datanode一…
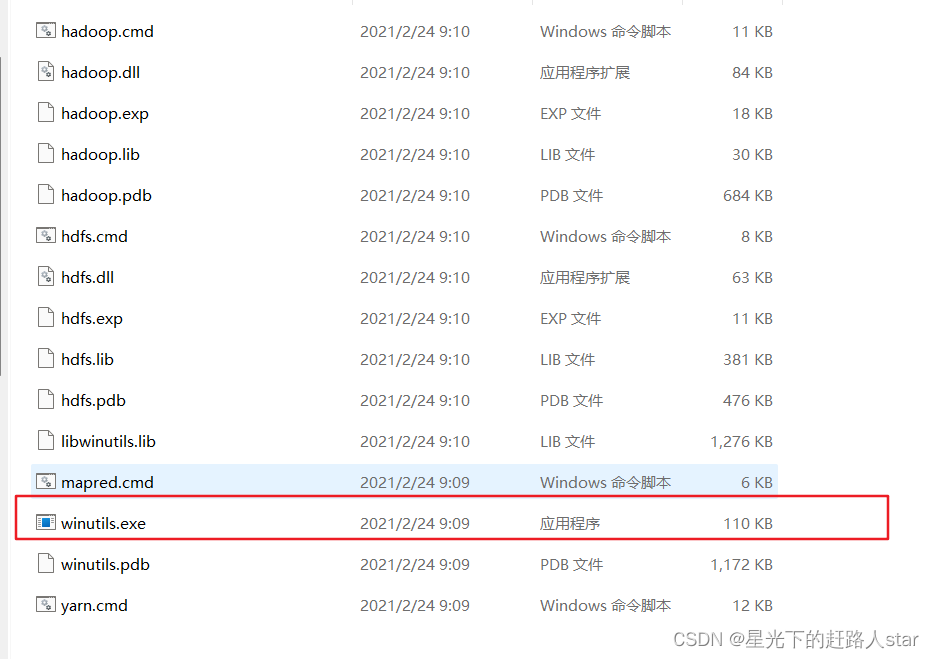
Hadoop基础学习---3、HDFS概述、HDFS的Shell操作、HDFS的API操作
1、HDFS概述
1.1 HDFS产出背景及定义
1、HDFS产生背景 随着数据量越来越大,在一个操作系统存不住所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,…
基于apache paimon实时数仓全增量一体实时入湖
用例简介
Apache Paimon(以下简称 Paimon)作为支持实时更新的高性能湖存储,本用例展示了在千万数据规模下使用全量 增量一体化同步 MySQL 订单表到 Paimon明细表、下游计算聚合及持续消费更新的能力。整体流程如下图所示,其中 …
Linux服务器使用Docker安装Hadoop
Linux服务器使用Docker安装Hadoop
search hadoop
查找合适的Hadoop镜像
[rootadministrator ~]# docker search hadoop
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
sequenceiq/hadoop-docker …

idea Java API 操作 HDFS
文章目录一、 hadoop window配置1.1 hadoop_home环境变量配置1.2 Hadoop里的Java路径配置二、IDE远程管理HDFS1.创建maven,导入pom.xml依赖2.案例测试提示:以下是本篇文章正文内容,下面案例可供参考
一、 hadoop window配置 hadoop tar包解压…
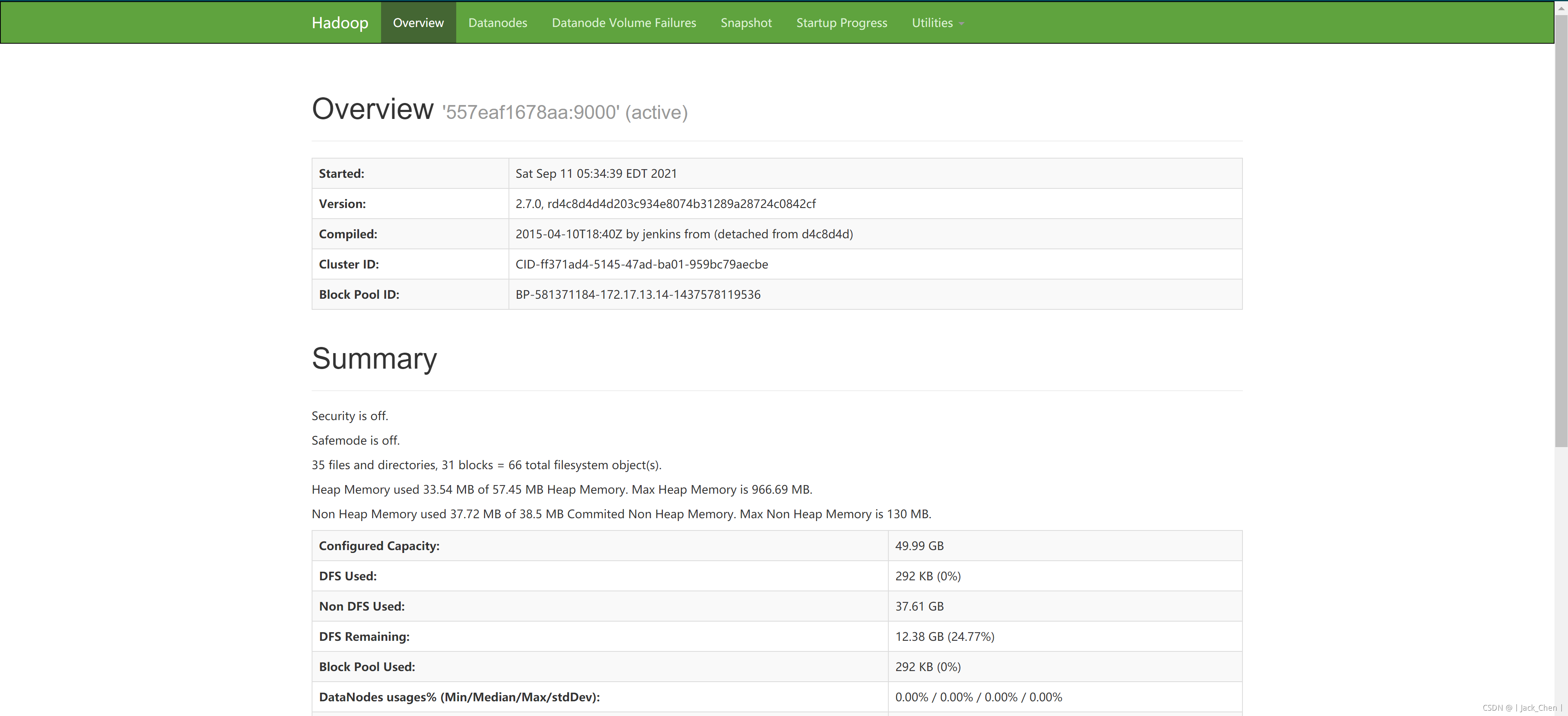
Federation HDFS VS HDFS
序言主要是为了解决HDFS如何把NameNode升级为多个,之前只能部署一个NameNode加一个配合的计算节点 secondaryNameNode,注意secondaryNameNode 并不是主备模式的节点,而是用于协助NameNode做某些计算的节点,以提升吞吐量.cuiyaonan2000163.com如下内容来自于:https://zhuanlan.z…
【大数据之Hadoop】二十五、生产调优-HDFS核心参数
1 NameNode内存生产配置
Hadoop3.x系列的NameNode内存是动态分配的,可以用jmap -heap 进程号 查看分配的内存。 在hadoop102中NameNode和DataNode的内存都是自动分配的,且相等。
根据经验: NameNode最小值为1G,每增加1百万个物理…
HDFS学习笔记【Datanode/写数据】
说明
谁发起的写数据 DFSClient通过调用Sender触发写操作如何建立连接 NN应该知道所有的DN情况 Sender和Receiver创建TCP连接如何接收请求确认,谁来拆分 写请求传送到管道中的每一个节点,最后一个返回确认 DFSClient需要做切分,依次发送数据…

大数据 | 实验一:大数据系统基本实验 | 熟悉常用的HDFS操作
文章目录📚实验目的📚实验平台📚实验内容⭐️HDFSApi⭐️HDFSApi2⭐️HDFSApi3⭐️HDFSApi4⭐️HDFSApi5⭐️HDFSApi6⭐️HDFSApi7⭐️HDFSApi8⭐️HDFSApi9⭐️HDFSApi10📚实验目的
1)理解 HDFS 在 Hadoop 体系结构中…
大数据框架-Hadoop
大数据框架-Hadoop
1.什么是大数据
大数据是指由传统数据处理工具难以处理的规模极大、结构复杂或速度极快的数据集合。这些数据集合通常需要使用先进的计算和分析技术才能够处理和分析,因此大数据技术包括了大数据存储、大数据处理和大数据分析等方面的技术和工具…

分布式存储技术(上):HDFS 与 Ceph的架构原理、特性、优缺点解析
面对企业级数据量,单机容量太小,无法存储海量的数据,这时候就需要用到多台机器存储,并统一管理分布在集群上的文件,这样就形成了分布式文件系统。HDFS是Hadoop下的分布式文件系统技术,Ceph是能处理海量非结…

【学习笔记】尚硅谷Hadoop大数据教程笔记
本文是尚硅谷Hadoop教程的学习笔记,由于个人的需要,只致力于搞清楚Hadoop是什么,它可以解决什么问题,以及它的原理是什么。至于具体怎么安装、使用和编写代码不在我考虑的范围内。
一、Hadoop入门
大数据的特点:
Vo…

基于Flink实时数仓——DWS 层-地区主题表(8)
这个主题使用FlinkSQL实现:数据直接从dwm_order_wide主题获取 代码实现:
public class ProvinceStatsSqlApp {public static void main(String[] args) throws Exception {//TODO 1.获取执行环境StreamExecutionEnvironment env StreamExecutionEnviro…
kettle 6.0安装并连接ORACLE,HADOOP CDH5.3.0以及hadoop客户端配置
到官网下载 下载完毕后解压,记得本机要有java环境并配置好 运行spoon.bat在linux下运行spoon.sh,亲测win7/centos6可以用 新建转换,选择输入拖出表输入,输出拖出表输出 双击设置 点击新建,建立一个oracle新连接 配置好后点击测试可以测试一下 显示测试成功 点击获取sql语句,可以…
大数据学习笔记之一分布式文件系统HDFS
1 大数据学习笔记之一分布式文件系统HDFS
1.1 Hadoop安装
Hadoop Web http://hadoop.apache.org/ Hadoop安装教程 http://dblab.xmu.edu.cn/blog/285/ Eclipse安装 https://jingyan.baidu.com/article/ac6a9a5e2f1a7a2b653eac3f.html
1.2 Hadoop HDFS学习
学习教程 http:/…

HDFS文件上传过程简述
HDFS文件上传过程简述另外底下链接是别人对文件上传的描述,可以作为上图的补充。
hdfs文件上传及下载的流程_RashaunHan的博客-CSDN博客 另外下边是CSDN推荐的一篇写的比较好的文章
HDFS文件上传流程_G_scsd的博客-CSDN博客_hdfs上传文件的基本流程
用Fluentd实现收集日志到HDFS(上)
Fluentd是一个实时日志收集系统,它把日志作为JSON stream,可以同时从多台server上收集大量日志,也可以构建具有层次的日志收集系统。 Fluentd易于安装,有灵活的插件机制和缓冲,支持日志转发。它的特点在于各部分均是可…

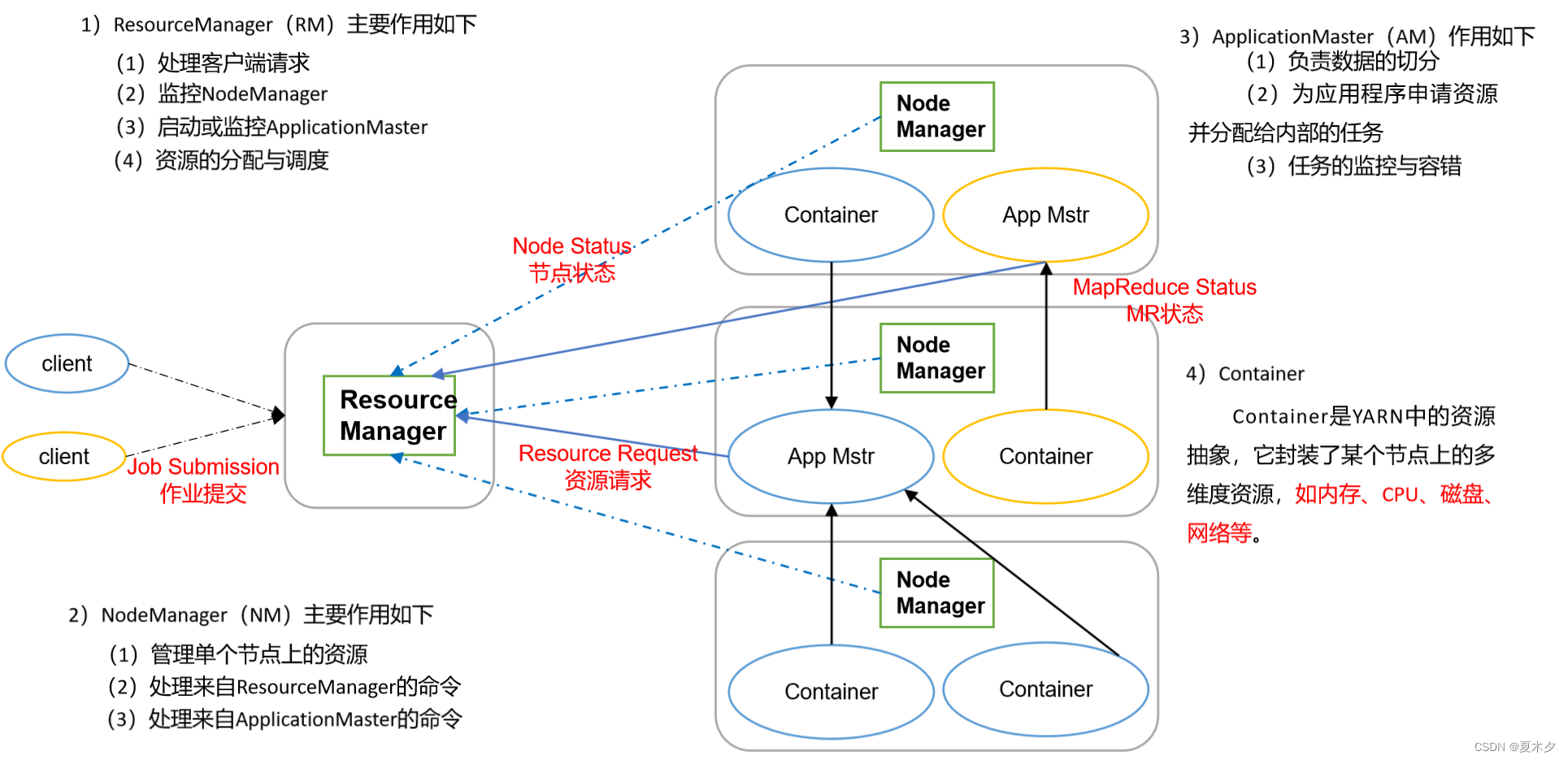
尚硅谷大数据hadoop教程_yarn
p125 课程介绍 p126 yarn基础架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
p127 工作机制 (1)MR程序提交到客户端所在的节点。 (2)YarnRunner向ResourceManager申请一个Applicatio…
【大数据之Hive】十一、Hive-HQL查询之基本查询
基础语法
select [all | distinct] select_expr,select_expr, ...from table)name --从什么表查[where where_condition] --过滤[group by col_list] --分组查询[having col_list] --分组后过滤[order by col_list] --排序[cluster by col_list | …
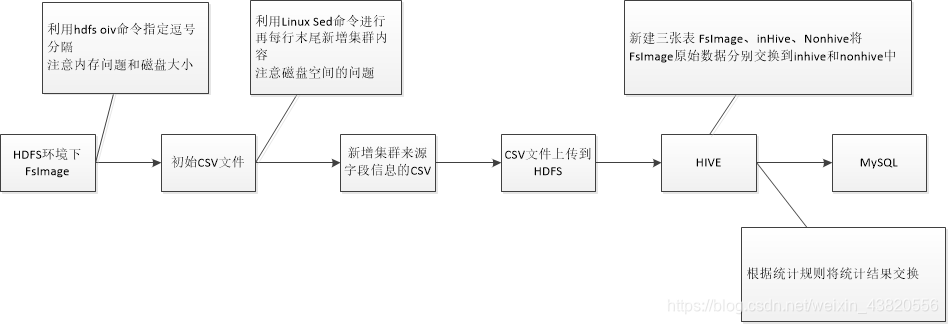
离线分析fsimage文件进行数据深度分析
以离线分析FsImage文件进行数据深度分析
整个方案的基本架构: FsImage文件时HDFS存放在NameNode中的镜像文件,里面包括了整个HDFS集群的目录和文件信息,(类似于一个索引目录部分数据的文件),而且HDFS提供了命令可以将FsImage文件…
头歌Educoder云计算与大数据——实验四 HDFS文件读写
头歌Educoder云计算与大数据——实验四 HDFS文件读写答案在下面的链接里https://blog.csdn.net/qq_36595013/article/details/80571441
Flink+hadoop部署及Demo
Hadoop集群高可用部署
下载hadoop包地址
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz 上传并解压到3台服务器 配置3台主机的hosts和免密登录
1.修改.bash_profile
vi .bash_profile
# HADOOP_HOME
export HADOOP_HOME/apps/svr/hadoop-3.2.…

实验二:熟悉常用的HDFS操作
实验环境: (1)操作系统:Linux(建议 Ubuntu 16.04 或 Ubuntu 18.04)。 (2)Hadoop 版本:3.1.3。 (3)JDK 版本:1.8。 (4)Java IDE: Eclipse。 实验内容与完成情况: (1)编程实现以下功能,并利用Hadoop提供的Shell命令完成相同任务。 ①向HDFS中上传任意文本文件,如果指定的文…
一样的Java,不一样的HDInsight大数据开发体验
1首先开始科普 什么是 HDInsight
Azure HDInsight 是 Hortonworks Data Platform (HDP) 提供的 Hadoop 组件的云发行版,适用于对计算机集群上的大数据集进行分布式处理和分析。目前 HDInsight 可提供以下集群类型:Apache Hadoop、…
【Hadoop】Hadoop概念与实践下载安装MAC(M1芯片)
前置工作
安装 HomeBrew
参考官方文档进行安装
配置本机 ssh 免密登录
hadoop 运行过程中需要 ssh localhost,需要做一些配置保证可以执行成功
允许远程登录 偏好设置 -> 共享 -> 勾选「远程登录」
配置 SSH
通过 ssh-keygen 生成 ssh keyssh-copy-id …
HDFS组织架构及相关介绍
HDFS组织架构
HDFS(Hadoop Distributed File System)是Hadoop生态系统中一个高可靠性、高吞吐量、高容错性的分布式文件系统。它最初是Google发明的GFS(Google File System)的实现, 根据Apache Hadoop Project组织架构,HDFS的组织架构如下: …
Hadoop---10、生产调优手册
1、HDFS—核心参数
1.1 NameNode 内存生产配置
1、NameNode内存计算 每个文件块大概占用150byte,一台服务器128G内存为例,能储存多少文件块呢? 12810241024*1024/150Byte ≈ 9.1 亿 G M KB Byte 2、Hadoop2.x系列,配置 NameNode…
hadoop集群配置与启动(三)
1 集群部署规划NameNode 和 SecondaryNameNode 不要安装在同一台服务器 。(它们两个都需要耗内存,分开减少集群的压力)ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上2配置文件说明Hadoop …
修复HDFS主备节点edits不一致导致的无法进行checkpoint的问题
背景
项目上一套HDFS环境,从4月起会偶发HDFS namenode宕机的问题,后来出现的越来越频繁,最后甚至启动后四五分钟就会宕机,接到需求开始进行排查。
排查过程
日志报错
2023-05-27 22:50:21,844 FATAL namenode.FSEditLog (Jour…
Hadoop运行模块
二、Hadoop运行模式
1)Hadoop官方网站:http://hadoop.apache.org
2)Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。伪分…
hadoop 3.3.4 编译报错记录
一,编译环境
centos7.6
在docker内编译,可能是centos的原因或者docker版本的原因,我用centos7.9安装docker23.x版本就可以完成编译。现在centos7.6,docker19.x版本会缺少一些依赖包不能一次编译过
hadoop 3.3.4 注意BUILDING.t…
Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (一)
Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (一)
前要:Hadoop3.3.1完全分布式部署请参考此文章:Hadoop3.3.1完全分布式部署
一、Hadoop_HDFS
1、概述、背景、优缺点
1.1、概述
Hadoop Distributed File System,简称 HDFS&…
尚硅谷大数据Hadoop教程-笔记02【HDFS】
视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优) 尚硅谷大数据Hadoop教程-笔记01【入门】尚硅谷大数据Hadoop教程-笔记02【HDFS】尚硅谷大数据Hadoop教程-笔记03【MapReduce】尚硅谷大数据Hadoop教程-笔记04【Yarn】尚硅谷大…
ranger,hive,hdfs的三者的权限管理
ranger,hive,hdfs的三者的权限管理
情况一:连接datagrip
用户在hdfs上的权限
可以看出只给了用户write权限,尝试登录xwq用户,在datagrip上登录成功 经过实验验证:要想使用datagrip或者hive-cli登录hive…

Hadoop_Yarn实践 (三) => (Yarn的基础架构、原理、容量/公平调度器、Tool接口、Yarn常用命令、核心参数)
目录 Hadoop_HDFS、Hadoop_MapReduce、Hadoop_Yarn 实践 (三)一、Hadoop_HDFS二、Hadoop_MapReduce三、Hadoop_Yarn1、Yarn资源调度1.1、基础架构1.2、Yarn的工作调度机制(Job提交过程)1.3、Yarn 调度器和调度算法1.3.1、先进先出调度器(FIFO…
Flume日志采集流程(log->kafka->hdfs)
埋点数据:用户访问业务服务器如Nginx,利用log4j的技术,将客户端的埋点数据以日志的形式记录在文件中
服务器日志文件——>HDFS文件
日志文件——>Flume(agent source(interceptor) channel)——>kafka topic ——> Flume(agent…

大数据管理平台DataSophon-1.1.1安装部署详细流程
1 DataSophon介绍
1.1 DataSophon愿景
DataSophon致力于快速实现部署、管理、监控以及自动化运维大数据云原生平台,帮助您快速构建起稳定、高效、可弹性伸缩的大数据云原生平台。
1.2 DataSophon是什么
《三体》,这部获世界科幻文学最高奖项雨果奖的…
Linux服务器搭建Hadoop单节点伪分布式
Linux服务器搭建Hadoop单节点伪分布式
官网:https://hadoop.apache.org/
安装Hadoop
下载地址:https://archive.apache.org/dist/hadoop/core/
wget http://archive.apache.org/dist/hadoop/core/hadoop-3.3.2/hadoop-3.3.2.tar.gz解压且重命名
tar…
Hadoop 2.7分布式部署
转载请注明出处: http://blog.csdn.net/u012842205/article/details/52503514 Hadoop是一个开源的计算框架,致力于在廉价计算机集群上大规模数据集的分布式存储和计算。简介可通过此文章了解:Hadoop概述
当然,最好的学习方式&am…
mapreduce输出数据保存到本地main函数代码
MapReduce是一种大数据处理框架,它可以将大规模的数据分成多个小块,并使用分布式计算系统中的多台机器并行处理这些小块数据。输出数据通常会被保存在分布式文件系统(如HDFS)中,但是也可以将其保存在本地文件系统中。 如果你想将MapReduce输出…
Hadoop1中如何确保HDFS的高可靠(HA)
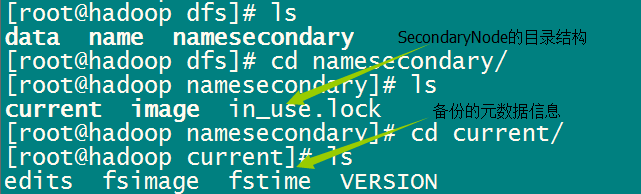
在Hadoop1中NameNode是单节点,如何确保NameNode的高可靠呢? 共有两种措施: 第一:因为对于NameNode来说,其核心数据存储在fsimage和edits当中。所以第一个措施就是对这两个文件进行多备份。 从源码中我们可以发现&am…
HDFS中的file与block块之间的对应关系举例
linux中的jdk-6u24-linux-i586.bin是81M
[roothadoop local]# du -sh *
211M hadoop
60M hadoop-1.1.2.tar.gz
250M jdk
81M jdk-6u24-linux-i586.bin
8.0K mydata
4.0K word2.txt
4.0K word.txt
将jdk-6u24-linux-i586.bin上传到HDFS中
[roothadoop…
Hadoop之HDFS基本原理
Hadoop之HDFS
HDFS简介
HDFS是Hadoop的三大组件之一,用马士兵老师的话来说他就是一块分余展(分布式,冗余数据,可扩展)的大硬盘。它以数据节点的方式来存储数据,从逻辑上来说他分为NameNode和DataNode&…
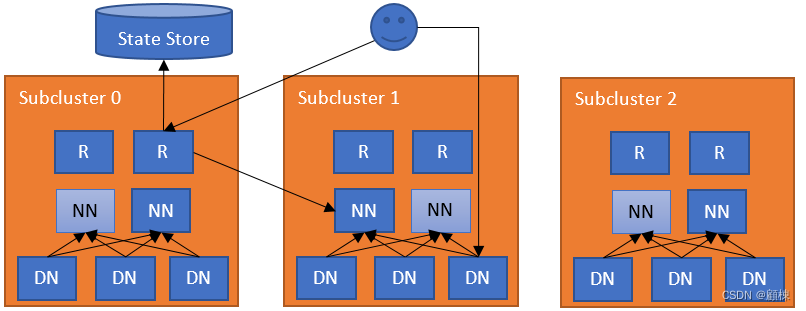
【HDFS实战】HDFS联合(联邦)集群的发展史
HDFS联合集群的发展史 文章目录 HDFS联合集群的发展史HDFS原始架构方案一 HDFS Federation方案二 ViewFs方案三 HDFS Router-based Federation常用命令常用配置RPC serverConnection to the NamenodesAdmin serverHTTP ServerState StoreRoutingNamenode monitoring 版本相关is…
1.Hadoop运行环境搭建-Linux虚拟机准备、JDK安装、Hadoop安装、Windows安装Hadoop
本文目录如下:1.Hadoop运行环境搭建1.1 虚拟机环境准备1.2 安装JDK1.2.1 卸载现有JDK1.2.2 在Linux系统下的opt目录中查看软件包是否导入成功1.2.3 解压JDK到/opt/module目录下1.2.4 配置JDK环境变量1.2.5 测试JDK是否安装成功1.3 安装Hadoop1.3.1 进入到Hadoop安装…
1.HDFS的Shell操作-基础命令、高级命令、基准测试
本文目录如下:1 HDFS的命令行显示(基础)1.1 启动Hadoop集群(方便后续的测试)1.2 help1.3 ls1.4 lsr1.5 mkdir1.6 put1.7 moveFromLocal1.8 appendToFile1.9 cat1.10 get1.11 mv1.12 rm1.13 cp1.14 chmod1.15 chown1.16 copyFromLocal1.17 cop…
使用shell脚本安装hadoop高可用集群
文章目录一.创建一台虚拟机二.复制两台虚拟机三.启动集群四.脚本内容如下1.jdk2.hadoop和zookeeper3.一键启动集群注:需要下载psmisc依赖包,否则无法完成自动切换节点集群划分192.168.56.120 hadoop01192.168.56.121 hadoop02192.168.56.122 hadoop03QuorumPeerMainQuorumPeerM…
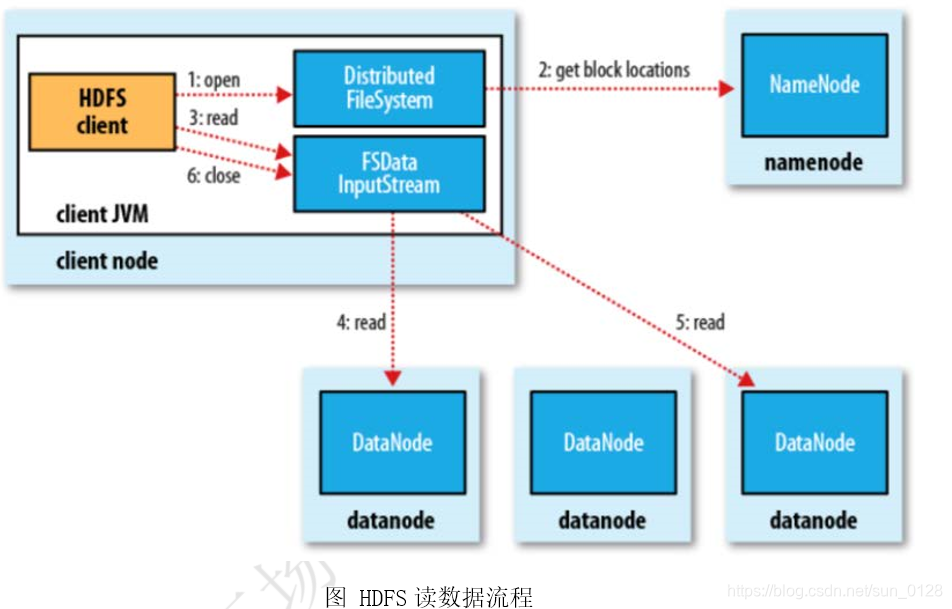
详解hdfs读写文件流程
一.hdfs写数据流程 hdfs dfs -put 要上传的文件的路径 hdfs路径
1.客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。2.NameNode返回是否可以上传?不能上传的话会抛出异常。3.确定可以上传,客户端请求第一个bloc…
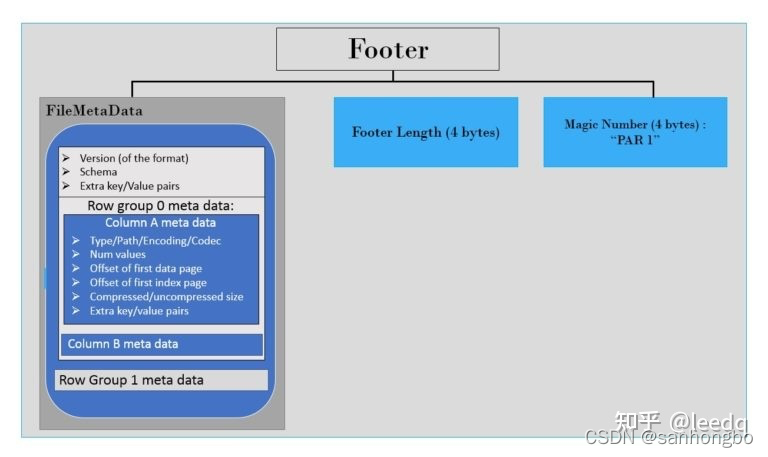
parquet 文件结构
Apache Parquet是Apache Hadoop生态系统的一种免费的开源面向列的数据存储格式。 它类似于Hadoop中可用的其他列存储文件格式,如RCFile格式和ORC格式。本文将简单介绍一下Parquet文件的结构。
Parquet文件格式包含两部分:
data metadata 数据首先写入文…
Hadoop中单词统计案例
需要的软件和工程代码下载地址:
Hadoop中单词统计案例(访问密码:7567):
https://url56.ctfile.com/d/34653256-48746892-4c8f2e?p7567 https://url56.ctfile.com/d/34653256-48746892-4c8f2e?p7567
一、搭建本地环境
1、…

Windows环境下对Linux环境下的HDFS进行基本操作
练习项目的代码地址:https://url56.ctfile.com/f/34653256-538963409-4254a0
一、基础环境要求:
(一)首先保证虚拟机中Hadoop正常启动。 (二)Windows环境中是通过IDE(Eclipse) 创建项目,使用的…
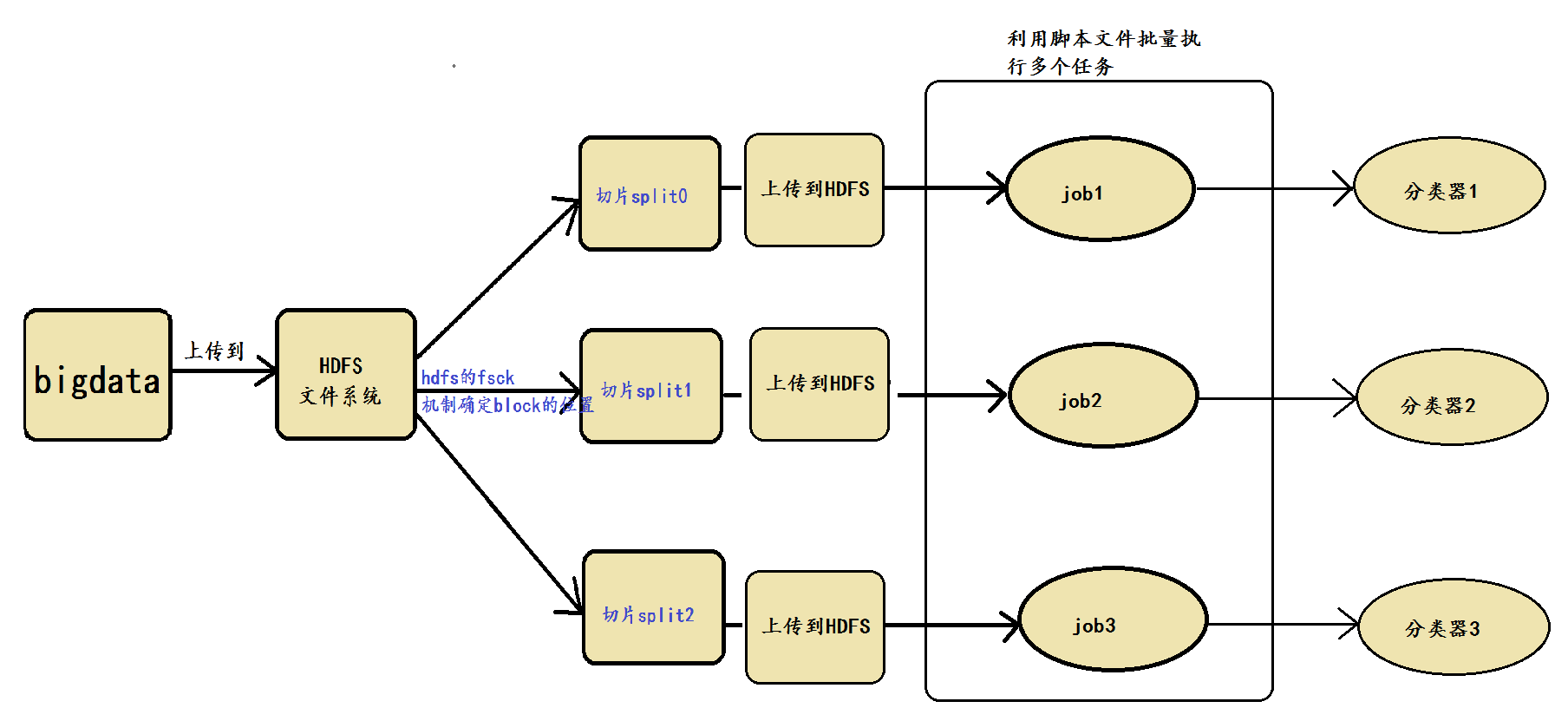
针对例会中出现的split块的位置问题的解决方案
本文作者:王婷婷 针对例会中出现的问题,本人提出的解决方案如下: 涉及到的具体技术实现细节包括hdfs fsck机制与脚本批量执行机制,先分别介绍。 1、hdfs fsck机制 在HDFS中,提供了fsck命令,用于检查HDFS上文件和…
搭建Hadoop分布式集群
搭建Hadoop分布式集群
【系统配置说明】
1)系统环境:CentOS-7-x86-Minimal 2)集群部署:一主三从(master/slave1/slave2/slave3) 3)Java环境:jdk-7u79-linux-x86 4)Hado…
Hive优化笔记(2 - 数据倾斜)
一 基本概念
简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少。默认情况下, Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时,就发生倾斜了
数据倾斜一般有两种情况…
Hadoop系列文章 Hadoop架构、原理、特性简述
Hadoop系列文章 Hadoop架构、原理、特性简述Hadoop HDFSHDFS介绍HDFS架构图HDFS写入数据流程图HDFS读取数据流程图数据块的副本集Hadoop YARNYARN工作流程图YARN的原理及目标Hadoop MapReduceMapReduce工作流程MapReduce编程模型Apache™Hadoop项目开发用于可靠、可伸缩的分布式…

Hive 自定义函数 - Java和Python的详细实现
一 写在前面
1 Hive的自定义函数(User-Defined Functions)分三类:
UDF:one to one,进一出一,row mapping。是row级别操作,类似upper、substr等UDAF:many to one,进多出…
HDFS的Java API
hdfs文件读取流程
client调用FileSystem.open()方法 FileSystem通过RPC与NN通信,NN返回该文件的部分或全部block列表(含有block拷贝的DN地址)选取距离客户端最近的DN建立连接,读取block,返回FSDataInputStreamclient…
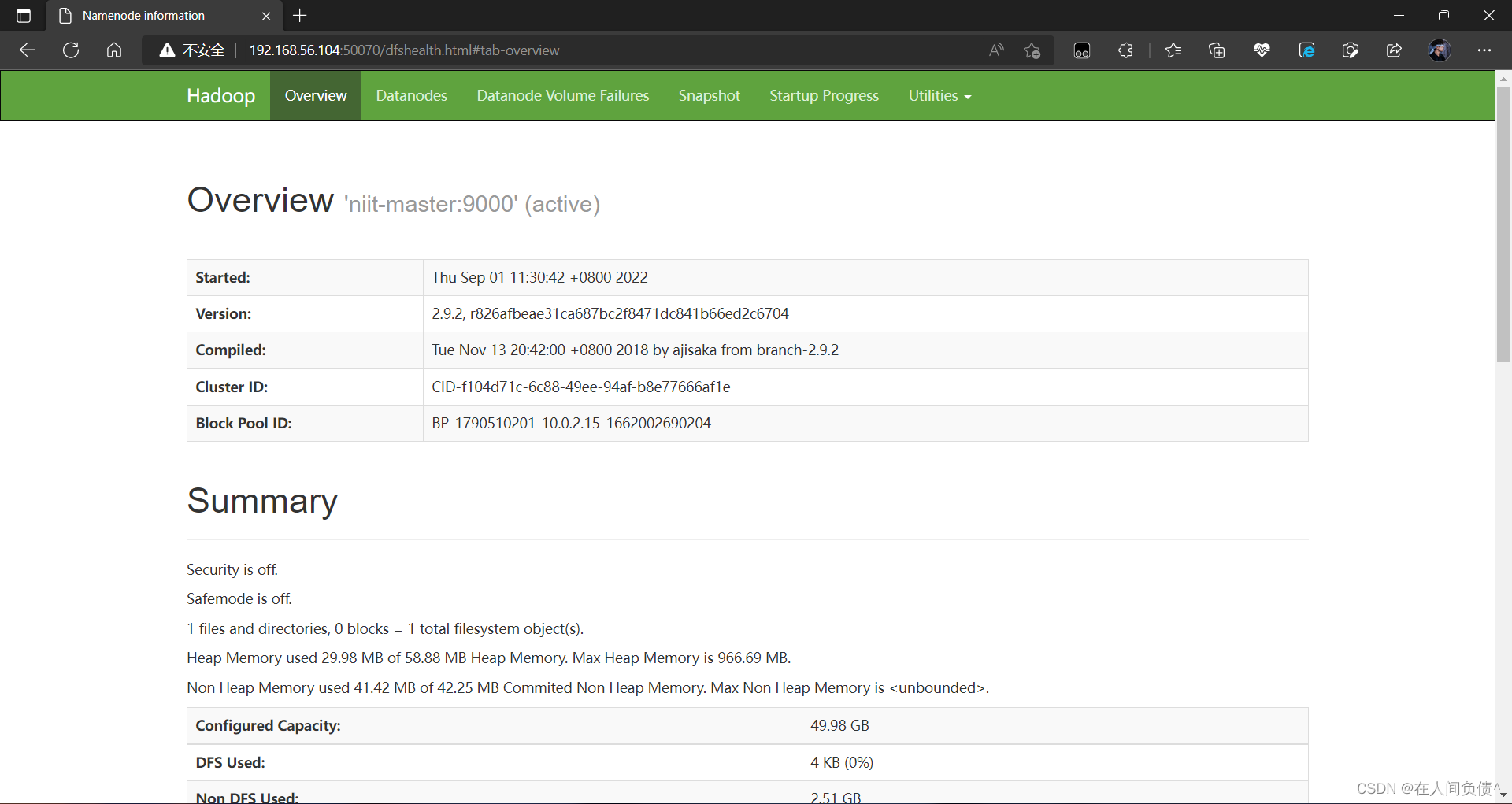
虚拟机安装配置Hadoop(图文教程)
1. 前提准备 启动镜像 Init1.0 检查是否安装 Hdoop 和 jdk
[niitniit-master ~]$ java -version[niitniit-master ~]$ hadoop version2. 安装hadoop和jdk 将 jdk、hadoop 上传到 /home/nitt 直接将压缩文件拖到左侧目录栏即可 解压 hadoop、jdk
[niitniit-master ~]$ t…
大数据入门必读好书推荐
身处于一个大数据时代,大数据无疑是近期最时髦的词汇了。
不管是云计算、社交网络,还是物联网、移动互联网和智慧城市,都要与大数据搭上联系。 随着云计算、移动互联网和物联网等新一代信息技术的创新和应用普及。学习大数据,除了…
从数据仓库到大数据,数据平台这25年是怎样进化的?
数据产品&数据分析总监,2000年开始从事数据领域,从业传统制造业、银行、保险、第三方支付&互联网金融、在线旅行、移动互联网行业 。
我是从2000年开始接触数据仓库,大约08年开始进入互联网行业。很多从传统企业数据平台转到互联网同…
如何成为一名大数据开发工程师,工作经验总结
如何成为一名大数据开发工程师,工作经验总结
原画心旗 2019-11-06 13:35:22
首先,我个人进入大数据行业也纯属偶然,当年实习的时候做的是纯纯的Java开发,后来正式毕业了以后找了份Java开发的工作,本以为和大多数Java…

大数据开发技术与实践期末复习(HITWH)
目录
分布式文件处理系统HDFS
分布式文件系统
HDFS简介
块(block)
主要组件的功能
**名称节点
FsImage文件
名称节点的启动
名称节点运行期间EditLog不断变大的问题
SecondaryNameNode的工作情况
数据节点
HDFS体系结构
HDFS体系结构的局限…
非科班大数据开发学习路线
第一阶段:Java部分 Java基础、JVM、并发、数据库、缓存、设计模式、计算机网络、操作系统、Linux第二阶段:大数据框架 MapReduce、YARN、HDFS、HBase、Hive、Zookeeper、Spark、Storm、Flink、Kafka第三阶段:面试就业 封装项目、面经、简历、…
Java大数据技术学习指南与成长路线
对于普通在校大学生来说,参加岗前实训能够有效的把理论和实践结合起来,快速获得动手能力的提升并到达企业对于软件工程师的技能要求,从而获得更高的职业起点和更好的职业发展前景的有效途径。Java发展成熟、功能强大、使用Java开发的大数据框…
2020年大数据学习路线指南
大数据是对海量数据进行存储、计算、统计、分析处理的一系列处理手段,处理的数据量通常是TB级,甚至是PB或EB级的数据,这是传统数据处理手段所无法完成的,其涉及的技术有分布式计算、高并发处理、高可用处理、集群、实时性计算等&a…
淘宝,滴滴,美团各大厂是如何搭建大数据平台架构的?
今天我们来看一下淘宝、美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图。通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小异,架…

HDFS读取与写入步骤详解
HDFS读取与写入步骤详解
1、Hadoop写流程
Hadoop写流程主要实现将文件上传到HDFS中,其指令格式如下所示:
#hadoop上传文件语法
hdfs dfs -put localpath hdfspath 其上传步骤可以分为以下八个步骤: 客户端通过Distributed FileSystem模块…
Hadoop搭建配置信息
文章目录一、etc/hadoop/core-site.xml二、etc/hadoop/hdfs-site.xml1、NameNode的配置:2、DataNode的配置:三、etc/hadoop/yarn-site.xml1、ResourceManager 和 NodeManager 的配置:2、ResourceManager的配置:3、NodeManager 的配…
hadoop的HDFS的shell命令大全(一篇文章就够了)
文章目录HDFS的shell命令1、安全模式1.查看安全模式状态2.手工开启安全模式状态3.手工关闭安全模式状态2、文件操作指令1.查看文件目录2.查看文件夹情况3.文件操作4.上传文件5、获取文件6.查看文件内容7.创建目录8.修改副本数量9.创建空白文件(不推荐使用࿰…

2.MapReduce序列化—实现序列化接口、序列化案例实战
本文目录如下:第二章 MapReduce序列化案例2.1 自定义FloBean对象实现序列化接口(Writable)2.2 序列化案例实操2.3.1 需求2.3.2 需求分析2.3.3 编写MapReduce程序第二章 MapReduce序列化案例
2.1 自定义FloBean对象实现序列化接口(…
Hadoop服务开启与关闭及其源码介绍
文章目录Hadoop的服务开启与关闭1、开启关闭所有服务(不推荐)1.命令使用2.start-all.sh脚本3.stop-all.sh2、开启Hadoop所有服务★★★1.命令使用2.start-dfs.sh3.start-yarn.sh3、关闭Hadoop所有服务★★★1. 命令使用2.stop-dfs.sh3.stop-yarn.sh4、利…


VMware虚拟机搭建HADOOP环境(下篇)
目录
引言
1.搭建前准备
1.1所需软件
1.2HADOOP配置参数定义
1.3 主要工作
2.配置node01的系统环境
2.1设置node01的IP信息
2.2配置DNS
2.3 配置域名反向解析
2.3禁用操作系统安全配置
3.安装所需软件并配置
3.1配置VMware NAT模式
3.2 在node01中安装可视化传输工…
linux scp 【全新思路解决】出现Permission denied问题
前言
欢迎大家来到我的博客,请各位看客们点赞、收藏、关注三连!
欢迎大家关注我的知识库,Java之从零开始语雀
你的关注就是我前进的动力!
CSDN专注于问题解决的博客记录,语雀专注于知识的收集与汇总,…

Hadoop:文件操作过程之HDFS打开文件、读流程(部分源码)
DistributedFileSystem和DFSClient
Hadoop可以支持不止一种的文件系统,比如对宿主机的文件系统RawLocalSystem、运行在Amazon平台上的S3FileSystem等,所以Hadoop定义了一个FileSystem的抽象类。
DistributedFileSystem继承于FileSystem,是一…
Hadoop基础——HDFS知识点梳理
HDFS基础知识
1. 介绍一下HDFS组成架构?
组成部分:
HDFS Client,NameNode,DataNodeSecondary NameNode( HA模式下是 StandBy NameNode)
Client: 客户端 文件切分,文件上传HDFS时,client将文件切分成一个一个的block࿰…
Hadoop大数据基础篇
Hadoop大数据基础篇
一、Hadoop特点
1. Hadoop优势:高可靠性,高扩展性,高效性(MapReduce),高容错性
2. Hadoop的组成: HDFS(分布式存储系统):NameNode,Client,DataNode MapReduc…

Hadoop的HDFS的集群安装部署
注意:主机名不要有/_等特殊的字符,不然后面会出问题。有问题可以看看第5点(问题)。
1、下载
1.1、去官网,点下载
下载地址:https://hadoop.apache.org/
1.2、选择下载的版本
1.2.1、最新版 1.2.2、其…
Hadoop的安装和使用,Windows使用shell命令简单操作HDFS
1,Hadoop简介
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。 高可靠性。 高效性。 高可扩展性。 高容错性。 成本低。 运行在Linux平台上。 支持多种编程…
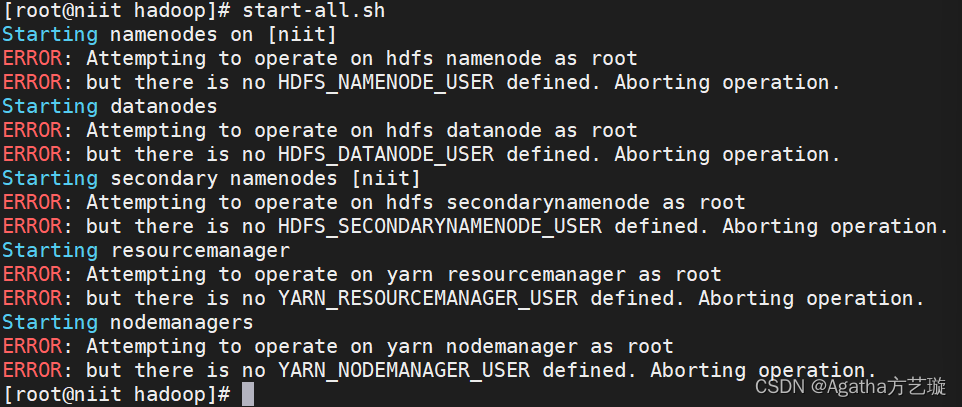
hadoop启动报错:Attempting to operate on hdfs namenode as root
在hadoop安装路径的 /hadoop/sbin路径下: 将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USERroot
HADOOP_SECURE_DN_USERhdfs
HDFS_NAMENODE_USERroot
HDFS_SECONDARYNAMENODE_USERroot还有,star…
搭建Hadoop集群 并实现hdfs上的crud操作
搭建Hadoop集群需要以下步骤:
1. 安装Java环境和Hadoop软件包
在所有节点上安装Java环境和Hadoop软件包;
以下是详细的步骤:
在所有节点上安装Java环境和Hadoop软件包。如果您使用的是Ubuntu,可以使用以下命令安装Java环境和H…
HBase 在集群中对表(ddl)和数据(dml)的相应操作
HBase 在集群中对表(ddl)和数据(dml)的相应操作
HBase特点 要开启hbase之前必须先开启hdfs和zookeeper(关闭将start改为stop即可) 启动hdfs:my_hadoop.sh start 启动zookeeper:zk.sh start 启动hbase:bin/start-hbase.sh 表(ddl)&#x…
【ES实战】使用HDFS插件实现索引快照和恢复
文章目录Snapshot And RestoreHadoop HDFS Repository Plugin使用前提查看插件创建仓库查看仓库创建快照查看快照进度恢复快照查看快照的状态删除快照跨集群使用Snapshot And Restore
快照和恢复有以下作用
数据的备份数据的迁移版本升级…
下面介绍利用HDFS实现快照和恢复 …

大数据常见面试题之hdfs
文章目录一hdfs.写数据流程二.hdfs读数据流程三.简单说说HDFS中NameNode,DataNode的作用?四.SecondaryNameNode的作用?或者是NameNode的启动过程?五.集群安全模式?什么情况下会进入到安全模式?安全模式的解决办法&…

大数据踩坑合集(二)
大数据踩坑合集(二)之vim文件复制不完整
今天在练习shell脚本时,需要复制一个脚本到文件里,脚本代码本身没有任何错误,在vim编辑器里复制粘贴的时候编辑器也没有报错,执行脚本的时候却报错了…初学者一…
1.2 Hadoop
1.2 Hadoop 1.2.1 Hadoop常用端口号 hadoop2.x Hadoop3.x 访问HDFS端口 50070 9870 访问MR执行情况端口 8088 8088 历史服务器 19888 19888 客户端访问集群端口 9000 8020 1.2.2 Hadoop配置文件 配置文件: hadoop2.x core-site.xml、hdfs-site.xml、mapred-site.xml…

Chapter3 分布式文件系统HDFS
3.1分布式文件系统
计算机集群结构:
分布式文件系统把文件分布存储导多个计算机节点上,成千上万的计算机节点构成计算机集群。与之前使用多个处理器和专业高级硬件的并行化处理装置不同的是,目前的分布式文件系统采用的计算机集群都是由普通…

Hadoop 3.x(生产调优手册)----【Hadoop综合调优】
Hadoop 3.x(生产调优手册)----【Hadoop综合调优】1. Hadoop小文件优化方法1. Hadoop小文件弊端2. Hadoop小文件解决方法2. 测试MapReduce计算性能3. 企业开发场景案例1. 需求2. HDFS参数调优3. MapReduce参数调优4. Yarn参数调优5. 执行程序1. Hadoop小文…
Hadoop大数据实战(二)--ubtuntu14.0安装Hadoop最全教程
目录1.安装jdk2.下载Hadoop3.设置Hadoop环境变量4.Hadoop配置文件设置5.创建并格式化 hdfs目录6.关闭防火墙7.启动Hadoop8.打开Hadoop web界面1.安装jdk
步骤1:启动终端:使用快捷键 CtrlAltT启动。也可以单击快捷工具栏的“终端”程序图标来启动。
步骤…

Hadoop 3.x(生产调优手册)----【HDFS--集群扩容及缩容】
Hadoop 3.x(生产调优手册)----【HDFS--集群扩容及缩容】1. 添加白名单2. 服役新服务器3. 节点间数据均衡4. 黑名单退役服务器1. 添加白名单
白名单:表示在白名单的注解 IP 地址可以用来存储数据。 企业中:配置白名单,…
Ubuntu16.04下Hadoop的本地安装与配置
Ubuntu16.04下Hadoop的本地安装与配置一、系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 3.3.1
二、安装步骤 1、安装并配置ssh 1.1 安装ssh 输入命令: $ sudo apt-get install openssh-server ,安装完成后使用命令 $ ssh localhost …

Hadoop——HDFS简介
HDFS(Hadoop Distributed File System),它是Hadoop核心的一部分,是Hadoop默认使用的一套分布式文件系统。这里之所以说默认,是因为Hadoop项目其实有一层比较通用的文件系统抽象层,这使得它可以使用多种文件…
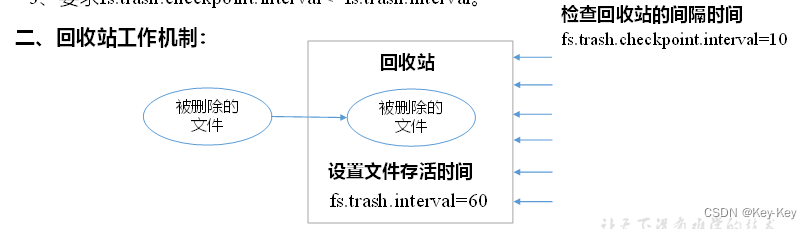
Hadoop回收站trash
回收站简介 在HDFS里,删除文件时,不会真正的删除,其实是放入回收站/trash 回收站里的文件可以快速恢复。 可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值或是回收站被清空时,文件才会被彻底删除ÿ…
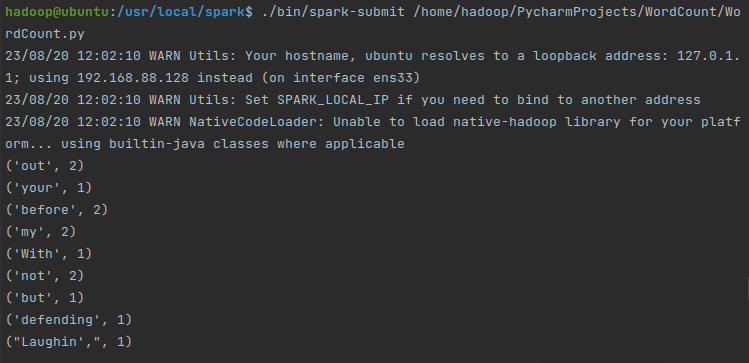
PySpark安装及WordCount实现(基于Ubuntu)
先盘点一下要安装哪些东西:
VMwareubuntu 14.04(64位)Java环境(JDK 1.8)Hadoop 2.7.1Spark 2.4.0(Local模式)Pycharm (一)Ubuntu
VMware 和 ubuntu 14.04(…
Hadoop namenode重新格式化需注意问题
Hadoop namenode重新格式化需注意问题
1、重新格式化意味着集群的数据会被全部删除,格式化前需考虑数据备份或转移问题; 2、先删除主节点(即namenode节点),Hadoop的临时存储目录tmp、namenode存储永久性元数据目录dfs…
大数据技术学习笔记(一)——初识大数据
1 大数据的概念
大数据:指无法在一定的时间范围内用常规的软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决海量数据的存储和海量数据的分析计…
Hadoop HDFS操作指南
1 HDFS 组成架构 image-20220703192933033.pngNameNode(NN) 管理HDFS的名称空间配置副本策略管理数据块(Block)映射信息处理客户端读写请求 DataNode(DN) 存储实际的数据块执行数据块的读写操作 Client(客户端) 文件切分,文件上传HDFS时,Client将文件切分…
Eclipse搭建Hadoop环境及实战资源分享
首先搭建eclipse的haoop2.7.1开发环境,使用的资源链接如下:
windows安装hadoop2.7.1环境
eclipse下搭建hadoop开发环境
这样我们就可以在eclipse进行hadoop开发了 目录
一、MapReduce 模型简介
1.Map 和 Reduce 函数
2.MapR…
两个hdfs之间迁移传输数据
本文参考其他大数据大牛的博文做了整理和实际验证,主要解决hdfs跨集群复制/迁移问题。 在hdfs数据迁移时总会涉及到两个hdfs版本版本问题,致力解决hdfs版本相同和不同两种情况的处理方式,长话短说,进正文。
distcp: hadoop自带的…
【运维】hadoop 集群安装(三)hdfs、yarn集群配置、nodemanager健康管理讲解
文章目录 一. 配置说明1. hadoop各进程环境配置2. hadoop各进程配置2.1. etc/hadoop/core-site.xml2.2. etc/hadoop/hdfs-site.xml2.2.1. NameNode2.2.2. datanode 2.3. etc/hadoop/yarn-site.xml2.3.1. ResourceManager and NodeManager2.3.2. ResourceManager2.3.3. NodeMana…
hdfs滚动升级(rollingUpgrade )
最近对hdfs的升级过程很感兴趣,所以准备研究下其升级的过程,本篇文章是依据官网文档进行的升级过程(地址:Apache Hadoop 2.10.2 – HDFS Rolling Upgrade),该文章中还有关于降低的介绍,感兴趣的…
ClickHouse配置Hdfs存储数据
文章目录 背景配置单机配置HA高可用Hdfs集群参考文档 背景
由于公司初始使用Hadoop这一套,所以希望ClickHouse也能使用Hdfs作为存储 看了下ClickHouse的文档,拿Hdfs举例来说,有两种方式来完成,一种是直接关联Hdfs上的数据文件&am…
Hadoop -HDFS常用操作指令
1.启动HDFS
hadoop/sbin/start-dfs.sh2.关闭 HDFS
hadoop/sbin/stop-dfs.sh3. 在HDFS中创建文件夹
#老版本
hadoop fs -mkdir -p path
#新版本
hadoop dfs -mkdir -p path4.查看指定目录下内容
hadoop fs -ls [-h] [-R] path
hadoop dfs -ls [-h] [-R] ptahpath 指定…

数据科学导论复习个人整理
综合了各方的材料整理综合了这一份 但是考试被EDA打脸(doge) 把图片删了,老师课件外传不好 所以涉及老师课件的图都删了,只写知识点名称 大数据概述
1.大数据时代技术支撑:存储设备容量不断增加、CPU处理能力大幅提升…
【Java-HDFS】使用Java操作HDFS获取HDFS指定目录下的数据量大小
Maven依赖
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId>…
【Hive-小文件合并】Hive外部分区表利用Insert overwrite的暴力方式进行小文件合并
这里我们直接用实例来讲解,Hive外部分区表有单分区多分区的不同情况,这里我们针对不同情况进行不同的方式处理。
利用overwrite合并单独日期的小文件
1、单分区
# 开启此表达式:(sample_date)?.
set hive.support.quoted.identifiersnon…
一百七十三、Flume——Flume写入HDFS后的诸多小文件问题
一、目的
在用Flume采集Kafka中的数据写入HDFS后,发现写入HDFS的不是每天一个文件,而是一个文件夹,里面有很多小文件,浪费namenode的宝贵资源 二、Flume的配置文件优化(参考了其他博文)
(一&a…
hibench运行flink程序第三步run.sh出错(提交job失败)
在hibench上运行flink程序,提交job失败
hibench上做flink实验时,在新的服务器上重新配置环境后,在成功运行Hibench的前两步genSeedDataset.sh和dataGen.sh后,运行run.sh,正常提交,但生成metrics全部为0。 分析原因&am…
实现MySQL-->HDFS;MySQL-->Hive;Hive-->HDFS;HDFS-->MySQL的数据迁移
实现MySQL-->HDFS;MySQL-->Hive;Hive-->HDFS;HDFS-->MySQL的数据迁移一. Apache Sqoop介绍二.Sqoop安装2.1安装Sqoop2.2解压Sqoop2.3配置Sqoop2.4.加入mysql的jdbc驱动包2.5. 设置ACCUMULO_HOME环境变量2.5. 验证启动,显示版本号2.6.显示MySQL中的数据库…
最全分布式文件系统 HDFSYARNMapReduce详讲
HDFS简介
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDF…
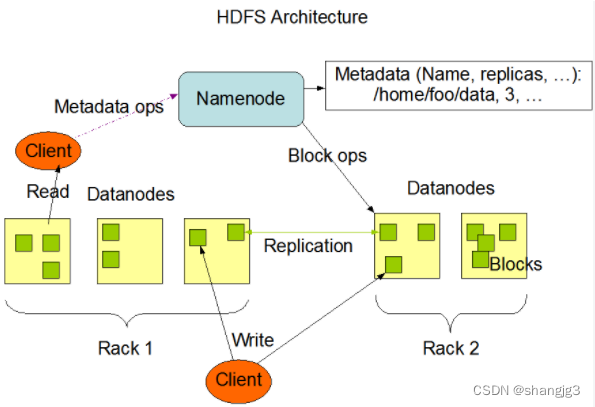
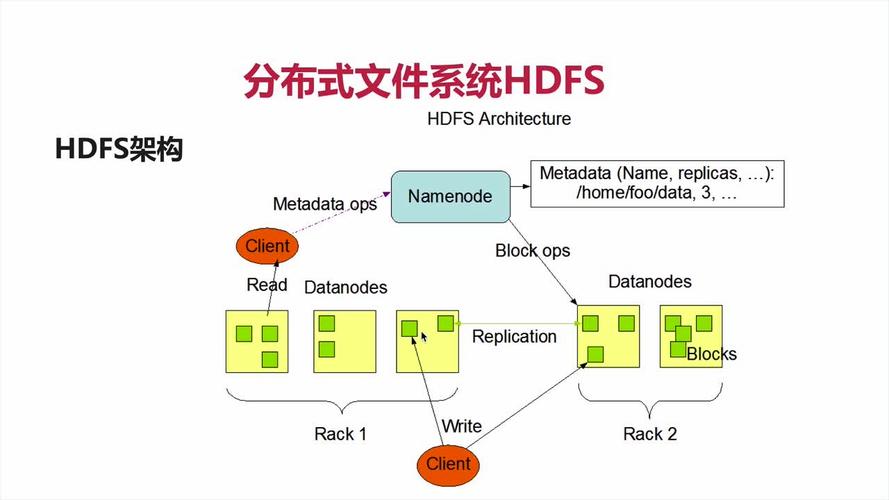
Hadoop分布式文件系统-HDFS
1.介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 2.HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:

Python 使用Hadoop 3 之HDFS 总结
Hadoop 概述 Hadoop 是一个由Apache 软件基金会开发的分布式基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。 Hadoop 实现一个分布式文件系统(Hadoop Distributed File Sy…
07-HDFS入门及shell命令
1 文件系统
是一种存储和组织数据的方法,它使得文件访问和查询变得容易使得文件和树形目录的抽象逻辑概念代替了磁盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据底层存在硬盘哪里,只需记住这个文件的所属目录和文件…
修炼k8s+flink+hdfs+dlink(五:安装dockers,cri-docker,harbor仓库)
一:安装docker。(所有服务器都要安装)
安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/cent…
HIVE-17824,删除hdfs分区信息,清理metastore元数据
当手动删除HDFS 分区数据时,但是并没有清理 Hive 中的分区元数据,删除操作无法自动更新hive分区表元数据。也就是从hdfs中删除大量分区数据,并没有执行如下命令: alter table drop partition commad 从hive 3.0.0开始可以使用MSCK的方法发现新分区或删除丢失的分区; MSCK [REPA…
HDFS的小文件影响及解决办法
Hadoop Distributed File System (HDFS) 是用于存储和处理大规模数据的分布式文件系统。然而,HDFS 中的小文件可能会对系统性能和资源利用产生一些影响。下面是小文件对HDFS的影响以及处理方法的一些信息:
影响: 元数据开销: HDFS中的每个文件和目录都有相关的元数据(文件…
HDFS存储魔法解析:在二次元世界中跃动的数据冒险
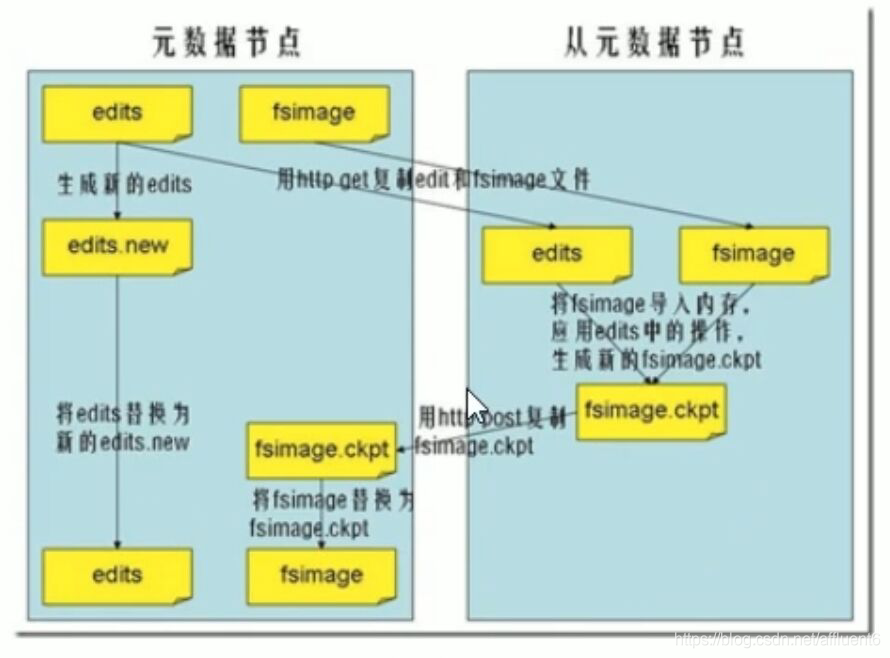
文章目录 版权声明零 引缘起一 存储原理二 fsck命令2.1 副本块数量的配置2.1.1 全局设置方式2.1.2 临时设置方式 2.2 检查文件的副本数2.3 block大小和复制策略配置 三 NameNode元数据3.1 edits文件3.2 fsimage文件3.3 NameNode元数据管理维护3.4 元数据合并控制参数3.5 Checkp…
利用fsimage分析HDFS小文件
一、Hive 小文件概述
在Hive中,所谓的小文件是指文件大小远小于HDFS块大小的文件,通常小于128 MB,甚至更少。这些小文件可能是Hive表的一部分,每个小文件都包含一个或几个表的记录,它们以文本格式存储。
Hive通常用于…
【HDFS】ResponseProcessor线程详解以及客户端backoff反压
ResponseProcessor如何处理datanode侧发过来的packet ack的客户端侧backoff逻辑。ResponseProcessor:主要功能是处理来自datanode的响应。当一个packet的响应到达时,会把这个packet从ackQueue里移除。 @Overridepublic void run() {// 设置 ResponseProcessor 线程的名字setN…
hadoop的hdfs中避免因节点掉线产生网络风暴
hadoop的hdfs中避免因节点掉线产生网络风暴
控制节点掉线RPC风暴的参数 三个参数都是hdfs-site.xml中参数,具体可以参考apache hadoop官网,其实块的复制速度有两个方面决定,一是namenode分发任务的速度,二则是datanode之间进行复…

Deepin 图形化部署 Hadoop Single Node Cluster
Deepin 图形化部署 Hadoop Single Node Cluster
升级操作系统和软件 快捷键 ctrlaltt 打开控制台窗口 更新 apt 源 sudo apt update更新 系统和软件 sudo apt -y dist-upgrade升级后建议重启 开启ssh服务 打开资源管理器 进入系统盘 找到 etc 目录 在系统盘的 etc 目录上 右键…
hadoop解决数据倾斜的方法
分析&回答
1,如果预聚合不影响最终结果,可以使用conbine,提前对数据聚合,减少数据量。使用combinner合并,combinner是在map阶段,reduce之前的一个中间阶段,在这个阶段可以选择性的把大量的相同key数据先进行一个合并,可以看做…
【HDFS】XXXRpcServer和ClientNamenodeProtocolServerSideTranslatorPB小记
初始化RouterRpcServer时候会new ClientNamenodeProtocolServerSideTranslatorPB,并把当前RouterRpcServer对象(this)传入构造函数: ClientNamenodeProtocolServerSideTranslatorPBclientProtocolServerTranslator =new ClientNamenodeProtocolServerSideTranslatorPB(this…
Hadoop HDFS 高阶优化方案
目录
一、短路本地读取:Short Circuit Local Reads
1.1 背景
1.2 老版本的设计实现
1.3 安全性改进版设计实现
1.4 短路本地读取配置
1.4.1 libhadoop.so
1.4.2 hdfs-site.xml
1.4.3 查看 Datanode 日志
二、HDFS Block 负载平衡器:Balan…
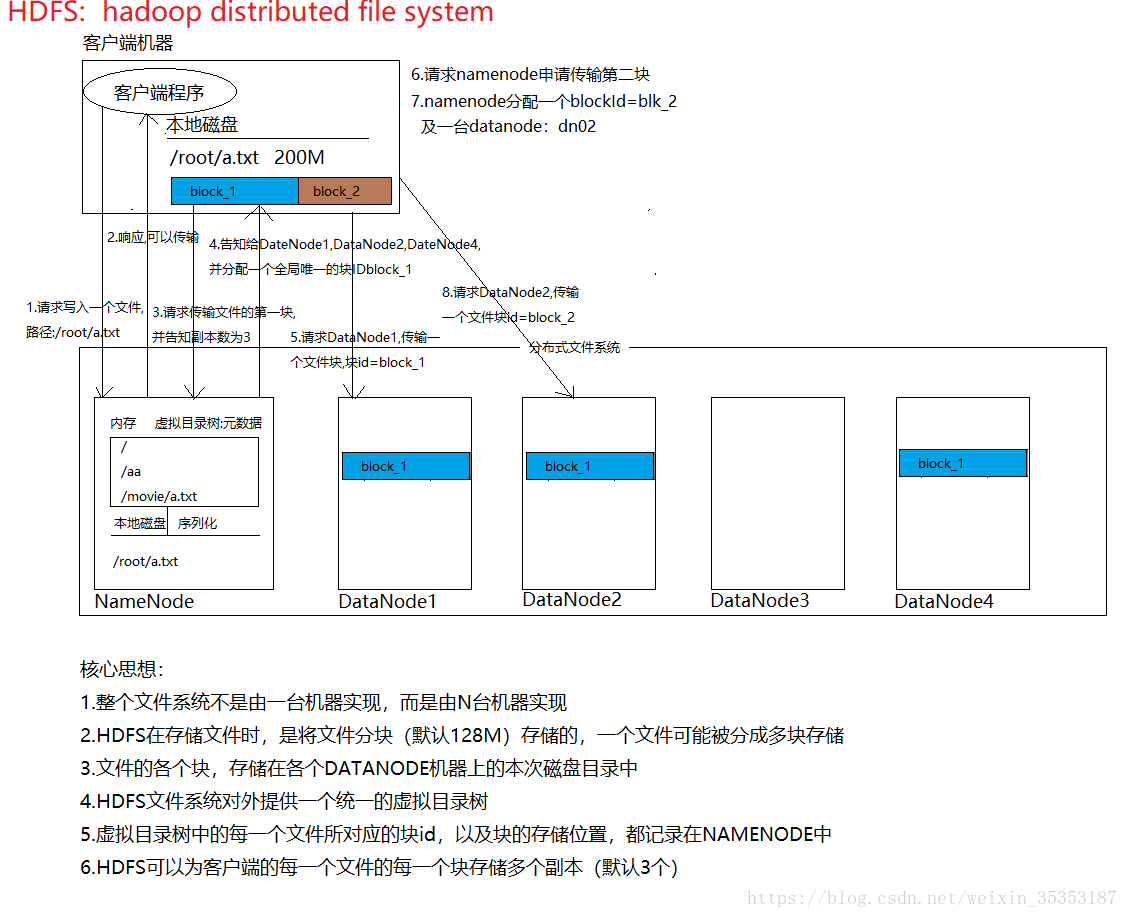
HDFS文件的读写流程
Hadoop
HDFS的读写文件流程
HDFS写文件流程 客户端通过Distributed FileSystem模块向NameNode请求上传文件(hadoop fs -put 文件名 文件路径 ) 判断该客户端是否有写入权限NameNode检查目标文件是否已存在,父目录是否存在。 NameNode返回是…

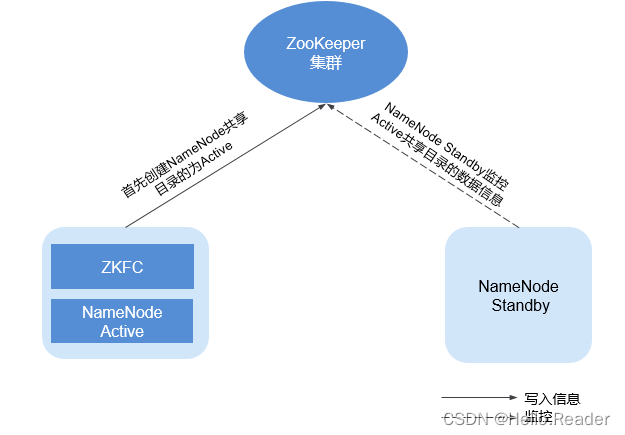
HDFS HA 高可用集群搭建详细图文教程
目录
一、高可用(HA)的背景知识
1.1 单点故障
1.2 如何解决单点故障
1.2.1 主备集群
1.2.2 Active、Standby
1.2.3 高可用
1.2.4 集群可用性评判标准(x 个 9)
1.3 HA 系统设计核心问题
1.3.1 脑裂问题
1.3.2 数据状…
【HDFS】Hadoop-RPC:客户端侧通过Client.Connection#sendRpcRequest方法发送RPC序列化数据
org.apache.hadoop.ipc.Client.Connection#sendRpcRequest: 这个方法是客户端侧向服务端发送RPC请求的地方。调用点是Client#call方法过来的。
此方法代码注释里描述了一个细节:这个向服务端发送RPC请求数据的过程并不是由Connection线程发送的,而是其他的线程(sendParams…
HDFS编程实践-从HDFS中下载指定文件到本地
前言:Hadoop采用java语言开发,提供了Java Api与HDFS进行交互
先要把hadoop的jar包导入到idea中去
为了能编写一个与hdfs交互的java应用程序,一般需要向java工程中添加以下jar包
1)/usr/local/hadoop/share/hadoop/common目录下…
Eclipse环境基于HDFS的API进行开发
文章目录 IOUtils方式读取文件1.文件准备2.下载安装Eclipse3.打开eclipse,新建java项目,添加关于hadoop的一些包4.包内新建类进行开发5.利用打包的方式生成java jar包6.验证代码正确性 其它问题:Exception in thread “main“ java.lang.Unsu…
Hadoop3教程(三):HDFS文件系统常用命令一览
文章目录 语法格式(44) HDFS的文件系统命令(开发重点)参考文献 语法格式
hdfs命令的完整形式:
hdfs [options] subcommand [subcommand options]其中subcommand有三种形式:
admin commandsclient comman…
【HDFS】hdfs的count命令的参数详解
Usage: hadoop fs -count [-q] [-h] [-v] [-x] [-t [<storage type>]] [-u] [-e] [-s] <paths

熟悉MySQL和HDFS操作
1.使用Python操作MySQL数据库
在Windows系统中安装好MySQL8.0.23和Python3.8.7,然后再完成下面题目中的各项操作。
现有以下三个表格:
表1 学生表:Student(主码为Sno) 学号(Sno) 姓名&#…
HDFS元数据管理/磁盘清理维护
元数据管理
1.元数据管理概述
> HDFS分类-类型分包括以下几部分
文件、目录自身的属性信息,例如文件名,目录名,修改信息等 文件记录的信息的存储相关的信息,例如存储块信息,分块情况,副本个数等 记录…

Hadoop实践指南:揭秘HDFS元数据并解析案例
1.什么是元数据
元数据(Metadata),描述数据的数据(data about data)。
1.1 HDFS元数据
元数据:关于文件或目录的描述信息,如文件所在路径、文件名称、文件类型等等,这些信息称为文…
大数据基础 HDFS客户端操作
一、Maven概述 Maven是一个专门用于管理和构建Java项目的工具。我们之所以要使用Maven,是因为Maven可以为我们提供一套标准化的项目结构、一套标准化的构建流程和一套方便的依赖管理机制,这些功能可以使得我们的项目结构更加清晰,导入jar包的…
Java API访问HDFS
一、下载IDEA
下载地址:https://www.jetbrains.com/idea/download/?sectionwindows#sectionwindows 拉到下面使用免费的IC版本即可。 运行下载下来的exe文件,注意安装路径最好不要安装到C盘,可以改成其他盘,其他选项按需勾选即可…
Flume 快速入门【概述、安装、拦截器】
文章目录 什么是 Flume?Flume 组成Flume 安装Flume 配置任务文件应用示例启动 Flume 采集任务 Flume 拦截器编写 Flume 拦截器拦截器应用 什么是 Flume?
Flume 是一个开源的数据采集工具,最初由 Apache 软件基金会开发和维护。它的主要目的是…
HDFS集群环境部署(超级详细!!)
一、部署Hadoop的关键点 1.上传,解压到/export/server,配置软链接 2.修改4个配置文件,workers,hadoop.env.sh,core-stie.xml,hdfs-site.xml 3.SCP分发到root2,root3,并设置环境变量 4.创建数据目录,并修改文…
Hadoop原理,HDFS架构,MapReduce原理
Hadoop原理,HDFS架构,MapReduce原理
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,…
【HDFS】dfs.datanode.max.transfer.threads 配置
文档介绍如下:
The dfs.datanode.max.transfer.threads parameter is used to specify the size of the thread pool for a DataNode to process read and write data streams. Default value: 4096. If the value of this parameter is small, the number of Xceiver thread…

【头歌实训】分布式文件系统 HDFS
文章目录 第1关:HDFS的基本操作任务描述相关知识HDFS的设计分布式文件系统NameNode与DataNode HDFS的常用命令 编程要求测试说明答案代码 第2关:HDFS-JAVA接口之读取文件任务描述相关知识FileSystem对象FSDataInputStream对象 编程要求测试说明答案代码 …

3. hdfs概述与高可用原理
简述
HDFS(Hadoop Distributed File System)是一种Hadoop分布式文件系统,具备高度容错特性,支持高吞吐量数据访问,可以在处理海量数据(TB或PB级别以上)的同时最大可能的降低成本。
HDFS适用于…
【HDFS运维】HDFS回收箱机制:原理、配置、配置可能导致的问题分析
文章目录 一. HDFS回收箱机制逻辑1. 基本逻辑2. 举例说明 二. 配置测试1. 配置2. 回收箱相关命令 三. 其他问题讨论1. api不会走trash机制2. 因为设置了Trash configuration导致nn无法响应 一. HDFS回收箱机制逻辑
1. 基本逻辑 If trash configuration is enabled, files remo…

6. hdfs的命令操作
简介
本文主要介绍hdfs通过命令行操作文件
操作文件有几种方式,看个人习惯
hdfs dfs
hdfs fs
hadoop fs个人习惯使用 hadoop fs 可操作任何对象,命令基本上跟linux命令一样
Usage
[hadoophadoop01 ~]$ hadoop fs
Usage: hadoop fs [generic option…
Hadoop-- hdfs
1、HDFS中的三个进程:NameNode(NN)、DataNode(DN)、SecondNameNode(SNN)
2、NameNode(NN)
1、作用:
1、接收客户端的一个读、写的服务,在namenode上存储了数据文件和datanode的映射的关系。 …
Hive部署,hive客户端
1、Hive部署
Hive是分布式运行的框架还是单机运行的?
Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
1.1、规划
我们知道Hive是单机工具后,就需要准备一台服务…
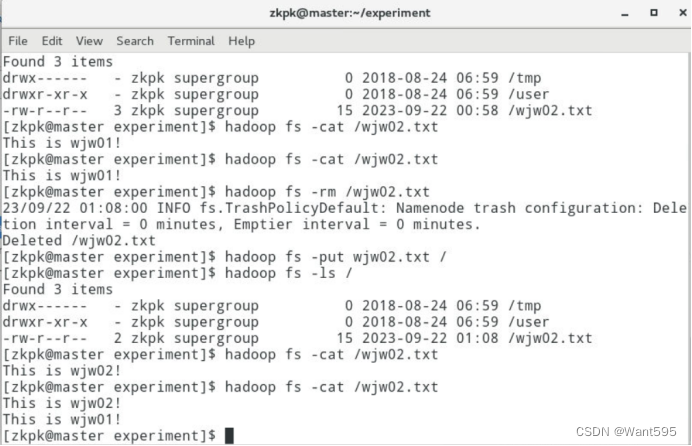
【大数据开发技术】实验04-HDFS文件创建与写入
文章目录 一、实验目标二、实验要求三、实验内容四、实验步骤 一、实验目标
熟练掌握hadoop操作指令及HDFS命令行接口掌握HDFS原理熟练掌握HDFS的API使用方法掌握单个本地文件写入到HDFS文件的方法掌握多个本地文件批量写入到HDFS文件的方法
二、实验要求
给出主要实验步骤成…
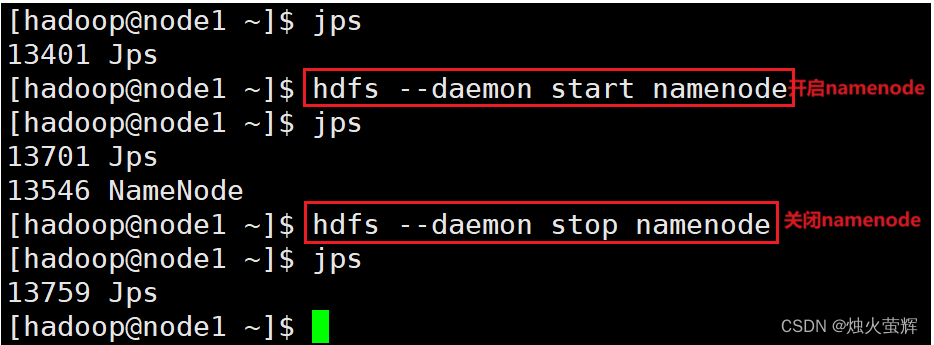
「大数据-2.1」HDFS集群启停命令
目录 一、HDFS集群一键启停脚本 1. HDFS集群的一键启动脚本 2. HDFS集群的一键关闭脚本 二、单进程启停 1. hadoop-daemon.sh脚本 2. hdfs脚本 三、总结 1. 一键启停脚本 2. 独立进程启停 一、HDFS集群一键启停脚本 Hadoop HDFS组件内置了HDFS集群的一键启停脚本。 1. HDFS集群…
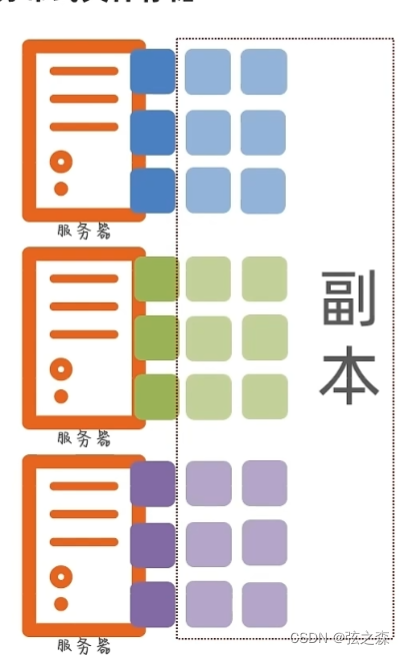
七、HDFS文件系统的存储原理
1、总结 之所以把总结放在文件开头,是为了让读者对这篇文章有更好的理解,(其实是因为我比较懒……) 对于整个HDFS文件系统的存储原理,我们可以总结为一句话,那就是: 分块备份 2、存储结构和问题…
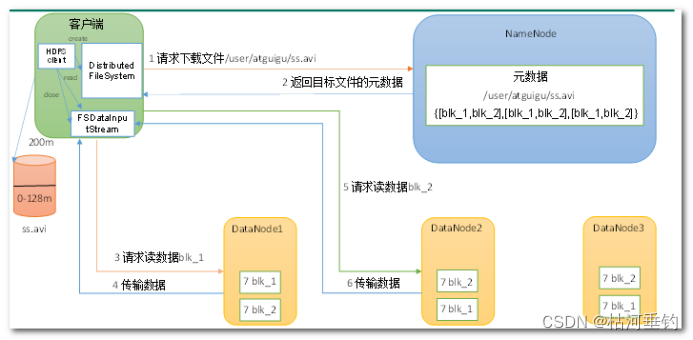
hadoop组件HDFS
HDFS里面的几个组件,分别有哪些功能和作用?
Namenode:主角色,负责和客户端进行沟通.Datanode:从角色,负责存储数据Secondary namenode:秘书,服务器数据的收集,将信息传递给namenode注:Namenode宕机时集群会通过选举机制ÿ…
Pyspark读写csv,txt,json,xlsx,xml,avro等文件
1. Spark读写txt文件
读:
df spark.read.text("/home/test/testTxt.txt").show()
-------------
| value|
-------------
| a,b,c,d|
|123,345,789,5|
|34,45,90,9878|
-------------2. Spark读写csv文件
读:
# 文件在hdfs上…
一百八十三、大数据离线数仓完整流程——步骤二、在Hive的ODS层建外部表并加载HDFS中的数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(二)步骤二、在Hive的…
【Hadoop_03】HDFS概述与Shell操作
1、集群配置(1)集群启动/停止方式总结(2)编写Hadoop集群常用脚本(3)常考面试题【1】常用端口号【2】常用配置-文件 2、HDFS概述(1)HDFS产出背景及定义(2)HDFS…
修炼k8s+flink+hdfs+dlink(一:安装dlink)
一:mysql初始化。
mysql -uroot -p123456
create database dinky;
grant all privileges on dinky.* to dinky% identified by dinky with grant option;
flush privileges;二:上传dinky。
上传至目录/opt/app/dlink
tar -zxvf dlink-release-0.7.4.t…

记录一次因内存不足而导致hiveserver2和namenode进程宕机的排查
背景
最近发现集群主节点总有进程宕机,定位了大半天才找到原因,分享一下
排查过程
查询hiveserver2和namenode日志,都是正常的,突然日志就不记录了,直到我重启之后又恢复工作了。 排查各种日志都是正常的࿰…
hdfs数据丢失数据块block missing问题排查解决
组件:HDFS/cube-hdfs-1 告警内容:NameNode Blocks Health:Total Blocks:[13352317], Missing Blocks:[1] 开始时间:2023-10-02 08:05:12 持续时间:8小时44分钟 hadoop会在6个小时候自动检测并修复
主动发现阶段:
当数据块损坏后,DN节点执行directorysc…

十五、YARN辅助架构
1、学习内容
(1)了解什么是代理服务器
(2)了解什么是历史服务器
2、辅助架构
(1)辅助架构的由来 对于YARN架构来讲,除了ResourceManager集群资源总管家、NodeManager单机资源管家两个核心角…

十四、YARN核心架构
1、目标
(1)掌握YARN的运行角色和角色之间的关系
(2)理解使用容器做资源分配和隔离
2、核心架构
(1)和HDFS架构的对比
HDFS架构: YARN架构:(主从模式) &…
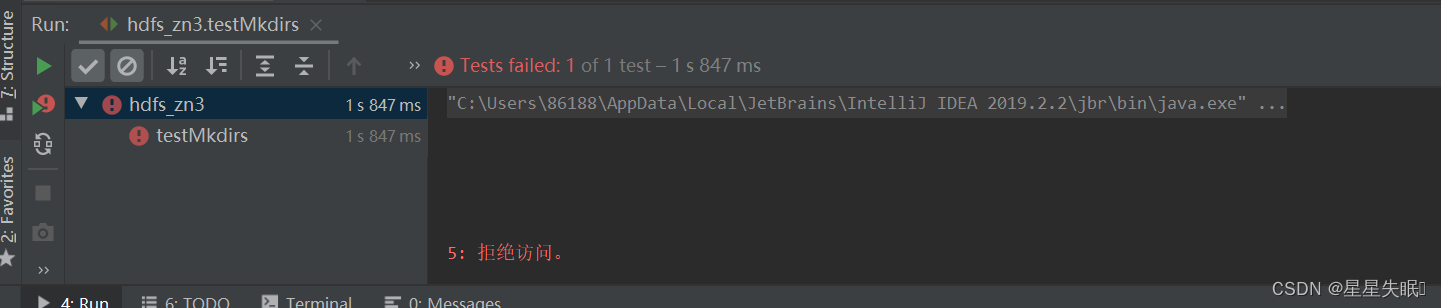
HDFS JAVA API的应用
首先把hadoop服务起来 1. (简答题)
使用HDFS 的JAVA API 进行编程:
(1)获取自己HDFS集群下的所有文件和目录;
//获取自己HDFS集群下的所有文件和目录;import org.apache.hadoop.conf.Configuration;
import org.apa…
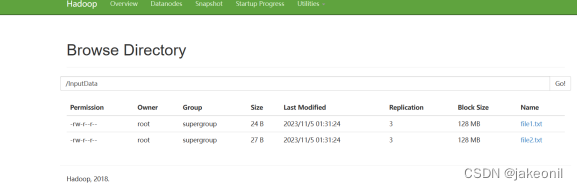
大数据平台/大数据技术与原理-实验报告--实战HDFS
实验名称 实战HDFS 实验性质 (必修、选修) 必修 实验类型(验证、设计、创新、综合) 综合 实验课时 2 实验日期 2023.10.23-2023.10.27 实验仪器设备以及实验软硬件要求 专业实验室(配有centos7.5系统的linu…
Spark-Streaming+HDFS+Hive实战
文章目录 前言一、简介1. Spark-Streaming简介2. HDFS简介3. Hive简介二、需求说明1. 目标:2. 数据源:3. 数据处理流程:4. HDFS文件保存:5. Hive外部表映射:三、实战示例演练1. 编写gbifdataset.properties配置文件2. 导入依赖3. 编写ConfigUtils类4. 编写FieldUtils类5. …
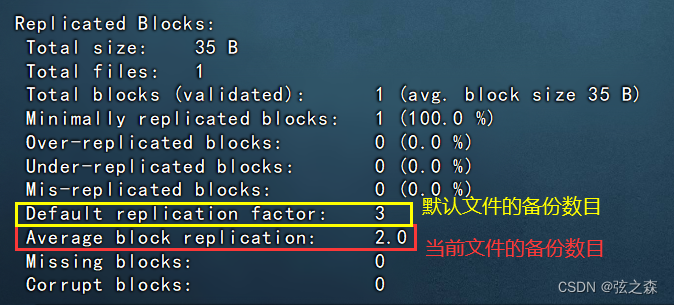
八、hdfs文件系统副本块数量的配置
1、配置方式 2、实际操作演示
(1)在Hadoop用户的根目录下创建text.txt文件 (2)上传文件
hadoopnode1:~$ hdfs dfs -ls hdfs://node1:8020/
Found 4 items
drwxr-xr-x - hadoop supergroup 0 2023-11-21 23:06 hdfs:/…

【大数据】HBase 中的列和列族
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…
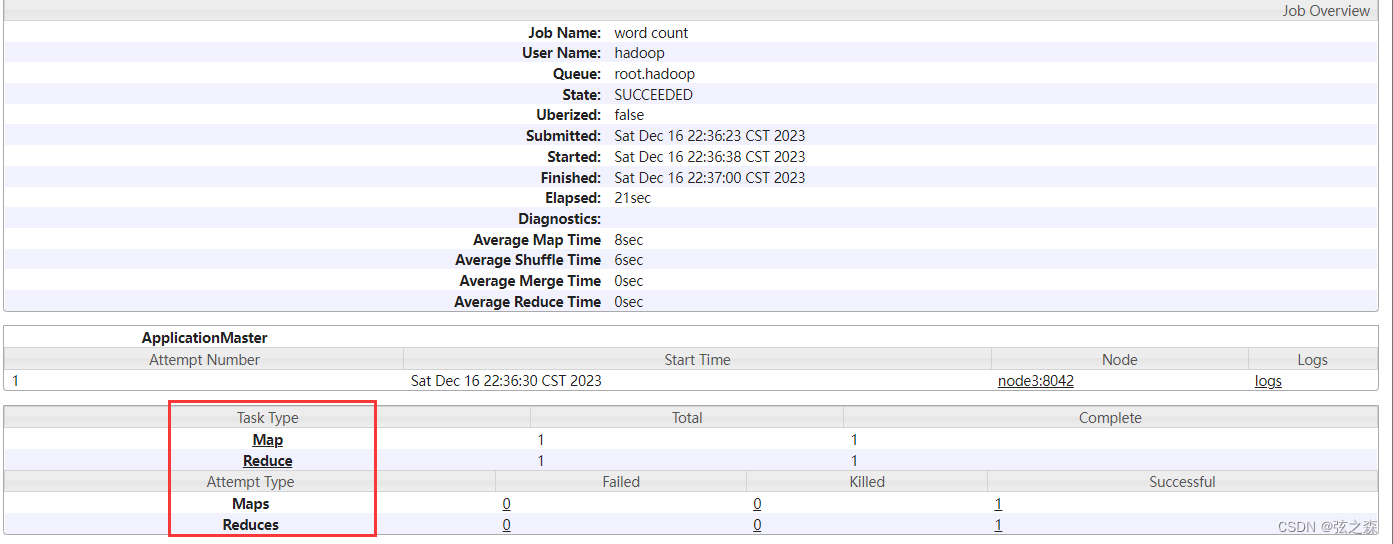
十七、如何将MapReduce程序提交到YARN运行
1、启动某个节点的某一个用户
hadoopnode1:~$ jps
13025 Jps
hadoopnode1:~$ yarn --daemon start resourcemanager
hadoopnode1:~$ jps
13170 ResourceManager
13253 Jps
hadoopnode1:~$ yarn --daemon start nodemanager
hadoopnode1:~$ jps
13170 ResourceManager
15062 Jp…
【HDFS面试】HDFS面试题答案
题目 HDFS文件写入和读取流程 HDFS组成架构 介绍下HDFS,说下HDFS优缺点,以及使用场景 HDFS作用 HDFS的容错机制 HDFS的存储机制 HDFS的副本机制 HDFS的常见数据格式,列式存储格式和行存储格式异同点,列式存储优点有哪些? …
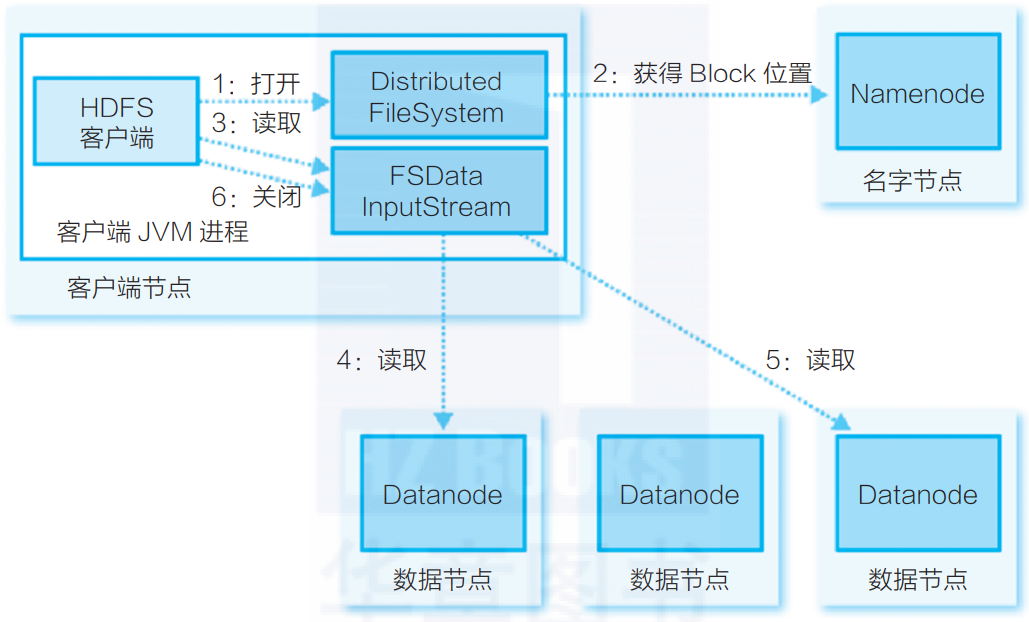
【Hadoop面试】HDFS读写流程
HDFS(Hadoop Distributed File System)是GFS的开源实现。
HDFS架构
HDFS是一个典型的主/备(Master/Slave)架构的分布式系统,由一个名字节点Namenode(Master) 多个数据节点Datanode(Slave)组成。其中Namenode提供元数…

【基础知识】大数据组件HDFS简述
HDFS是经典的Master和Slave架构,每一个HDFS集群包括一个NameNode和多个DataNode。 NameNode管理所有文件的元数据信息,并且负责与客户端交互。DataNode负责管理存储在该节点上的文件。每一个上传到HDFS的文件都会被划分为一个或多个数据块,这…
core-site.xml,yarn-site.xml,hdfs-site.xml,mapred-site.xml配置
core-site.xml
<?xml version"1.0" encoding"UTF-8"?>
<?xml-stylesheet type"text/xsl" href"configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may no…
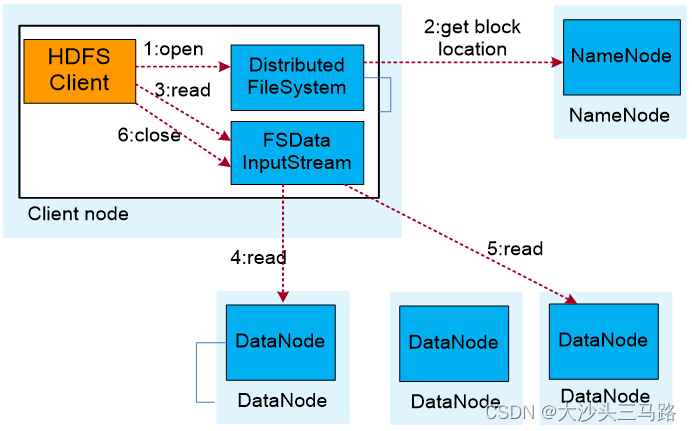
大数据Hadoop-HDFS_架构、读写流程
大数据Hadoop-HDFS
基本系统架构
HDFS架构包含三个部分:NameNode,DataNode,Client。 NameNode:NameNode用于存储、生成文件系统的元数据。运行一个实例。 DataNode:DataNode用于存储实际的数据,将自己管理…
【Hadoop精讲】HDFS详解
目录
理论知识点
角色功能
元数据持久化
安全模式
SecondaryNameNode(SNN)
副本放置策略
HDFS写流程
HDFS读流程
HA高可用
CPA原则
Paxos算法
HA解决方案
HDFS-Fedration解决方案(联邦机制) 理论知识点 角色功能 元数据持久化 另一台机器就…
hadoop02_HDFS的API操作
HDFS的API操作
1 HDFS 核心类简介
Configuration类:处理HDFS配置的核心类。
FileSystem类:处理HDFS文件相关操作的核心类,包括对文件夹或文件的创建,删除,查看状态,复制,从本地挪动到HDFS文件系统中等。…


flume异常关闭文件修复方法
flume在从kafka采集数据后,会将数据写入到hdfs文件中。在写入过程中,由于集群负载、资源或者网络原因会导致文件没有正常关闭,即文件表现为tmp格式,这种格式的文件从hdfs往hive分区load数据时,会导致数据无法查询问题。 flume写…
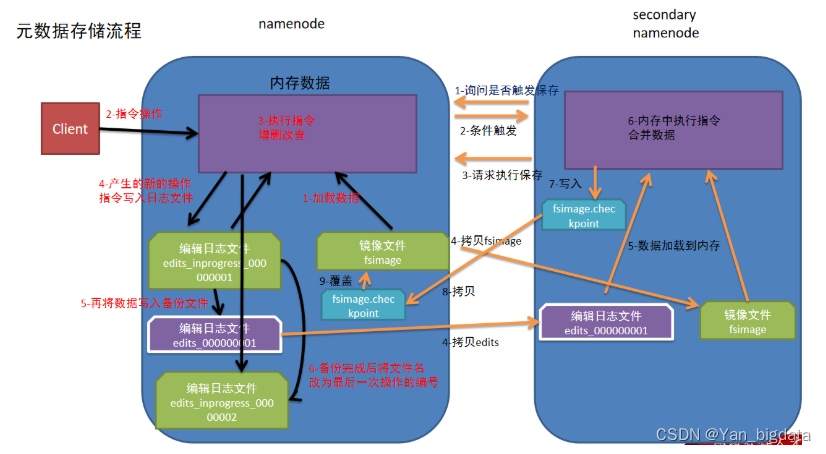
Hadoop进阶学习---HDFS分布式文件存储系统
1.hdfs分布式文件存储的特点
分布式存储:一次写入,多次读取 HDFS文件系统可存储超大文件,时效性较差. HDFS基友硬件故障检测和自动快速恢复功能. HDFS为数据存储提供很强的扩展能力. HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改. HDFS可以在普通廉价的机器…
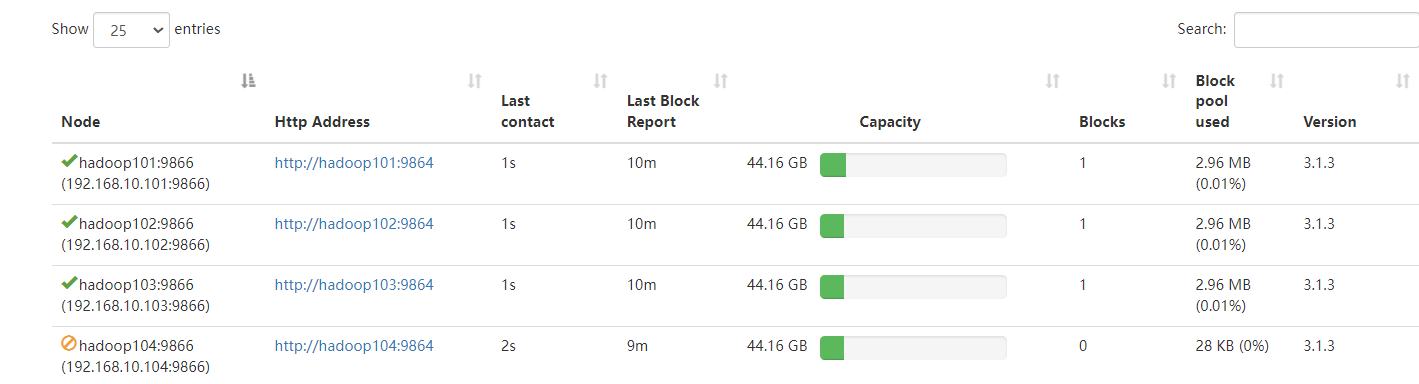
大数据技术学习笔记(四)—— HDFS
目录 1 HDFS 概述1.1 HDFS 背景与定义1.2 HDFS 优缺点1.3 HDFS 组成架构1.4 HDFS 文件块大小 2 HDFS的shell操作2.1 上传2.2 下载2.3 HDFS直接操作 3 HDFS的客户端操作3.1 Windows 环境准备3.2 获取 HDFS 的客户端连接对象3.3 HDFS文件上传3.4 HDFS文件下载3.5 HDFS删除文件和目…
7-HDFS的文件管理
单选题 题目1:下列哪个属性是hdfs-site.xml中的配置? 选项: A fs.defaultFS B dfs.replication C mapreduce.framework.name D yarn.resourcemanager.address 答案:B ------------------------------ 题目2:HDFS默认备份数量&…

4. hdfs高可用集群搭建
简介
前面把hadoop机器已经准备好了,zk集群搭建好了,本本就是开始搭建hdfs环境
hadoop环境准备
创建hadoop用户
三台机器都创建hadoop用户
useradd hadoop -d /home/hadoop
echo "1q1w1e1r" | passwd --stdin hadoophadoop用户相互免密登…
Hadoop学习笔记(HDP)-Part.12 安装HDFS
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …

二百一十一、Flume——Flume实时采集Linux中的Hive日志写入到HDFS中(亲测、附截图)
一、目的
为了实现用Flume实时采集Hive的操作日志到HDFS中,于是进行了一场实验
二、前期准备
(一)安装好Hadoop、Hive、Flume等工具 (二)查看Hive的日志在Linux系统中的文件路径
[roothurys23 conf]# find / -name…

9 HDFS架构剖析
问题
100台服务器,存储空间单个200GB 20T 5T文件如何存储? 128MB一块 128MB81GB 1288*10241TB 5T数据分成的128MB的块数 8192 * 5 客户端(client)代表用户通过与namenode和datanode交互来访问整个文件系统。
HDFS集群有两类节点: 一个na…

下厨房网站月度最佳栏目菜谱数据获取及分析PLus
目录
概要
源数据获取
写Python代码爬取数据
Scala介绍与数据处理
1.Sacla介绍 2.Scala数据处理流程
数据可视化
最终大屏效果
小结 概要 本文的主题是获取下厨房网站月度最佳栏目近十年数据,最终进行数据清洗、处理后生成所需的数据库表,最终进…
【Hadoop-Distcp】通过Distcp的方式进行两个HDFS集群间的数据迁移
【Hadoop-Distcp】通过Distcp的方式进行两个HDFS集群间的数据迁移 1)Distcp 工具简介及参数说明2)Shell 脚本 1)Distcp 工具简介及参数说明
【Hadoop-Distcp】工具简介及参数说明
2)Shell 脚本 应用场景: 两个实时集…
HDFS Java API 基本操作实验
文章目录 一、实验环境二、实验内容(一)数据准备(二)编程环境准备(三)使用Hadoop API操作HDFS文件系统(四)使用Hadoop API Java IO流操作HDFS文件系统 三、实验步骤(一&…
2023.11.22 -数据仓库
目录
https://blog.csdn.net/m0_49956154/article/details/134320307?spm1001.2014.3001.5501
1经典传统数仓架构
2离线大数据数仓架构
3数据仓库三层
数据运营层,源数据层(ODS)(Operational Data Store)
数据仓库层&#…
二百零七、Flume——Flume实时采集5分钟频率的Kafka数据直接写入ODS层表的HDFS文件路径下
一、目的
在离线数仓中,需要用Flume去采集Kafka中的数据,然后写入HDFS中。
由于每种数据类型的频率、数据大小、数据规模不同,因此每种数据的采集需要不同的Flume配置文件。玩了几天Flume,感觉Flume的使用难点就是配置文件
二、…
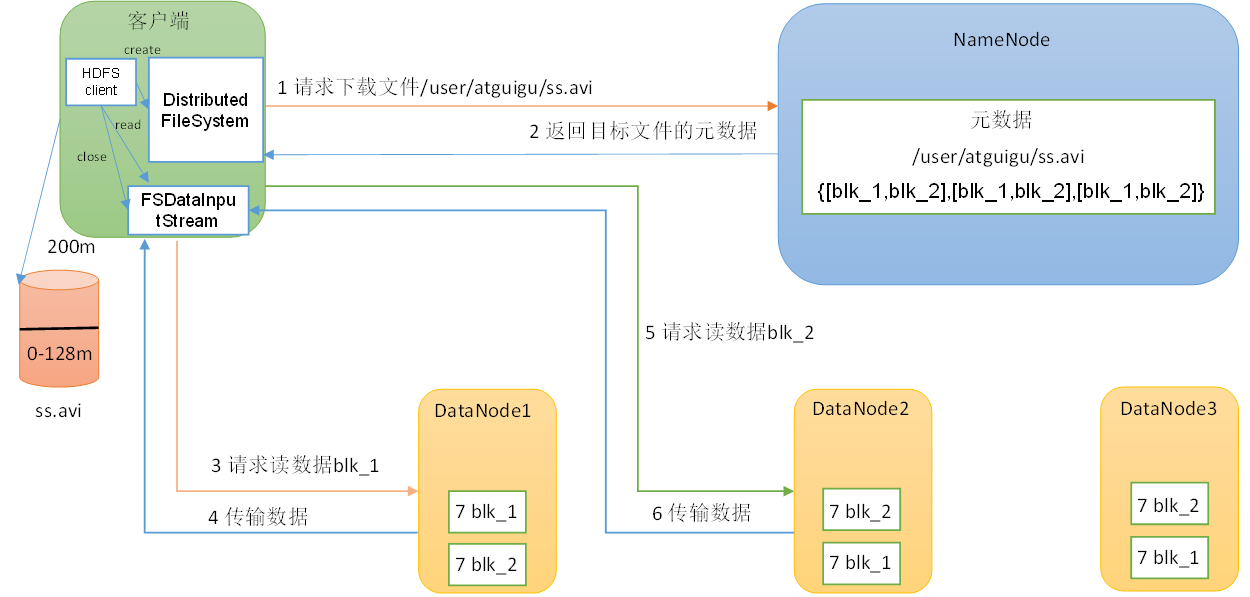
【Hadoop_04】HDFS的API操作与读写流程
1、HDFS的API操作1.1 客户端环境准备1.2 API创建文件夹1.3 API上传1.4 API参数的优先级1.5 API文件夹下载1.6 API文件删除1.7 API文件更名和移动1.8 API文件详情和查看1.9 API文件和文件夹判断 2、HDFS的读写流程(面试重点)2.1 HDFS写数据流程2.2 网络拓…
Centos安装Datax
Centos7安装DataX 一、DataX简介二、DataX的数据源支持三、安装DataX1、下载DataX2、解压3、检验是否安装成功4、使用 四、实践案例1、环境信息2、编写同步的配置文件(user_info.json)3、执行同步4、验证同步结果 一、DataX简介 DataX 是阿里云 DataWorks数据集成 的开源版本&a…
yarn集群HDFS datanode无法启动问题排查
一、问题场景
hdfs无法访问,通过jps命令查看进程,发现namenode启动成功,但是所有datanode都没有启动,重启集群(start-dfs.sh)后仍然一样 二、原因分析
先看下启动的日志有无报错。打开Hadoop的日志目录
…

MapReduce序列化实例代码
1 )需求:统计每个学号该月的超市消费、食堂消费、总消费 2 )输入数据格式 序号 学号 超市消费 食堂消费 18 202200153105 8.78 12 3 )期望输出格式 key (学号) value ( bean 对象…

HDFS 之 数据管理(namespace 和 slaves)
1、namespace
Namespace在HDFS中是一个非常重要的概念,也是有效管理数据的方法。Namespace有很多优点:可伸缩性。使HDFS集群存储能力可以轻松进行水平拓展;系统性能。单点性能受限,影响系统吞吐;隔离性。不同业务类型访问集群有时容易互相干扰,使用多Namespace可以有效管…
从wordcount词频统计代码到倒排索引的改编
从wordcount词频统计代码到倒排索引的改编 分析word count代码 Map中输出了单词和intwriteable类的对象one,而倒排索引,需要输出单词和文件名偏移,偏移是key中含有的,使用.tostring方法就可以将它变成字符串与文件名和连接。要输出…

【大数据】HDFS 的常用命令
HDFS 的常用命令 1.操作命令1.1 创建文件夹1.2 列出指定的文件和目录1.3 新建文件1.4 上传文件1.5 将本地文件移动到 HDFS1.6 下载文件1.7 查看文件1.8 追写文件1.9 删除目录或者文件1.10 显示占用的磁盘空间大小1.11 HDFS 中的文件复制1.12 HDFS 中的文件移动 2.管理命令2.1 报…
scala---spark本地调式远程获取hdfs数据注意事项
文章目录 前言一、Hadoop配置注意事项1.1 core-site.xml1.2 core-site.xml 二、本地hadoop环境配置注意事项三、本地scala项目spark代码调试总结 前言 这篇文章主要帮大家绕开一些本地使用spark调试获取远程hdfs数据的坑,个人在使用时也是基本把这些坑踩了一遍。希望…
Datanode Information无信息
原因是多次格式化namenode,查看/opt/module/hadoop-2.7.2/logs下的某个log文档可知,WARN org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Incompatible clusterIDs in /opt/module/hadoop-2.7.2/data/tmp/dfs/data: namenode clus…
一、Hadoop3.1.3集群搭建
一、集群规划
hadoop01(209.2)hadoop02(209.3)hadoop03(209.4)HDFSNameNode DataNodeDataNodeSecondaryNameNode DataNodeYARNNodeManagerResourceManager NodeManagerNodeManager NameNode和SecondaryNameNode不要放在同一台服务器上 二、创建用户
useradd atguigu
passwd *…
大数据技术原理与应用 期末复习 知识点全总结(林子雨版
目录 1.第一章 大数据概述:(一)三次信息化浪潮(二)人类社会数据产生方式的3个阶段(三)大数据的3个发展阶段(四)大数据4V概念(五)数据存储单位之间…

【解决】HDFS JournalNode启动慢问题排查
文章目录 一. 问题描述二. 问题分析1. 排查机器性能2. DNS的问题 三. 问题解决 一句话:因为dns的问题导致journalnode启动时很慢,通过修复dns对0.0.0.0域名解析,修复此问题。
一. 问题描述
从journalnode启动到服务可用,完成RPC…
【Hadoop】HDFS简介——是什么/优缺点/适用场景
HDFS是什么HDFS的优点/特性HDFS适用场景HDFS的缺点与不足HDFS 不适用场景 HDFS是什么
源自Google的GFS论文 Google于2003年10月发表HDFS是GFS的一个克隆版 HDFS(Hadoop Distributed File System) 是易于扩展的分布式文件系统。易扩展意味着如果文件系统大小不够可以增加节点运…
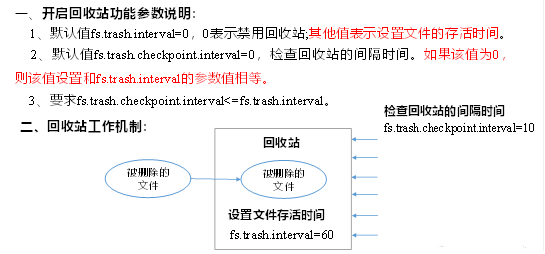
大数据技术之Hadoop(优化新特性)
第1章 HDFS—故障排除1.1 集群安全模式1)安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求2)进入安全模式场景NameNode在加载镜像文件和编辑日志期间处于安全模式NameNode再接收DataNode注册时,处于安…
【HDFS】调试慢节点pipiline ack信息
Client - DN1 - DN2 - DN3
DN3 send ack:[0][d3]。 DN2 send ack: [从dn2入队到收到dn3的ack耗时,0] [d2,d3]。 DN1 send ack: [pkt从dn1入队到收到dn2的ack耗时,pkt从dn2入队到收到dn3的ack耗时,0] [d1,d2,d3]。
Client receive: 就是DN1发送过来数据。 客户端收到的第一个…
hadoop一键启动脚本
Hadoop一键启动脚本
#!/bin/bash
jps>tmp.txt
NNcat tmp.txt|grep -w NameNode
DNcat tmp.txt|grep -w DataNode
SNNcat tmp.txt|grep -w SecondaryNameNode
RMcat tmp.txt|grep -w ResourceManager
NMcat tmp.txt|grep -w NodeManager
JHScat tmp.txt|grep -w JobHistoryS…
【HDFS】FsDatasetImpl系列文章(八):recoverRbw方法
前置文章: 【HDFS】BlockConstructionStage的几种状态:PIPELINE_SETUP_APPEND、PIPELINE_SETUP_CREATE、TRANSFER_RBW等
一、调用点&调用场景
只有一处调用点,在BlockReceiver的构造方法里:
isClient(来自Client的写数据请求,不是数据块复制或者balancer的情况)的…

大数据 | (六)Hadoop集群启停脚本
知识目录 一、前言二、Hadoop集群启停脚本2.1 启停脚本及其背景2.2 使用方法 三、jps脚本四、关机脚本五、结语 一、前言
hello,大家好!这篇文章是我在使用Hadoop集群时使用到的启停脚本的详细内容与感想,希望能帮助到大家!
本篇…

hdfs集群的扩容和缩容
文章目录1、背景2、集群黑白名单3、准备一台新的机器并配置好hadoop环境3.1 我们现有的集群规划3.2 准备一台新的机器3.2.1 查看新机器的ip3.2.2 修改主机名和host映射3.2.3 配置时间同步3.2.4 关闭防火墙3.2.5 新建hadoop部署用户3.2.6 复制hadoop04机器上的/etc/hosts文件到集…
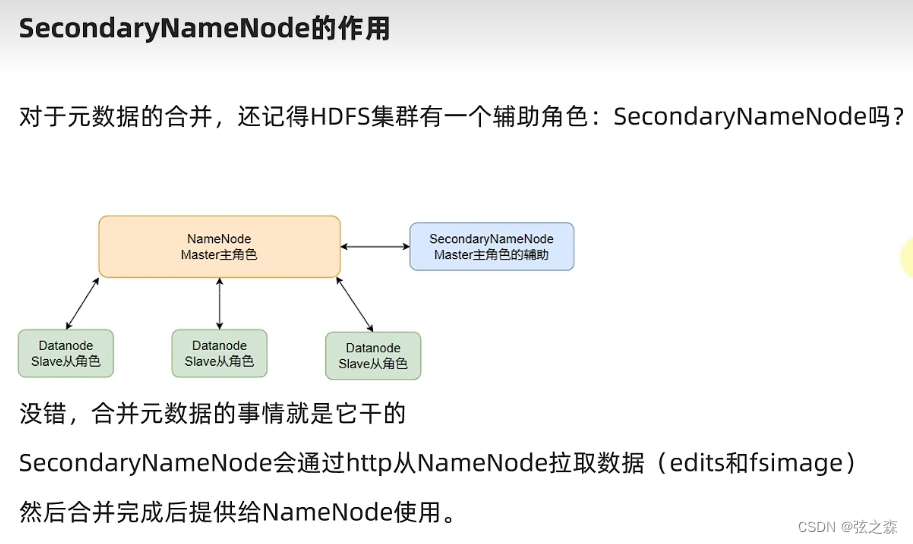
九、hdfs中Namenode元数据处理
1、元数据的由来 在hdfs文件系统中,用户的每一次操作,都会对文件系统产生响应的影响,那么谁来记录这些影响呢? 在hdfs文件系统中,edits文件记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block。…

用Sqoop把数据从HDFS导入到关系型数据库
由于工作的需求,需要把HDFS中处理之后的数据转移至关系型数据库中成为对应的Table,在网上寻找有关的资料良久,发现各个说法不一,下面是本人自身测试过程:
使用Sqoop来实现这一需求,首先要明白Sqoop是什么&…
HDFS NFS Gateway(环境配置,超级详细!!)
🐮博主syst1m 带你 acquire knowledge! ✨博客首页——syst1m的博客💘 😘《CTF专栏》超级详细的解析,宝宝级教学让你从蹒跚学步到健步如飞🙈 😎《大数据专栏》大数据从0到秃头👽&…
大数据 | (五)通过Sqoop实现从MySQL导入数据到HDFS
知识目录 一、前言二、导入前的准备2.1 Hadoop集群搭建2.2 Hadoop启停脚本 三、docker安装MySQL四、安装Sqoop4.1 Sqoop准备4.2 Sqoop连接Mysql数据测试 五、导入MySQL数据到hdfs5.1 准备MySQL数据5.2 导入数据 六、Sqoop现状七、结语 一、前言
各位CSDN的朋友们大家好&#x…
【HDFS】DFSPacket中lastPacketInBlock字段的关键作用
这篇文章介绍了DFSPacket对象的lastPacketInBlock字段相关的知识。 【HDFS Client】DFSPacket对象什么情况下是lastPacketInBlock?
本文继续深挖lastPacketInBlock这个字段在HDFS Client写数据时的重要作用。
可以这么说,如果这个lastPacketInBlock出问题的话,是会影响增量…

HDFS学习笔记 【Namenode/DN管理】
说明
DN管理管理了什么? NN上如何表示DN DN存储和块的关系 梳理DatanodeManager存储类
DatanodeDescriptor
DN的抽象,依次继承。每一层增加一点额外的信息。 DatanodeId 基本的DN信息,hostname,数据传输接口,info服…
Spark系列文章 Spark3部署,java实现Pi、WordCount程序,任务部署到yarn
Spark系列文章 java实现Pi、WordCount任务程序部署到yarnApache Spark 部署Spark下载上传,解压运行spark-shell配置Spark使用yarn做资源管理让我们先把yarn可调度的资源范围调大一些配置yarn对节点内存的管理范围配置spark与yarn的连接运行一个example检测配置的情况…
大数据Hadoop入门——HDFS分布式文件系统基础
HDFS总结
在现代的企业环境中,海量数据超过单台物理计算机的存储能力,分布式文件系统应运而生,对数据分区存储于若干物理主机,管理网络中跨多台计算机存储的文件系统。
HDFS只是分布式文件管理系统中的一种。
HDFS命令 基础语法…

一百六十八、Kettle——用海豚调度器定时调度从Kafka到HDFS的任务脚本(持续更新追踪、持续完善)
一、目的
在实际项目中,从Kafka到HDFS的数据是每天自动生成一个文件,按日期区分。而且Kafka在不断生产数据,因此看看kettle是不是需要时刻运行?能不能按照每日自动生成数据文件?
为了测试实际项目中的海豚定时调度从…
Scala学习系列(一)——Scala为什么是大数据第一高薪语言
为什么是Scala
虽然在大数据领域Java的使用更普及,Python也有后来居上的势头,但Scala一直有着不可动摇的地位。我们熟悉的Spark,Kafka,Flink都是由Scala完成了其核心代码的开发。
所以掌握Scala不仅可以学习大数据组件的源码&am…
Sqoop1.99.7安装、配置和使用(二)
转载请注明出处:http://blog.csdn.net/u012842205/article/details/52346595 本文将接上文,记录Sqoop1.99.7基本使用。这里我们使用sqoop2将MySQL中的一个数据表导出到HDFS,都是最简单的使用。 请确保Sqoop2服务器已经启动,并确保…
修炼k8s+flink+hdfs+dlink(三:安装dlink)
一:mysql初始化。
mysql -uroot -p123456
create database dinky;
grant all privileges on dinky.* to dinky% identified by dinky with grant option;
flush privileges;二:上传dinky。
上传至目录/opt/app/dlink
tar -zxvf dlink-release-0.7.4.t…
搭建Hadoop2.9伪分布集群环境
搭建Hadoop2.9伪分布集群环境
自己创建一个普通用户,用普通用户登录或者用root登录也可以的,具体根据公司的要求来
systemctl stop firewalld
systemctl disable firewalld
useradd hadoop1 #我创建的用户是hadoop
passwd hadoop1 #这里输入用户hadoop…

JavaClient With HDFS
序言
在使用Java创建连接HDFS的客户端时,可以设置很多参数,具体有哪些参数呢,只要是在部署HDFS服务中可以设置的参数,都是可以在连接的时候设置. 我没有去验证所有的配置是否都可以验证,只是推测cuiyaonan2000163.com 依据
创建HDFS的构造函数如下所示: 网上比较常用的是get…

记一次 Flink 作业启动缓慢
记一次 Flink 作业启动缓慢
背景
应用发现,Hadoop集群的hdfs较之前更加缓慢,且离线ELT任务也以前晚半个多小时才能跑完。此前一直没有找到突破口所以没有管他,推测应该重启一下Hadoop集群就可以了。今天突然要重启一个Flink作业,…
大数据技术之Hadoop:HDFS存储原理篇(五)
目录
一、原理介绍
1.1 Block块
1.2 副本机制
二、fsck命令
2.1 设置默认副本数量
2.2 临时设置文件副本大小
2.3 fsck命令检查文件的副本数
2.4 block块大小的配置
三、NameNode元数据
3.1 NameNode作用
3.2 edits文件
3.3 FSImage文件
3.4 元素据合并控制参数
…

自学大数据第六天~HDFS命令(一)
HDFS常用命令
查看hadoop版本 version
hadoop version注意,没有 ‘-’
[hadoopmaster ~]$ hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:3…
分布式架构设计HDFS借鉴思考 GPT
分布式架构设计HDFS借鉴思考
HDFS(Hadoop Distributed File System)的主要设计思路 HDFS(Hadoop Distributed File System)的主要设计思路是将大数据文件划分成小的数据块,并存储在多个节点上,以实现数据的…
和gpt聊天,学一手hdfs
我把聊天中间的主题,用标题标出来了,可以跳转直接观看,纯小白的求知道路。
目录 文章目录 目录[toc] 计划学习**主题**: 1.1 HDFS概述**问题**: 他和mysql有什么区别**主题**: 1.1 HDFS概述HDFS 的设计和工作原理选择最佳的 DataNode策略配置…
Hadoop入门案例
Hadoop的运行流程:
客户端向HDFS请求文件存储或使用MapReduce计算。NameNode负责管理整个HDFS系统中的所有数据块和元数据信息;DataNode则实际存储和管理数据块。客户端通过NameNode查找需要访问或处理的文件所在的DataNode,并将操作请求发送…
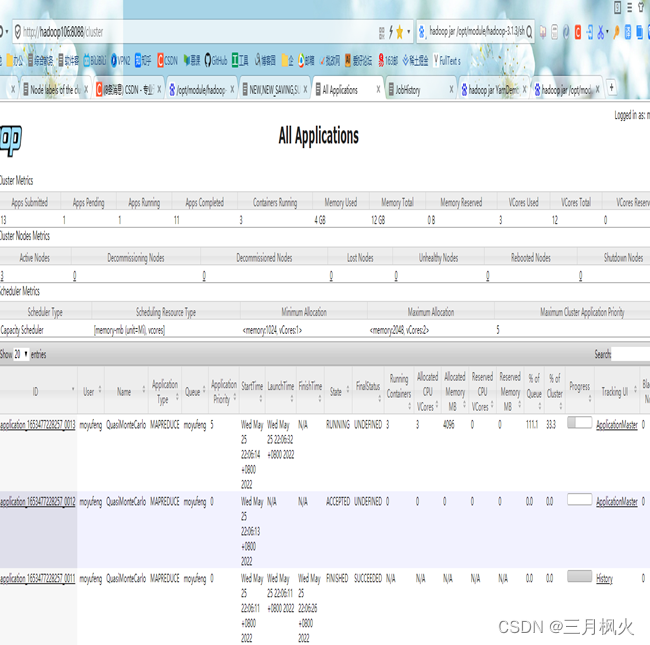
Hadoop集群环境搭建与应用回顾
文章目录一、 实训项目名称二、 学习情况小结三、 项目中用到的知识点四、 实训项目中负责功能板块五、 实训项目实现六、 实训项目过程中遇到的问题及解决方法七、实训体会与心得一、 实训项目名称
Hadoop集群环境搭建与应用
二、 学习情况小结
实操一部分:
通…
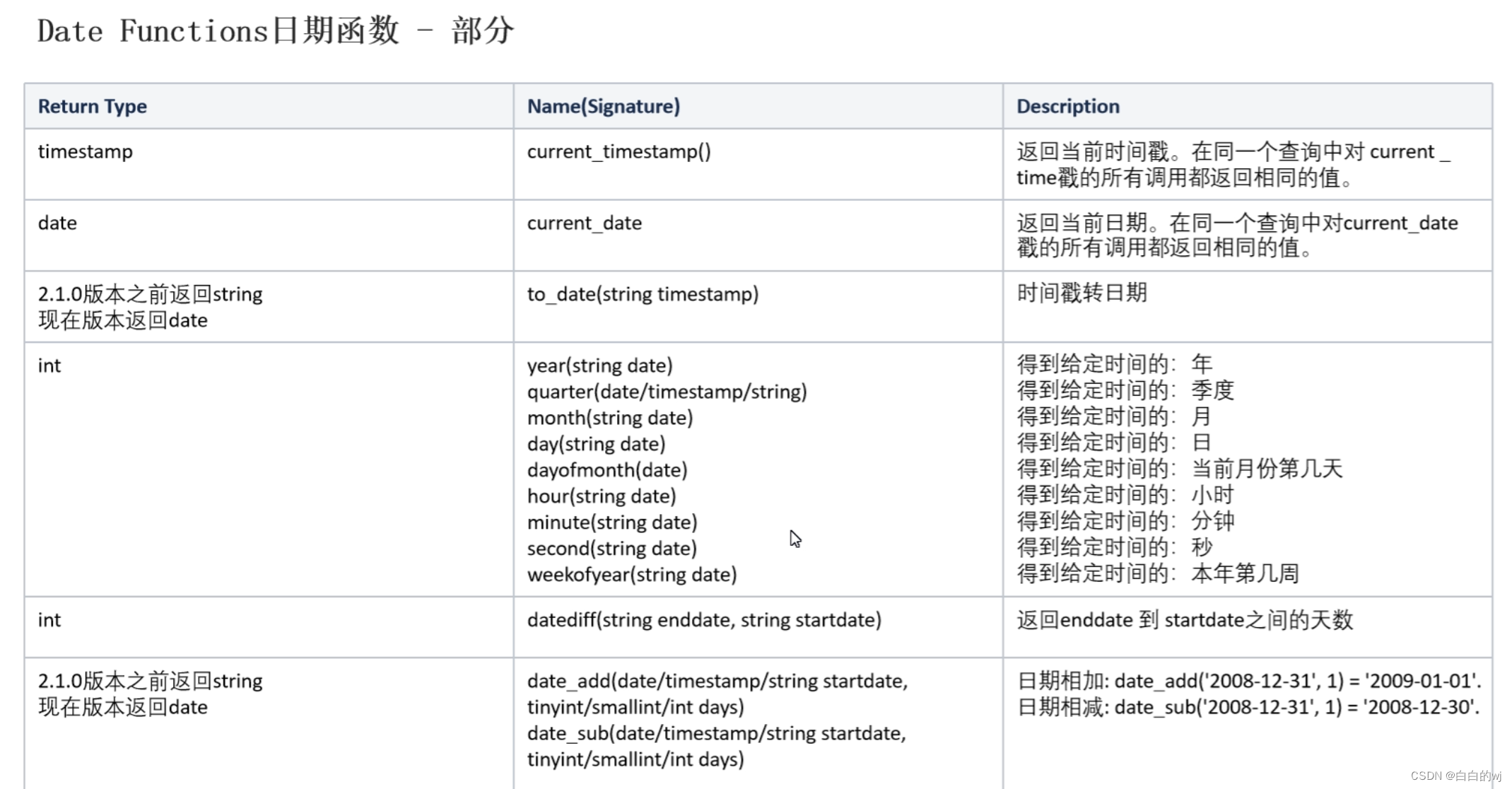
2023.11.15 hive sql之函数标准,字符串,日期,数学函数
目录 一.函数分类标准
二.查看官方函数,与简单演示
三.3种类型函数演示
四.字符串函数
1.常见字符串函数
2.索引函数 解析函数
五.日期函数 1.获取当前时间 2.获取日期相关 3.周,季度等计算
4.时间戳
六.数学函数 一.函数分类标准
目前hive三大标准 UDF:(…
hadoop wind主机不能访问虚拟机部署的hadoop
1.查看hadoop是否启动成功:通过jps我们能够看到hadoop启动正常 2.虚拟机里面能否正常访问:9870端口,虚拟机能够通过localhost:9870正常访问 3.查看虚拟机与主机能否ping,telnet通
wind主机能够ping通 telnet 192.168.0.7 9870 发现不能够链…

十六、YARN和MapReduce配置
1、部署前提
(1)配置前提
已经配置好Hadoop集群。
配置内容: (2)部署说明 (3)集群规划 2、修改配置文件
MapReduce
(1)修改mapred-env.sh配置文件
export JAVA_HOM…

【大数据之Hive】九、Hive之DDL(Data Definition Language)数据定义语言
1 数据库
[ ] 里的都是可选的操作。
1.1 创建数据库
语法:
create database [if not exists] database_name
[comment database_comment(注释)]
[location hdfs_path]
[with dbproperties (property_name-propertyproperty_value,...)]; 如:
creat…
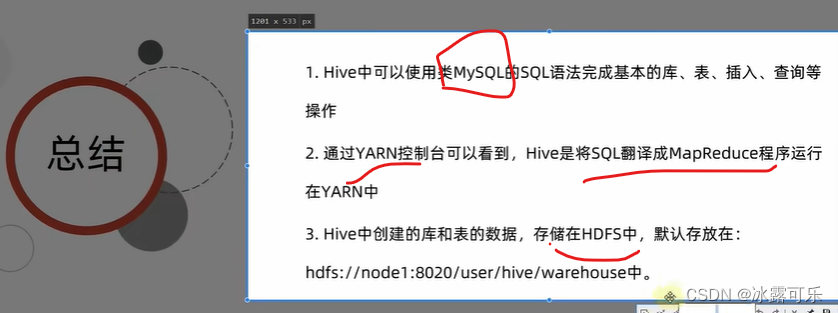
大数据:Apache hive分布式sql计算平台,hive架构,hive部署,hive初体验
大数据:Apache hive分布式sql计算平台
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle&a…
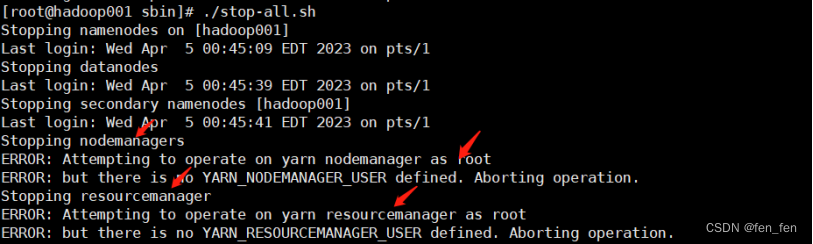
Centos7安装Hadoop3.3.1(单机版本)
前提:需要安装好JDK,需要配置ssh免密(可参考问题2的设置)
1、下载Hadoop
打开Hadoop下载地址,下载3.3.1版本
下载:wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
2、Hadoop安装
配…
Hadoop启动相关命令
Hadoop启动相关配置 文章目录Hadoop启动相关配置格式化节点的情况什么情况下Hadoop需要进行格式化节点?Hadoop启动步骤Hadoop的启动步骤只是start-dfs.sh即可吗*hdfs*的web管理页面参数说明参数的评价场景格式化节点的情况
什么情况下Hadoop需要进行格式化节点&…

从零开始的Hadoop学习(六)| HDFS读写流程、NN和2NN工作机制、DataNode工作机制
1. HDFS的读写流程(面试重点)
1.1 HDFS写数据流程
1.1.1 剖析文件写入 (1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
&#x…
Spark 广播/累加
Spark 广播/累加广播变量普通变量广播分布式数据集广播克制 Shuffle强制广播配置项Join Hintsbroadcast累加器Spark 提供了两类共享变量:广播变量(Broadcast variables)/累加器(Accumulators)
广播变量
创建广播变量…
HDFS HA 之 HA 原理
1 ZKFC解析
HA(High Availability)是HDFS支持的一个重要特性,可以有效解决Active Namenode遇到故障时,将可用的Standby节点变成新的Active状态的问题,使集群能够正常工作。目前支持冷切换和热切换两种方式。冷切换通过手动触发,缺点是不能够及时恢复集群。实际生产中以应用…

2023.11.17 hadoop之HDFS进阶
目录
HDFS的机制
edits和fsimage文件
HDFS的存储原理
写入数据原理:
读取数据原理:
元数据简介
元数据存储流程
HDFS安全机制
HDFS归档机制
HDFS垃圾桶机制 接着此前的内容
https://blog.csdn.net/m0_49956154/article/details/134298109?spm1001.2014.3001.5501
…
快速搭建kerberos认证的HDFS环境
1)、搭建hdfs单机服务器搭建
2)、kdc单机kerberos认证
我的服务器:192.168.1.166
1、安装kerberos
1.1 执行命令:yum -y install krb5-libs krb5-server krb5-workstation
1.2 修改host文件:vim /etc/hosts,加入 192.168.1.166 myli 192.168.1.166 kerberos.example.co…
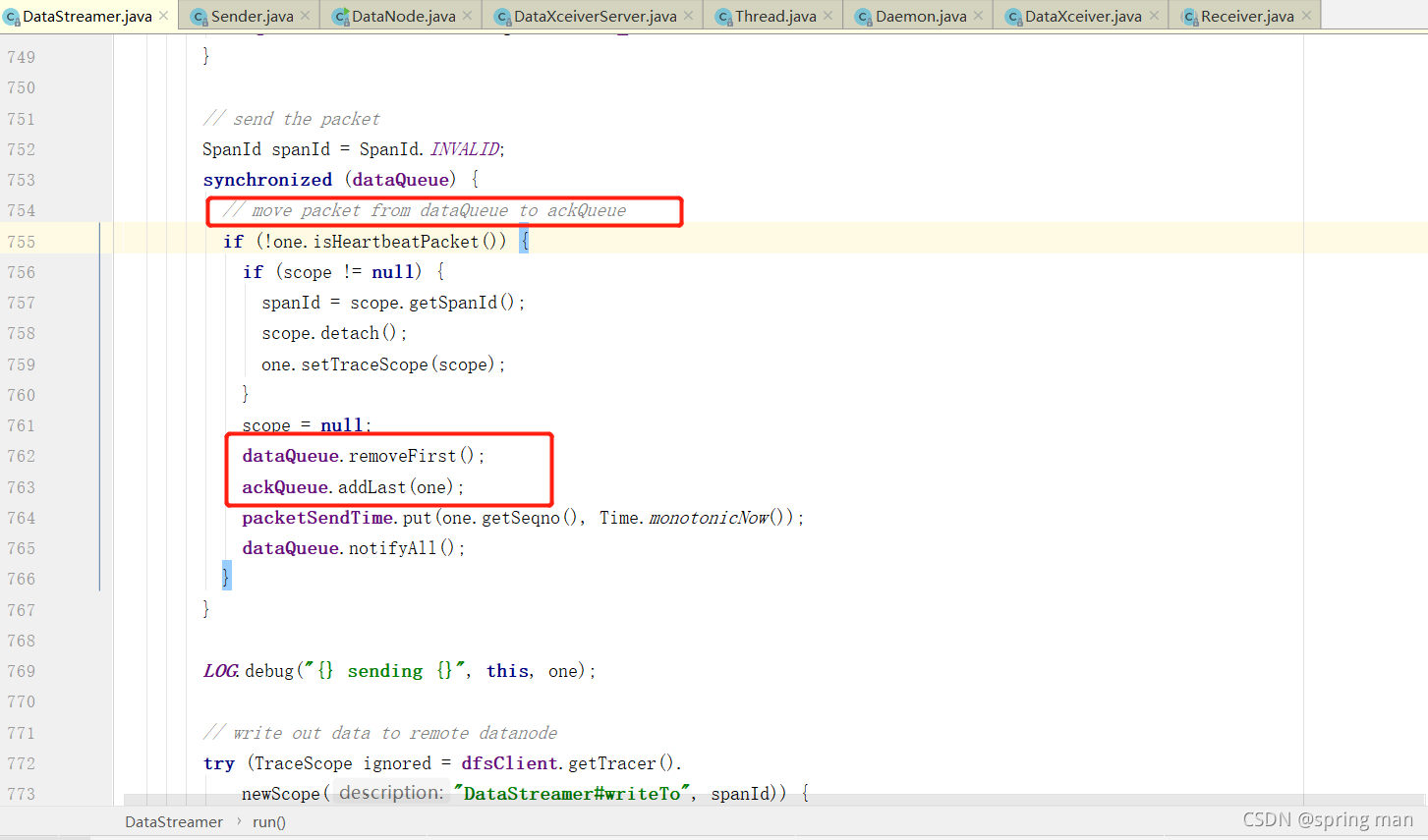
Doris数据导入和导出
数据导入
broker load
Broker 导入,主要用于从HDFS上把文件导入到Doris中。这是一个异步导入的方式。(任务执行成功并不代表数据全部都导入成功)
前提:启动HDFS。
案例演示:
--创建表
CREATE TABLE test_db.user_…
2.5 HDFS环境搭建
2.5 HDFS环境搭建 下载jdk 和 hadoop 放到 ~/software目录下 然后解压到 ~/app目录下 tar -zxvf 压缩包名字 -C ~/app/配置环境变量 vi ~/.bash_profile
export JAVA_HOME/home/hadoop/app/jdk1.8.0_91
export PATH$JAVA_HOME/bin:$PATH
export HADOOP_HOME/home/hadoop/app/ha…
HDFS 之 Topology(Rack) Awareness - 机架感知
1、 简介
机架感知在大型分布式存储系统中非常实用,可以有效保证数据的高可用,同时提升集群稳定性。在HDFS中,也实现了类似Topology Awareness的机制,只不过是采用软件的方式模拟。
2、机架感知存在的意义 分布式存储系统的一个特殊之处在于其通常包含非常多的机器。Clie…
滚动升级HDFS HA cluster
文章目录滚动升级HDFS cluster升级步骤滚动升级HDFS cluster
前言
1、首先需要是一个HA HDFS,即最少有两个namenode,否则不能进行滚动升级2、一般journalnode和zookeeper非常稳定,不需要升级。如果升级这两个组件则需要停机。
升级步骤
创…

大数据编程实验一:HDFS常用操作和Spark读取文件系统数据
大数据编程实验一:HDFS常用操作和Spark读取文件系统数据 文章目录大数据编程实验一:HDFS常用操作和Spark读取文件系统数据一、前言二、实验目的与要求三、实验内容四、实验步骤1、HDFS常用操作2、Spark读取文件系统的数据五、最后我想说一、前言
这是我…
docker搭建hadoop集群 个人总结
1.搭建过程
https://dblab.xmu.edu.cn/blog/1233/ https://www.cnblogs.com/rmxd/p/12051866.html#_label4 按照这两篇文章即可,总结来说 pull ubuntu,进入系统,配置java、hadoop,保存镜像。然后根据这个镜像启动三个容器master&…
Hadoop运行模式
hgfhfg
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:Apache Hadoop 一、本地运行模式 官方Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹 mkdir input
2. 将Hadoop的xml配置文件复制到input cp et…
云计算-Hadoop-2.7.7 最小化集群的搭建(3台)
云计算-Hadoop-2.7.7 最小化集群的搭建(3台) 文章目录云计算-Hadoop-2.7.7 最小化集群的搭建(3台)一、环境依赖下载二、部署概要三、hadoop101模板机配置1. 更新 & 升级2. 安装好用的vim VimForCpp3. 安装必要依赖4. 关闭防火…
数据同步工具DataX从Mysql同步数据到HDFS实战
目录1. 查看数据同步模板2. 高可用HA的HDFS配置3. MysqlReader针对Mysql类型转换说明4. HdfsWriter支持大部分Hive类型5. Mysql准备数据如下6. 新建job/mysql2hdfs.json7. 执行job8. 查看hdfs的文件1. 查看数据同步模板
我自己在下面的模板文件中添加了一些说明注释
[rootbig…

【大数据入门核心技术-Ambari】(一)Ambari介绍
一、什么是Ambari Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。 Apache Ambari 支持HDFS、MapReduce、Hive、Pi…

Hadoop HDFS的主要架构与读写文件
一、Hadoop HDFS的架构
HDFS:Hadoop Distributed File System,分布式文件系统
1,NameNode
存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小一个Block在…

大数据|HDFS分布式文件系统
前文回顾:Hadoop系统 目录
📚HDFS概述
📚HDFS设计目标
📚HDFS的架构
📚HDFS的副本机制 📚HDFS概述 在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理…
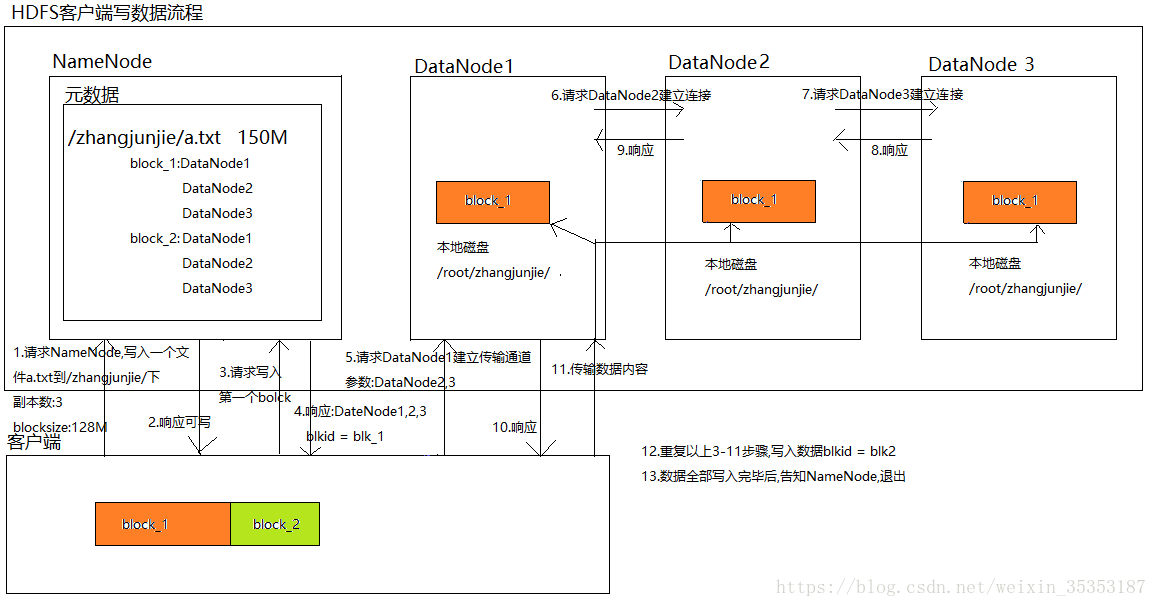
彷徨 | HDFS的安全模式
HDFS运行机制、原理深入
namenode的安全模式:
namenode一旦进入安全模式,就无法再操作hdfs中的文件(上传、删除、改名、下载),只是可以查看目录
namenode进入安全模式的原因:
namenode机器的资源问题(磁…

hadoop理论基础(一)
1.hadoop的组成2 HDFS概述HDFS(Hadoop Distributed File System)是一个分布式文件系统(1)NameNode:存储文件的元数据;如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的DataNode等。(2)DataNode:在本地…
YARN统一资源管理
YARN统一资源管理 Apache YARN即Yet Another Resource Negotiator,是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台…
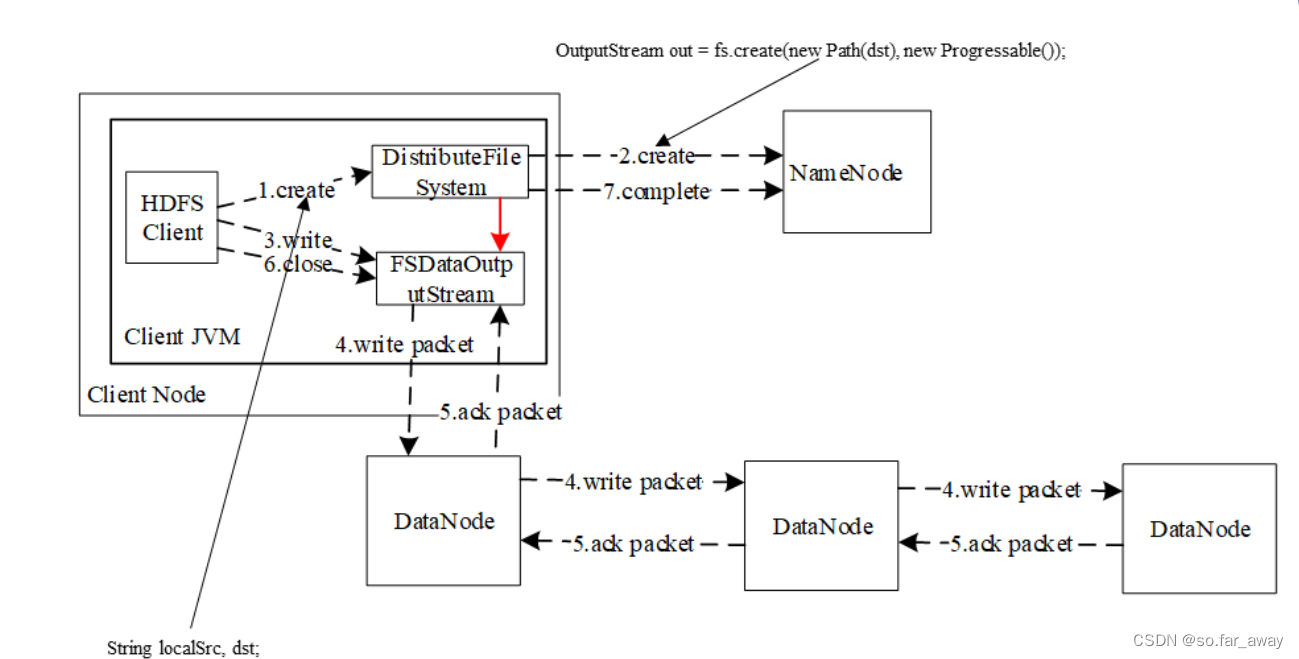
分布式文件系统HDFS的多问多答
分布式文件系统HDFS 简述HDFS的优缺点简述HDFS的体系结构请论述HDFS中SecondaryNameNode的作用和工作原理请论述HDFS写数据原理 简述HDFS的优缺点 HDFS的优良特性: ①兼容廉价的硬件设备。在成百上千台廉价服务器中存储数据,常会出现节点失效的情况&…

0201hdfs集群部署-hadoop-大数据学习
文章目录 1 前言2 集群规划3 hadoop安装包上传与安装3.1 上传解压 4 hadoop配置5 从节点同步和环境变量配置6 创建用户7 集群启动8 问题集8.1 Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority. 结语 1 前言
下面我们配置下单namenode节点h…
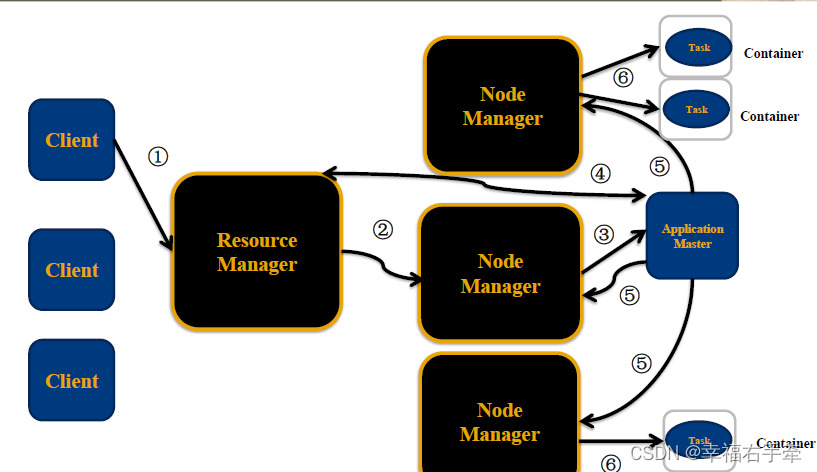
Hadoop基础介绍
Hadoop基础介绍一、总体介绍二、HDFS架构三、MapReduce结构四、YARN架构一、总体介绍
1、定义: 是一个开源的、可靠的、可扩展的分布式计算框架。
2、用途: (1)数据仓库 (2)PB级别数据的存储与处理。
3…
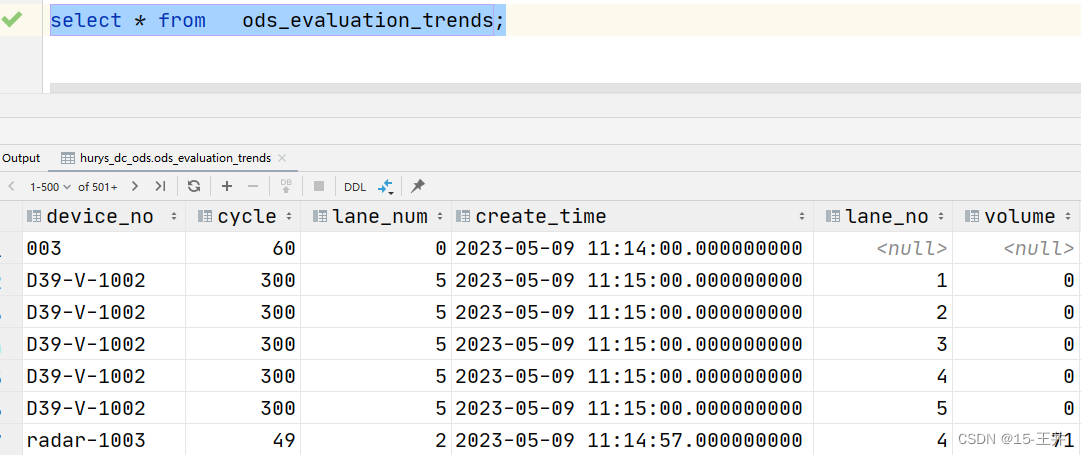
一百一十一、Hive——从HDFS到Hive的数据导入(静态分区、动态分区)
一、分区的定义 分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹, Hive 中的分区就是分目录 ,把一个大的数据集根据业务需要分割成小的数据集。 在查询时通过 where 子句中的表达式选择查询所需要的指定的分区,这样的查询效率 会…
大数据地阶斗技--HDFS java API编程
目录
一.获取文件系统
二.列出所有DataNode的名字信息
三.创建文件目录
四.删除文件或文件目录
五.查看文件是否存在
六.文件上传至HDFS
七.从HDFS下载文件
八.文件重命名
九.遍历目录和文件
十.获取数据块所在的位置
十一.根据filter获取目录下的文件 一.获取文件系…

阿里云异构数据源离线同步工具之DataX
阿里云异构数据源离线同步工具之DataXDataXDataX概述框架设计插件体系核心架构更多介绍安装DataX系统要求下载与安装DataX基本使用1.官方演示案例2.从stream读取数据并打印到控制台查看配置模板创建作业配置文件启动DataX3.从MySQL抽取数据到HDFS获取配置模板创建作业配置文件启…
Hadoop学习篇(二)——HDFS编程操作2
上篇链接:
Hadoop学习篇(二)——HDFS编程操作1
Hadoop学习篇(二)——HDFS编程操作2
说明:如涉及到侵权,请及时联系我,并在第一时间删除文章。
2.3.2 编程操作
HDFS的编程操作,实际上就是用高级语言模拟HDFS的命令…


CDH6.3.2大数据集群生产环境安装(八)之各组件参数调优,yarn参数调优,hdfs参数调优等
yarn资源调优 主要涉及到了ResourceManager、NodeManager这几个概念,相关的优化也要紧紧围绕着这几方面来开展。这里还有一个Container的概念,现在可以先把它理解为运行map/reduce task的容器 28.1. 内存 堆栈等配置 原值 调优值
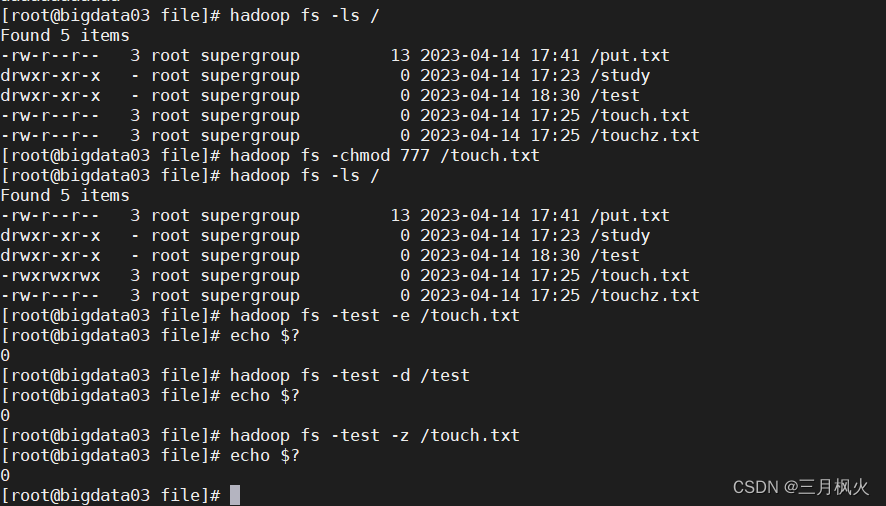
【Hadoop】Hadoop概念与实践
Hadoop是一个由Apache基金会开发的开源分布式计算框架,在处理大数据方面非常有用。它可以存储和处理大规模数据集,通过使用多台计算机构建集群,将数据分散到集群中的节点上进行处理。
Hadoop由两个核心组件组成: Hadoop Distribu…
centos7 | hdfs的web端下载报错 | 本地可以新建目录、上传文件、跑examples、查看output结果;web端可以查看文件目录;唯独不能从web端下载
前言:如题,系统cenos7。 小白,第一次学习配置hdfs,单节点: 按老师示范的顺序,完成了hadoop-env.sh文件中设置Java的绝对路径,修改core-site.xml,hdfs-site.xml。 第一次启动格式化了…
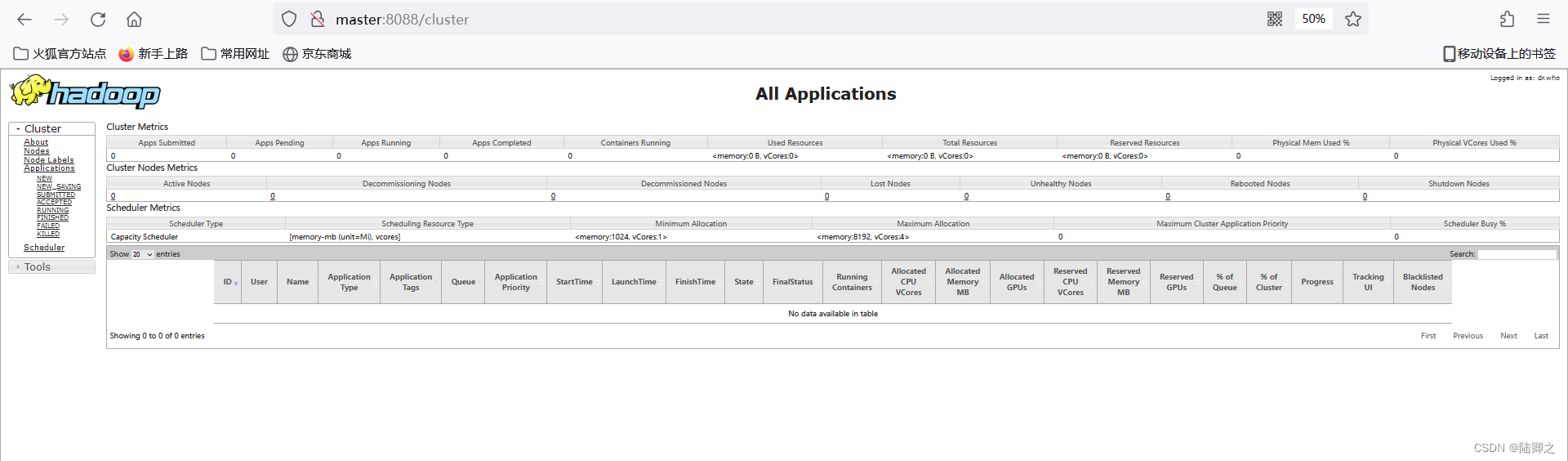
搭建hadoop集群
搭建Hadoop集群
1,准备环节
Hadoop完全分布式集群式(master/slave)主从架构。 因为Hadoop是由java编写的,所以需要Java的环境支持,作为开发者我们需要安装jdk。
安装jdk的教程http://t.csdn.cn/6qJKg
下载Hadoop的…
基於Hadoop HA 在kerberos中配置datax
概要 提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 概要 前言一、基於HADOOP HA 搭建datax二、基於HADOOP HA 配置好的datax去配置kerberos1.在datax的配置文件中進行配置2.在shell腳本中加入認證語句 总结 前言…
HDFS写流程源码分析(一)-客户端
HDFS 写流程源码分析 一、客户端(一)文件创建及Pipeline构建阶段(二)数据写入(三)输出流关闭 二、NameNode端(一)create(二)addBlock 环境为hadoop 3.1.3 一、…
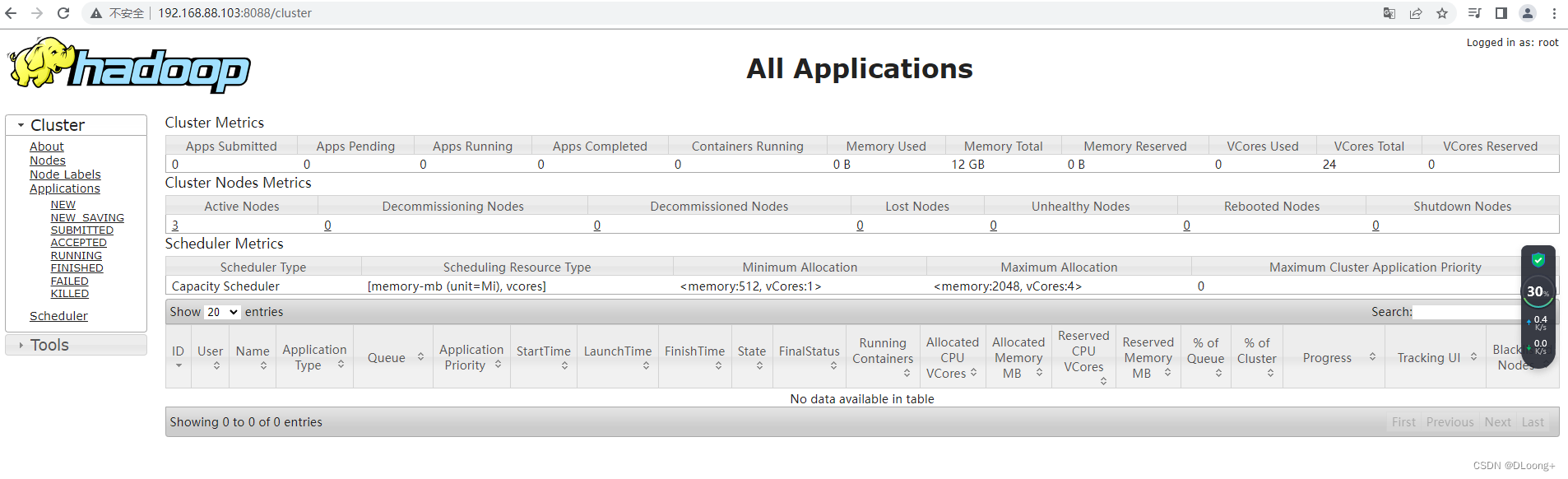
Docker搭建Hadoop集群
目录
1.拉取centos镜像
2.基础镜像配置(基于centos构建hadoopbase镜像)
3.集群环境配置
1.创建3个容器
2.配置网络
3.配置主机和ip的映射关系
4.配置3个节点的免密登录
4.搭建hadoop集群
1.安装hadoop
2.修改配置文件
3.分发Hadoop及配置文件my_env.sh
5.启动集群 …
StarRocks案例7:使用shell批量broker load导入hdfs数据
文章目录 一. 问题描述二. 解决方案 一. 问题描述
近期需要进行补录数据,需要将hive的历史数据迁移到StarRocks,因为需要补录的数据较多,hive和StarRocks均使用的是分区表,两边的日期格式也不同,hive这边是 yyyymmdd格…

【HDFS】Hadoop的分布式文件系统知识点总结
>_< 首先,我们需要从整体上了解什么是分布式文件系统 >_<。 分布式文件系统把文件存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。 计算机集群听着高大上,其实是由普通廉价硬件组成,硬件开销是极低的…
【大数据Hadoop】HDFS3.3.1-Namenode系列源码阅读
Namenode功能前言文件系统目录树数据块管理Datanode管理租约管理缓存管理前言
HDFS集群是以Master/Slave模式运行的,主要有两类节点:Namenode和Datanode。其中Namenode是HDFS的主节点。
对于 Namenode 的功能,主要有如下几点:
文件系统目录…

大数据框架Hadoop篇之Hadoop入门
1. 写在前面
今天开始,想开启大数据框架学习的一个新系列,之前在学校的时候就会大数据相关技术很是好奇,但苦于没有实践场景,对这些东西并没有什么体会,到公司之后,我越发觉得大数据的相关知识很重要&…
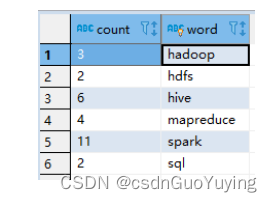
【Spark分布式内存计算框架——Spark Core】7. RDD Checkpoint、外部数据源
第五章 RDD Checkpoint
RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint的产生就是…
《Hadoop篇》------大数据及Hadoop入门
目录
一、大数据及Hadoop入门
1.1 单节点、分布式、集群
1.1.1 大数据的概念
1.1.2 大数据的本质
二、HDFS Shell命令
2.1、常用相关命令
2.2、上传文件
2.2.1、上传文件介绍
2.2.2上传文件操作
2.3、下载文件
2.4、删除文件
2.5、创建目录
2.6、查看文件系统
2.…
【Shell-HDFS】使用Shell脚本判断HDFS文件、目录是否存在
【Shell-HDFS】使用Shell脚本判断HDFS文件、目录是否存在 1)文档编写目的2)测试原理3)Shell脚本测试3.1.测试路径是否存在3.2.测试目录是否存在3.3.测试文件是否存在3.4.测试路径大小是否大于03.5.测试路径大小是否等于0 4)总结 1…
HDFS文件常用操作
弄了段时间hadoop的HDFS,用了些常用的HDFS文件操作,Java实现记录如下,以作Demo:
/**
* Title: uploadLocalFileToHDFS
* Description: 单个本地文件拷贝到HDFS
* param param localPath 本地文件路径
* param param hdfsPath HDF…

02Hadoop环境搭建
版本
hadoop-3.1.3.tar.gz解压安装文件到/opt/module下面
[sarahhadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/将Hadoop添加到环境变量 (1)获取Hadoop安装路径
[sarahhadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3&…
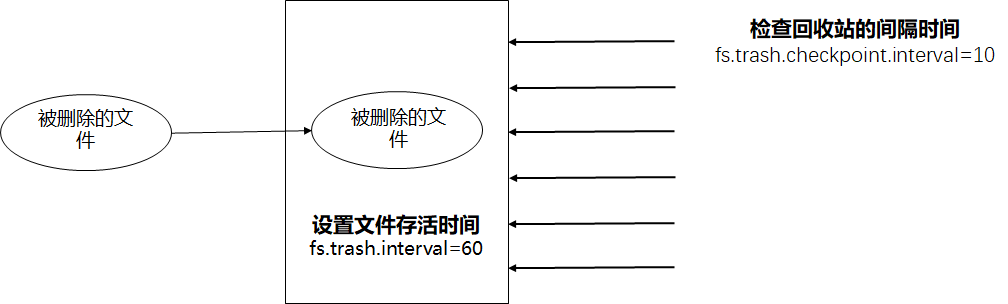
大数据框架之Hadoop:HDFS(七)HDFS 2.X新特性
7.1集群间数据拷贝
scp实现两个远程主机之间的文件复制
scp -r hello.txt roothadoop103:/root/hello.txt // 推 push
scp -r roothadoop103:/root/hello.txt hello.txt // 拉 pull
scp -r roothadoop103:/root/hello.txt roothadoop104:/root //是通过本地主机中…
测试环境搭建整套大数据系统(三:搭建集群zookeeper,hdfs,mapreduce,yarn,hive)
一:搭建zk https://blog.csdn.net/weixin_43446246/article/details/123327143 二:搭建hadoop,yarn,mapreduce。
1. 安装hadoop。
sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt2. 修改java配置路径。
cd /opt/hadoop-3.2.4/etc…

WPF 附加属性+控件模板,完成自定义控件。建议观看HandyControl源码
文章目录 相关连接前言需要实现的效果附加属性添加附加属性,以Test修改FontSize为例依赖属性使用触发器使用直接操控 结论 控件模板,在HandyControl的基础上面进行修改参考HandyControl的源码控件模板原型控件模板 结论 相关连接 WPF控件模板(6) WPF 附加…
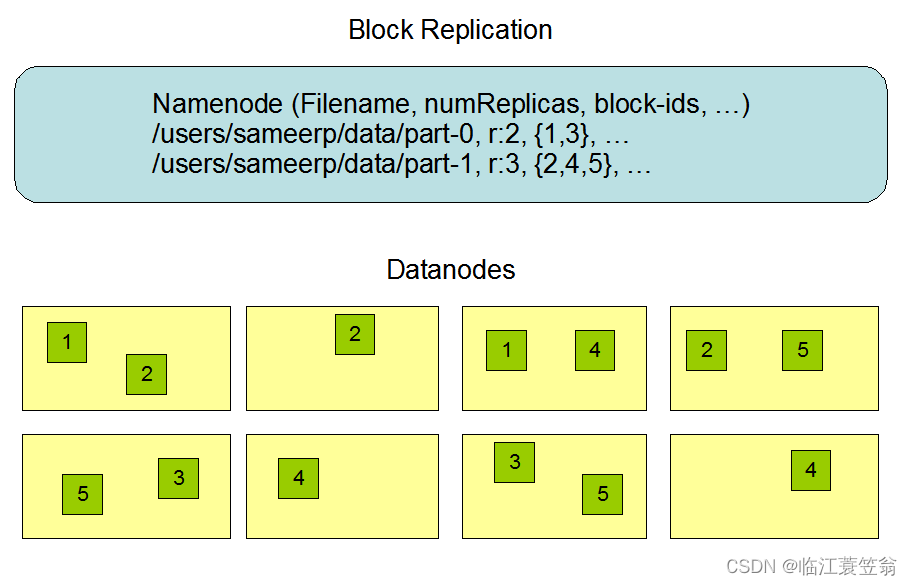
Hadoop-HDFS架构与设计
HDFS架构与设计 一、背景和起源二、HDFS概述1.设计原则1.1 硬件错误1.2 流水访问1.3 海量数据1.4 简单一致性模型1.5 移动计算而不是移动数据1.6 平台兼容性 2.HDFS适用场景3.HDFS不适用场景 三、HDFS架构图1.架构图2.Namenode3.Datanode 四、HDFS数据存储1.数据块存储2.副本机…

十八、本地配置Hive
1、配置MYSQL
mysql> alter user rootlocalhost identified by Yang3135989009;
Query OK, 0 rows affected (0.00 sec)mysql> grant all on *.* to root%;
Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)2、…
Kafka下沉到HDFS报错
错误信息
24 十二月 2023 12:38:25,127 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.HDFSCompressedDataStream.configure:64) - Serializer TEXT, UseRawLocalFileSystem false 24 十二月 2023 12:38:25,129 ERROR [SinkRunner-Pol…

云计算与大数据之间的羁绊(期末不挂科版):云计算 | 大数据 | Hadoop | HDFS | MapReduce | Hive | Spark
文章目录 前言:一、云计算1.1 云计算的基本思想1.2 云计算概述——什么是云计算?1.3 云计算的基本特征1.4 云计算的部署模式1.5 云服务1.6 云计算的关键技术——虚拟化技术1.6.1 虚拟化的好处1.6.2 虚拟化技术的应用——12306使用阿里云避免了高峰期的崩…
Flume采集日志存储到HDFS
1 日志服务器上配置Flume,采集本地日志文件,发送到172.19.115.96 的flume上进行聚合,如日志服务器有多组,则在多台服务器上配置相同的配置
# Name the components on this agent
a1.sources r1
a1.sinks k1
a1.channels c1# Describe/con…
【Spark-HDFS小文件合并】使用 Spark 实现 HDFS 小文件合并
【Spark-HDFS小文件合并】使用 Spark 实现 HDFS 小文件合并 1)导入依赖2)代码实现2.1.HDFSUtils2.2.MergeFilesApplication 需求描述:
1、使用 Spark 做小文件合并压缩处理。
2、实际生产中相关配置、日志、明细可以记录在 Mysql 中。
3、…
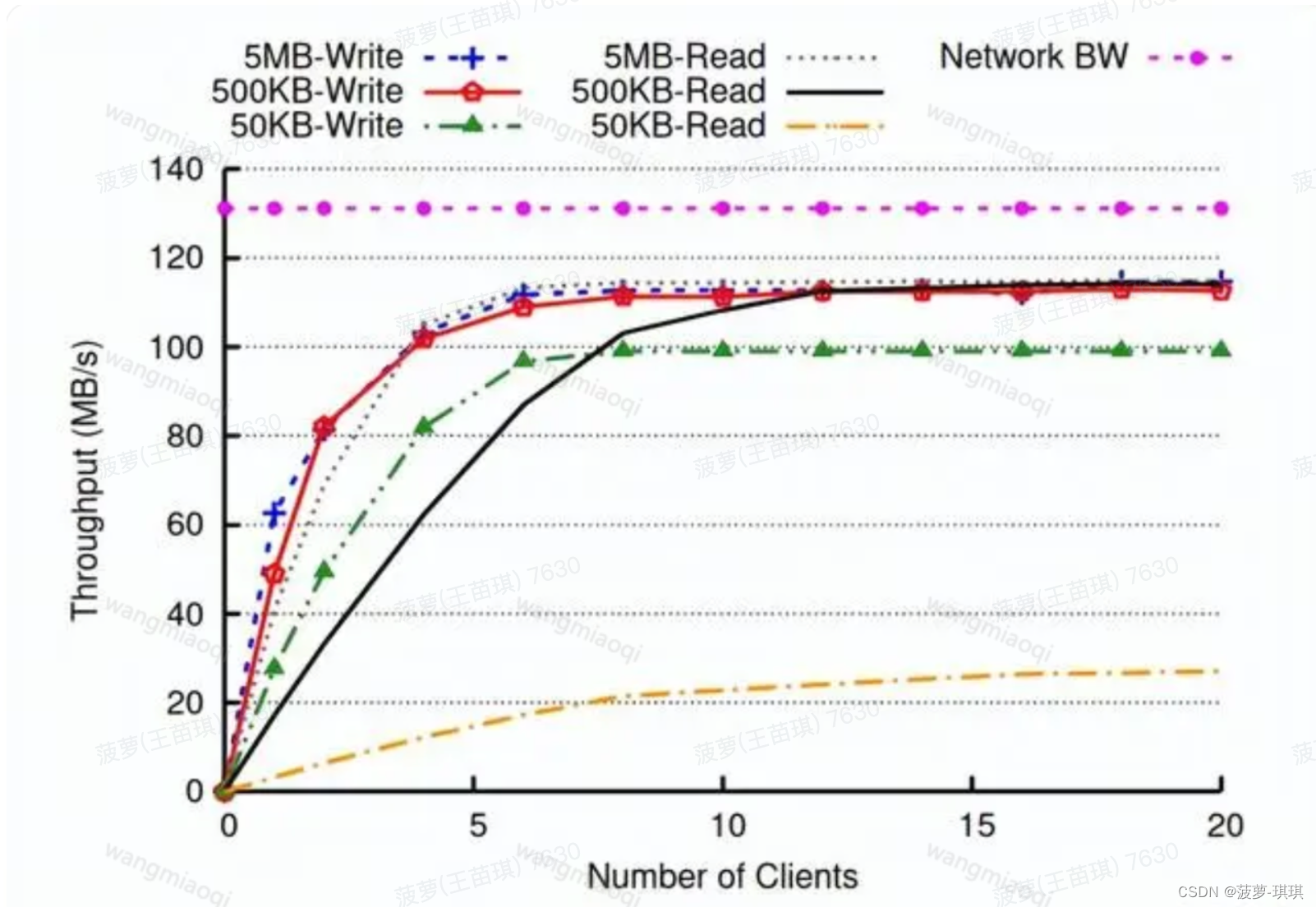
LinkedIn 开源分布式存储系统Ambry
分布式存储入门认知
分布式存储是一种用于处理大规模数据的存储系统。随着互联网的发展和数据量的爆发式增长,传统的集中式存储已经无法满足需求。分布式存储通过将数据分散存储在多个节点上,实现高可靠性、高扩展性和高性能的存储解决方案
分布式存储…

从零开始了解大数据(七):总结
系列文章目录 从零开始了解大数据(一):数据分析入门篇-CSDN博客 从零开始了解大数据(二):Hadoop篇-CSDN博客 从零开始了解大数据(三):HDFS分布式文件系统篇-CSDN博客 从零开始了解大数据(四):MapReduce篇-CSDN博客 从零开始了解大…
【DataSophon】大数据管理平台DataSophon-1.2.1安装部署详细流程
🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁&am…
查看hive表储存在hdfs的哪个目录下
查看hive表储存在hdfs的哪个目录下
使用Hive的DESCRIBE FORMATTED命令。
具体步骤如下: 打开Hive终端,并连接到Hive数据库。 运行以下命令,将表名替换为你要查询的表名:
DESCRIBE FORMATTED your_table_name;在输出中&#x…
IDEA使用HDFS的JavaApi
注:以下代码操作是利用junit在java测试文件夹中实现。 1. 准备工作
1.1 创建测试类
创建测试类,并定义基本变量
public class HDFSJAVAAPI {// 定义后续会用到的基本变量public final String HDFS_PATH "hdfs://hadoop00/";Configuration …
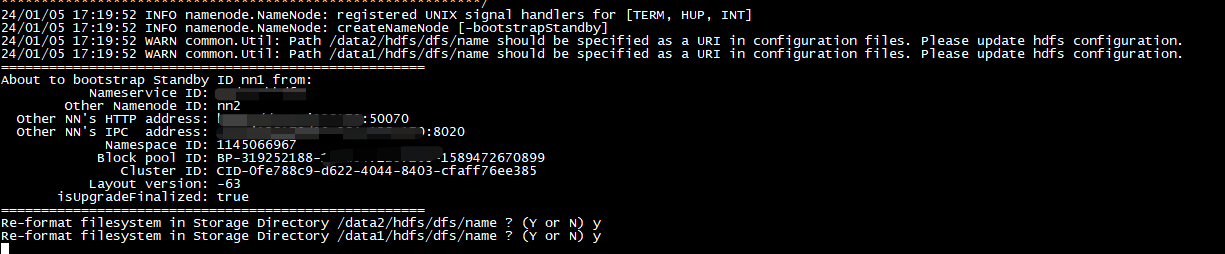
【HDFS】一次备NameNode宕机过久导致的生产事故
一次备NameNode宕机过久导致的生产事故
故障描述
最近发生的一个临时故障,情况是一个启了HA的HDFS集群,在2023年9月份因为两台NameNode同时启动产生一些问题,所以当时将一台节点停止,一直没有启动,具体为什么当时有问…

Flume实时读取本地/目录文件到HDFS
目录
一、准备工作
二、实时读取本地文件到HDFS
(一)案例需求
(二)需求分析
(三)实现步骤
三、实时读取目录文件到HDFS
(一)案例需求
(二)需求分析
…
HDFS相关API操作
文章目录 API文档环境配置API操作准备工作创建文件夹文件上传文件下载文件删除文件的更名和移动获取文件详细信息 API文档
HDFS API官方文档:https://hadoop.apache.org/docs/r3.3.1/api/index.html
环境配置
将Hadoop的Jar包解压到非中文路径(例如D:…
Spark解析JSON文件,写入hdfs
一、用Sparkcontext读入文件,map逐行用Gson解析,输出转成一个caseclass类,填充各字段,输出。
解析JSON这里没有什么问题。
RDD覆盖写的时候碰到了一些问题 :
1.直接saveAsTextFile没有覆盖true参数;
2.…
ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
文章目录 HDFS用法实施细节配置可选配置选项及其默认值的列表libhdfs3 支持的ClickHouse 额外的配置限制 Kerberos 支持虚拟列 资料分享系列文章clickhouse系列文章知乎系列文章 HDFS
这个引擎提供了与Apache Hadoop生态系统的集成,允许通过ClickHouse管理HDFS上的…
【HDFS】一天一个RPC系列--updateBlockForPipeline
本文目标是: 弄清updateBlockForPipeline这个RPC的作用。弄清updateBlockForPipeline RPC的使用场景,代码里的调用点。一、updateBlockForPipeline的作用
其定义在ClientProtocol接口里,是Client与NameNode之间的接口。
看其代码注释描述: 为一个under construction状态下…
【HDFS】一天一个RPC系列--updatePipeline
updatePipeline这个RPC一般都会配合updateBlockForPipeline RPC一起使用。 先updateBlockForPipeline、然后再updatePipeline。
建议先阅读【HDFS】一天一个RPC系列–updateBlockForPipeline
本文目标是弄清楚以下问题: 弄清updatePipeline这个RPC的作用。弄清updatePipeli…
绝对完美解决hdfs datanode数据和磁盘数据分布不均调整(hdfs balancer )——经验总结
Hadoop集群Datanode数据倾斜,个别节点hdfs空间使用率达到95%以上,于是新增加了三个Datenode节点,由于任务还在跑,数据在不断增加中,这几个节点现有的200GB空间估计最多能撑20小时左右,所以必须要进行balance操作。
通过观察磁盘使用情况,发现balance的速度明显跟不上新…
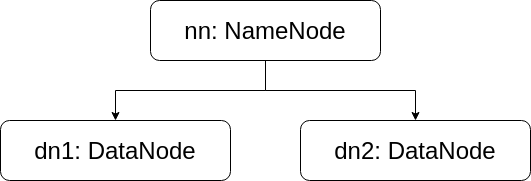
5.0 HDFS 集群服务建立教程
HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。
使用 Docker 可以更加方便地、高效地构建出一个集群环境。
每台计算机中的配置
Hadoop 如何配置集群、不同的计…

热数据存储在HDFS,冷备数据存储于对象存储中
1.场景分析
生产环境均为腾讯云服务器,日志数据计划存储于HDFS中,由于日志数据较大(压缩后1T/天),不断扩充云盘成本消耗大。鉴于对象存储的存储成本较为低廉,但是日常频繁使用会产生流量费用。 鉴于此&…
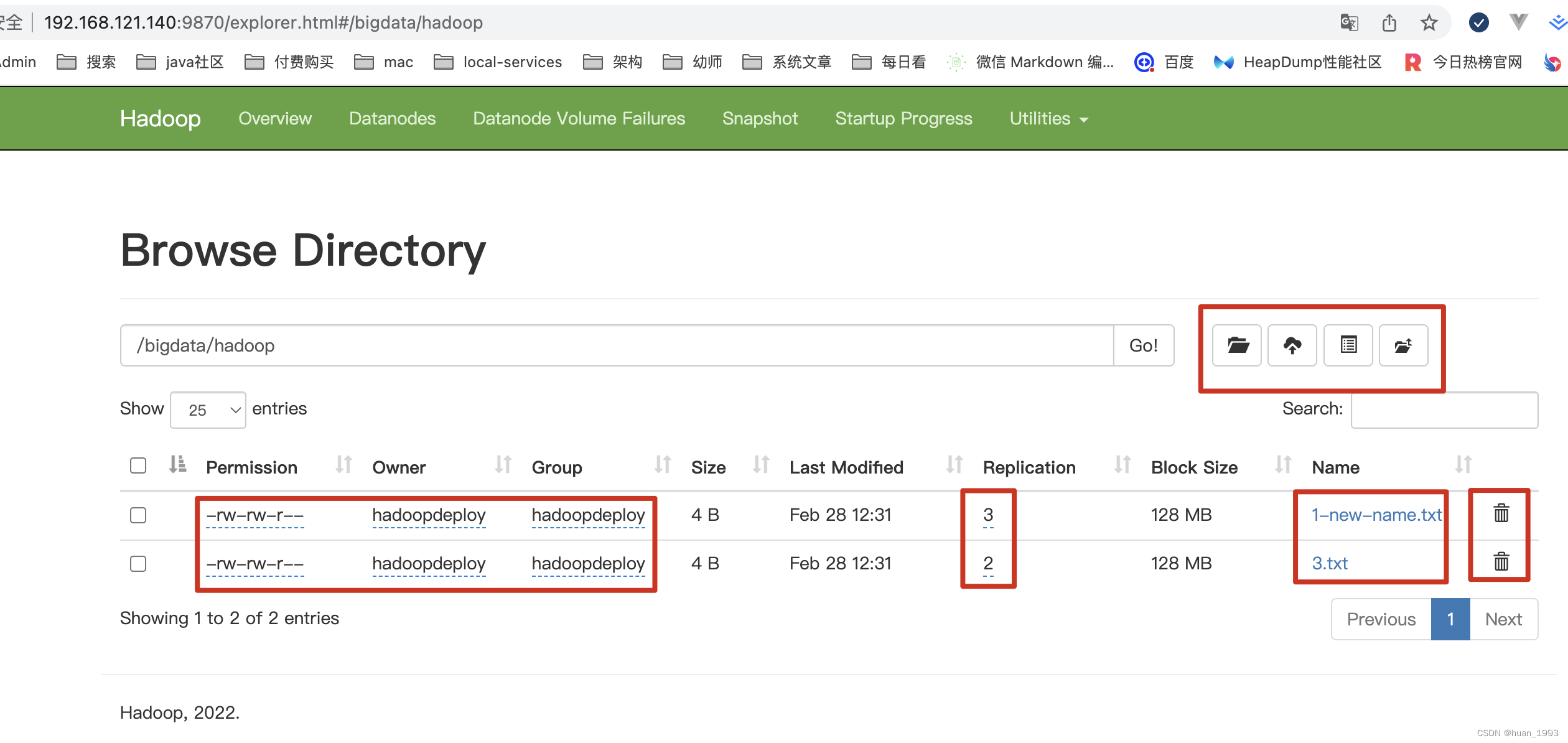
hdfs file system shell的简单使用
文章目录1、背景2、hdfs file system shell命令有哪些3、确定shell操作的是哪个文件系统4、本地准备如下文件5、hdfs file system shell5.1 mkdir创建目录5.2 put上传文件5.3 ls查看目录或文件5.4 cat 查看文件内容5.5 head 查看文件前1000字节内容5.6 tail 查看文件后1000字节…

基于docker安装HDFS
1.docker一键安装见
docker一键安装
2.拉取镜像
sudo docker pull kiwenlau/hadoop:1.03.下载启动脚本
git clone https://github.com/kiwenlau/hadoop-cluster-docker4.创建网桥
由于 Hadoop 的 master 节点需要与 slave 节点通信,需要在各个主机节点配置节点…
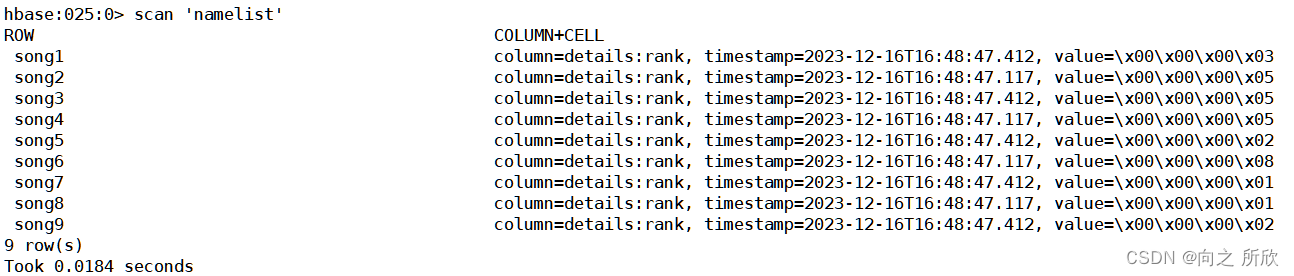
大数据开发项目--音乐排行榜
环境:windows10,centos7.9,hadoop3.2、hbase2.5.3和zookeeper3.8完全分布式; 环境搭建具体操作请参考以下文章: CentOS7 Hadoop3.X完全分布式环境搭建 Hadoop3.x完全分布式环境搭建Zookeeper和Hbase
1. 集成MapReduce…
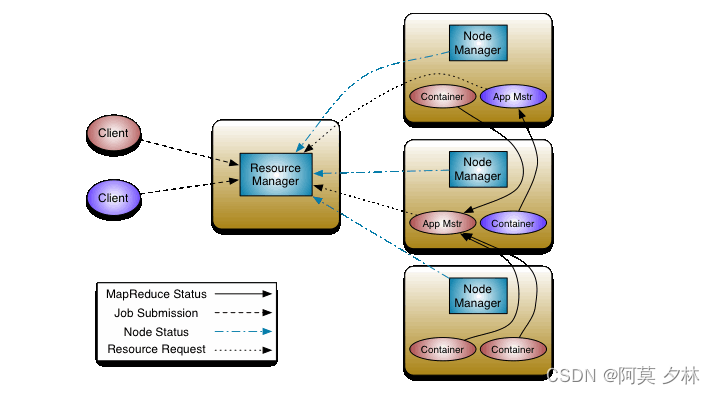
解析Hadoop三大核心组件:HDFS、MapReduce和YARN
目录 HadoopHadoop的优势 Hadoop的组成HDFS架构设计Yarn架构设计MapReduce架构设计 总结 在大数据时代,Hadoop作为一种开源的分布式计算框架,已经成为处理大规模数据的首选工具。它采用了分布式存储和计算的方式,能够高效地处理海量数据。Had…
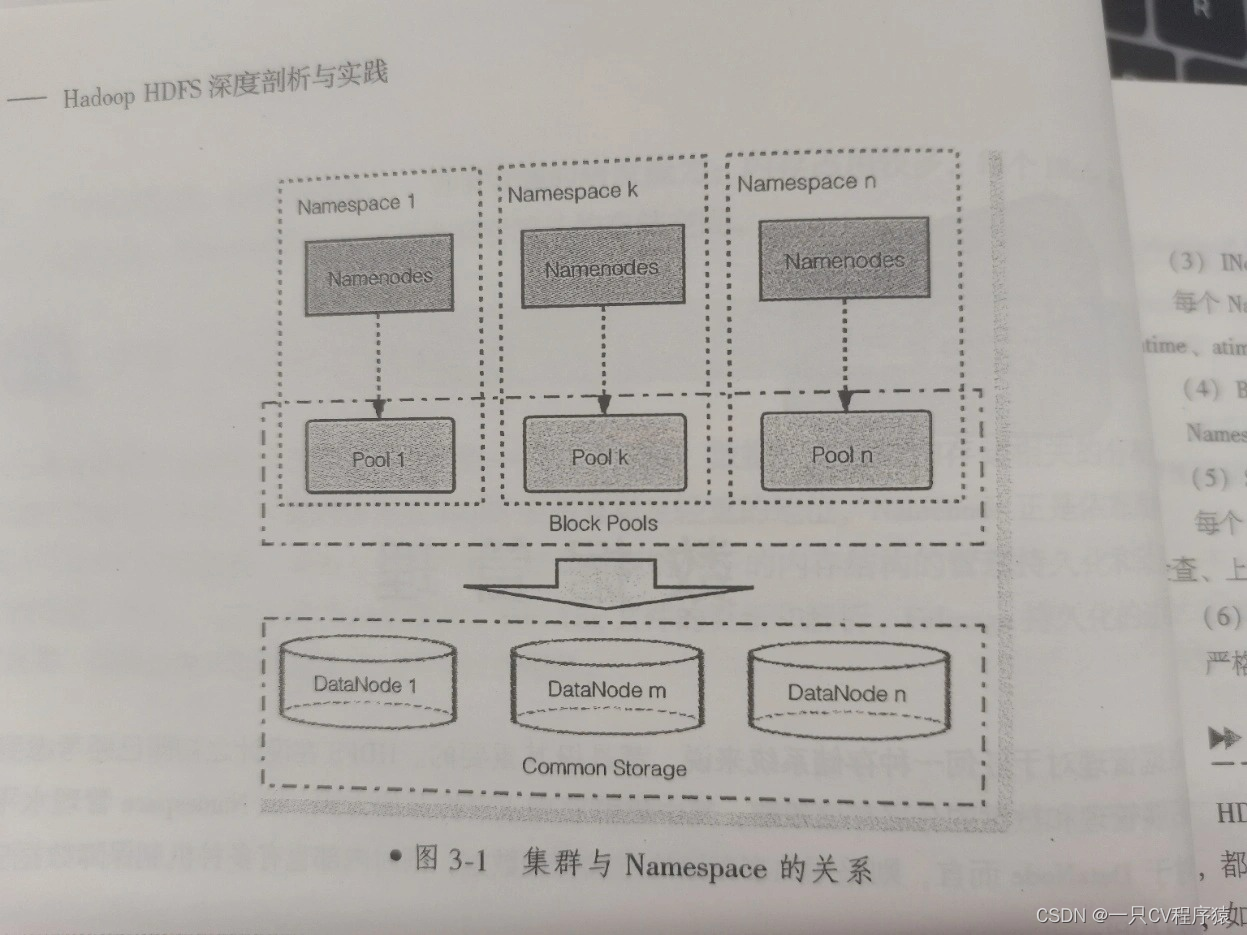
Hadoop之HDFS——【模块二】数据管理
一、Namespace的概述
1.1.集群与命名空间的关系 类似于大集群与小集群之间的关系,彼此之间独立又相互依存。每个namespace彼此独立,Namespace工作时只负责维护本区域的数据,同时所有的namespace维护的文件都可以共用DataNode节点,为了区分数据属于哪些Namespace,DataNode…

Hadoop之HDFS使用命令(常用)
本篇仅记载部分常用命令
若无所需命令可查看官方网站Apache Hadoop 3.3.6 – Overview 注:一切命令仅在启动HDFS集群后执行,否则会报错
注:仅在hadoop用户下操作 在Linux中超级用户是:root 但HDFS的超级用户是:启动n…

Middleware ❀ Hadoop功能与使用详解(HDFS+YARN)
文章目录 1、服务概述1.1 HDFS1.1.1 架构解析1.1.1.1 Block 数据块1.1.1.2 NameNode 名称节点1.1.1.3 Secondary NameNode 第二名称节点1.1.1.4 DataNode 数据节点1.1.1.5 Block Caching 块缓存1.1.1.6 HDFS Federation 联邦1.1.1.7 Rack Awareness 机架感知 1.1.2 读写操作与可…

php连接hdfs初步探索
一、phdfs拓展
结果:暂时舍弃
安装此拓展时,无法make成功,因为缺少hdfs.n文件。 换了其他版本的拓展包,并编译都没有找到此文件。
后搜到官网的相关资料,此hdfs.h的文件路径的地址是$HADOOP_HDFS_HOME/include/hdfs…

HDFS简介与部署以及故障排错(超简单)
文章目录 一、HDFS介绍1、简介2、结构模型3、文件写入过程4、文件读取过程5、文件块的存放6、存储空间管理机制6.1 文件删除和恢复删除6.2 复制因子配置6.3 文件命名空间6.4 数据复制机制 二、环境搭建(单机版)1、修改主机名2、配置ssh免密登录3、Hadoop…
Hadoop集成对象存储和HDFS磁盘文件存储
1.环境配置
1.1 版本说明
组件版本是否必须其他事项Hadoop3.3.0是hadoop3.3.0之后原生支持国内主要对象存储Hive3.1.3否实测没有Hive也可以使用sparksql,使用hive更好的管理HDFS数据spark3.3.1是hive和spark整合后,语法为HSQL,自定义函数按…
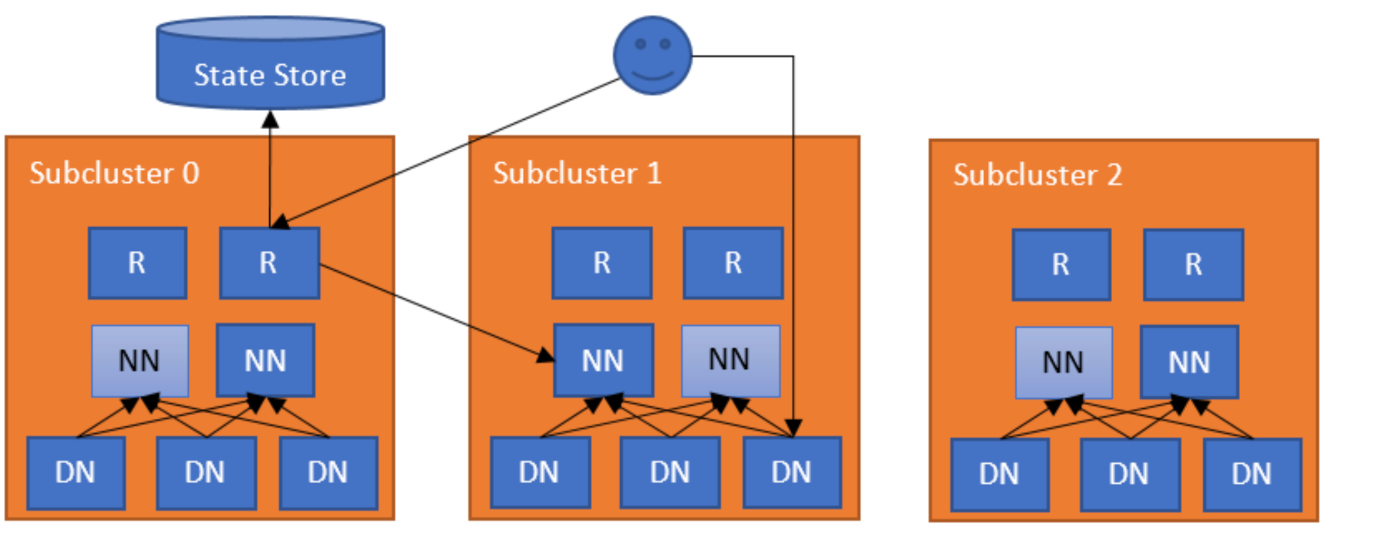
【HDFS联邦(2)】HDFS Router-based Federation官网解读:HDFSRouterFederation的架构、各组件基本原理
文章目录 一. 介绍二、HDFS Router-based Federation 架构1. 示例说明2. Router2.1. Federated interface2.2. Router heartbeat2.3. NameNode heartbeat2.4. Availability and fault toleranceInterfaces 3. Quota management4. State Store 三、部署 ing 本文主要参考官网&am…
EMR集群迁移自建Hadoop(元数据及HDFS数据)
1.背景
老集群采用的腾讯emr集群,使用过程中磁盘扩容成本费用高且开源组件兼容性存在问题,因此决定采用自建hadoop集群,需要将emr的元数据和hdfs基础数据迁移过来。 EMR版本:3.1.2 自建Hadoop版本:3.1.3
2.集群迁移步…
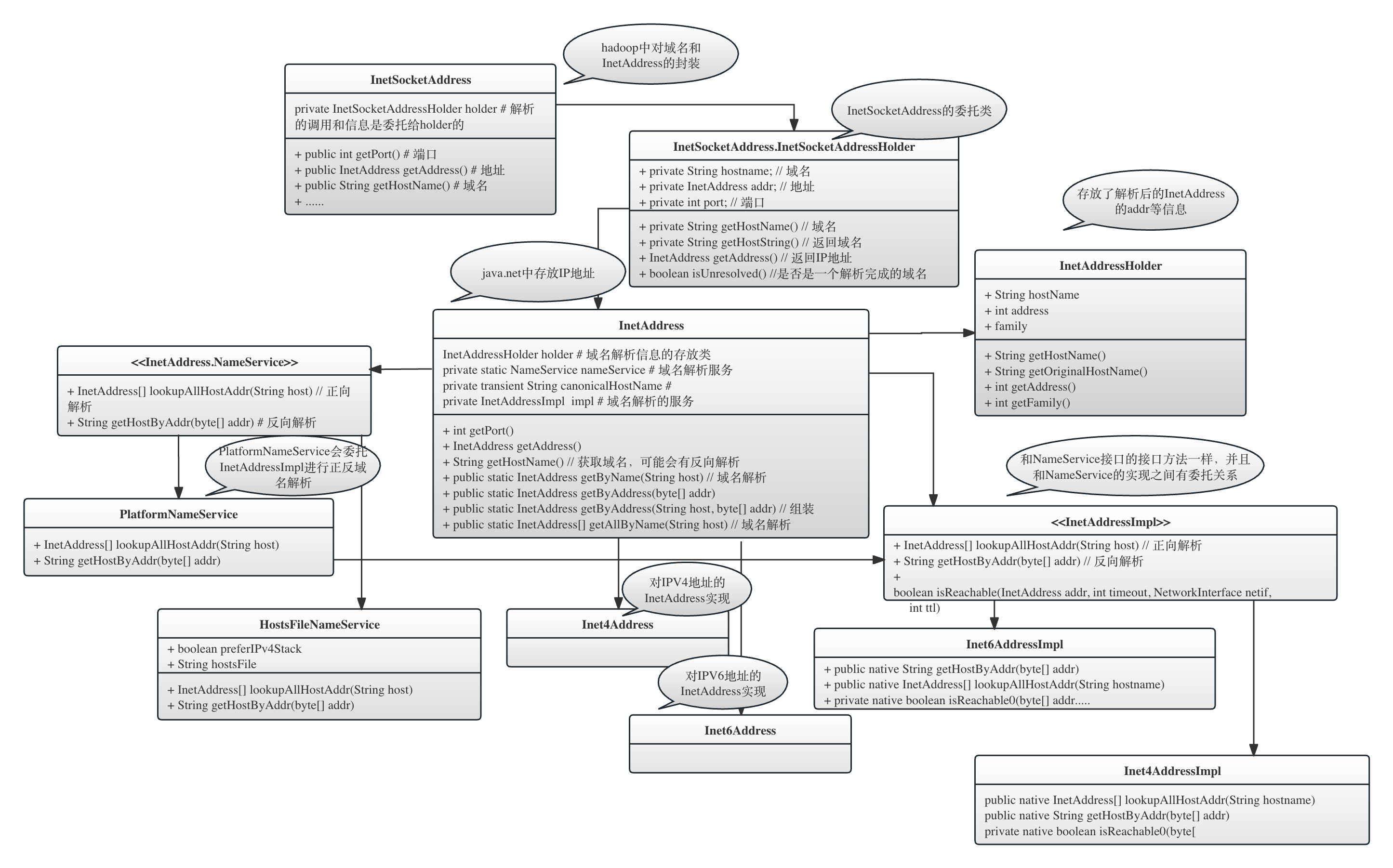
HDFS客户端UnknownHostException事故解析
文章目录 前言事故现场问题分析是否是整个域名解析服务当时都出问题了是否是出问题的pods本身的域名解析有问题 异常发生的全部过程域名的解析是什么时候发生的,怎么发生的域名解析的详细流程 重试发生在什么地方为什么重试会无效 Bugfix代码详解关于StandardHostRe…
MAC下搭建hadoop
一:简介
Hadoop是一个用Java开发的开源框架,它允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。它的设计是从单个服务器扩展到数千个机器,每个都提供本地计算和存储。特别适合写一次,读多次的场景。
Hado…
Java大数据开发:Hadoop(8)-java操作HDFS
在上一节的学习中,我们认识了HDFS的结构,知道了HDFS的优点:适合大数据处理,无论是数据规模还是文件规模。当然也有他的缺点:不适合低延时数据访问,比如毫秒级的数据存储,那做不到,不…
自学大数据第三天~终于轮到hadoop了
前面那几天是在找大数据的门,其实也是在搞一些linux的基本命令,现在终于轮到hadoop了 Hadoop
hadoop的安装方式
单机模式: 就如字面意思,在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统~就如我们一开始入门的时候都是从本地开始的; 伪分布式模式
存储采用…
Spark 开发原则
Spark 开发原则坐享其成要省要拖跳出单机思维应用开发原则 :
坐享其成 : 利用 Spark SQL 优化能省则省、能拖则拖 : 节省数据量 , 拖后 Shuffle跳出单机思维 : 避免无谓的分布式遍历
坐享其成
设置好配置项,享受 Spark SQL 的性能优势,如钨…

通过JavaAPI访问HBase
先开始创建表
create emp001,member_id,address,info放入数据
put emp001,Rain,id,31
put emp001, Rain, info:birthday, 1990-05-01
put emp001, Rain, info:industry, architect
put emp001, Rain, info:city, ShenZhen
put emp001, Rain, info:country, China
get emp001,…
自学大数据第六天~HDFS命令
HDFS常用命令
查看hadoop版本 version
hadoop version注意,没有 ‘-’
[hadoopmaster ~]$ hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:3…
3.Hadoop运行模式-完全分布式(重点)—xsync集群分发脚本、集群配置、SSH无密登录、启动集群
本文目录如下:4 完全分布式运行模式(开发重点)4.1 虚拟机准备4.2 scp(secure copy)安全拷贝4.3 rsync 远程同步工具4.4 **xsync集群分发脚本**4.4.1 需求分析:4.4.2 脚本实现4.4.3 xsync相关错误4.5 集群配置4.5.1 集群部署规划4.…
hadoop集群基础配置
hadoop1.0 mapreduce HDFS hadoop2.0 mapreduce HDFS YARN 加入YARN使得hadoop更加包容,其他的组件也可以在hadoop生态系统中运行 hadoop3.0 HDFS(分布式存储) mapreduce(分布式计算框架) YARN(集群资源调度) …
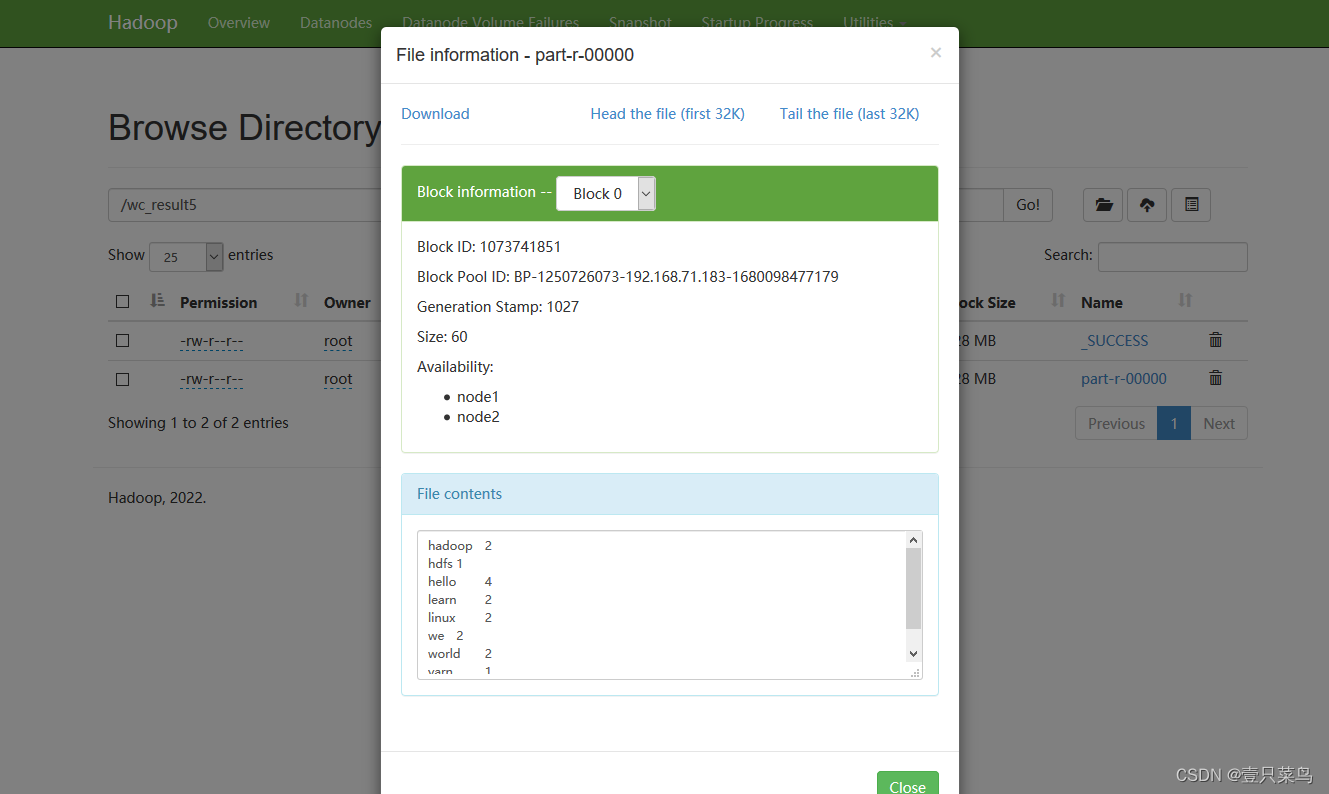
CHAPTER 7 HPC集群部署 - hadoop
HPC集群部署 - hadoop1. 介绍2. 优点3. 架构及相关组件3.1 HDFS3.1.1 NameNode3.1.2 DataNode3.1.3 Secondary NameNode3.1.4 Client(客户端)3.2 Mapreduce(分布式计算框架)3.3. HBase(分布式列存储数据库)3.4 Zookeeperÿ…

Hadoop HDFS的API操作
客户端环境准备
hadoop的 Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\)。
配置HADOOP_HOME环境变量
配置Path环境变量。 不能放在包含有空格的目录下,cmd 输入hadoop显示此时不应有 \hadoop-3.0.0\bin\。我放在…
datax连tdh写数问题记录
There are 3 datanode(s) running and 3 node(s) are excluded in this operation { “dfs.nameservices”: “nameservice1”, “dfs.ha.namenodes.nameservice1”: “nn1,nn2”, “dfs.namenode.rpc-address.nameservice1.nn1”: “bigdata2:8020”, “dfs.namenode.rpc-addr…
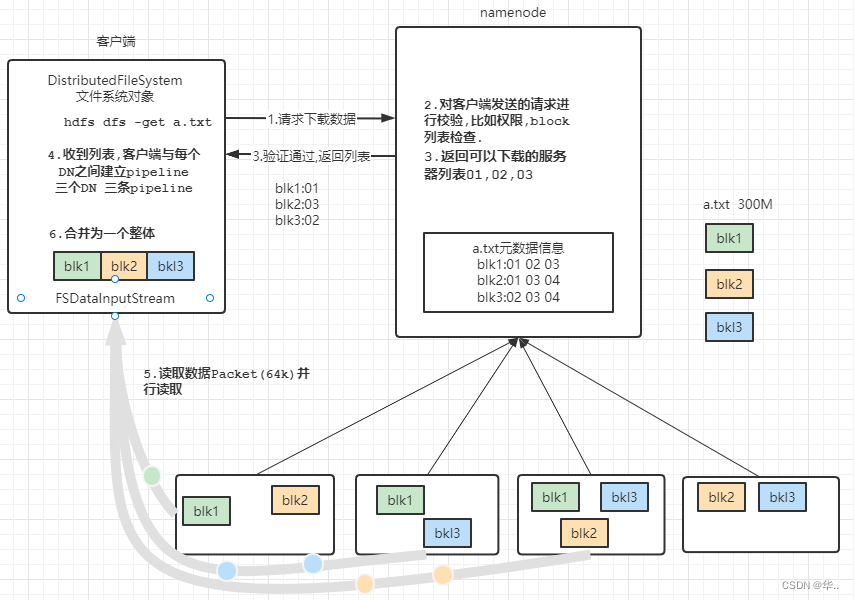
Hadoop上传及下载数据流程
网络拓扑及机架感知 网络拓扑 节点距离:两个节点到达共同父节点的距离和 机架感知 ( 副本节点的选择 ) 例如:500个节点,上传数据my.tar.gz,副本数为3, 根据机架感知,副本数据…
Apache Hadoop 使用教程 (2): 单节点环境搭建实战中级
步骤: 1、创建用户 sudo useradd -m hadoop -s /bin/bash sudo passwd hadoop sudo adduser hadoop sudo
2、注销当前用户并使用hadoop用户登陆
3、更新资源库 sudo apt-get update
4、安装vim sudo apt-get install vim
5、安装ssh sudo apt-get install opens…
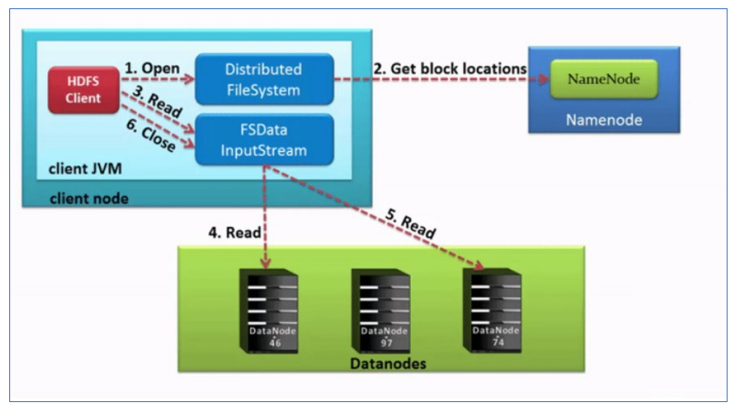
【Hadoop】一、Apache Hadoop、 HDFS
一、Apache Hadoop、 HDFS
1、Apache Hadoop概述
Hadoop介绍 狭义上Hadoop指的是Apache软件基金会的一款开源软件。 用java语言实现,开源 允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理 Hadoop核心组件 Hadoop HDFS(分布式文…
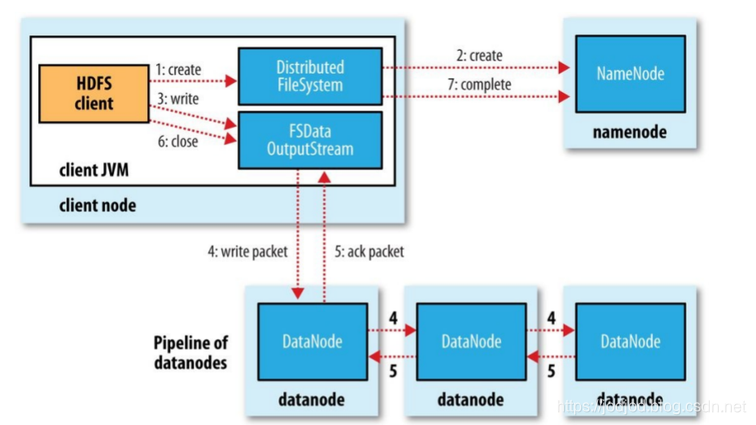
Hadoop:文件操作过程之HDFS写流程详解(部分源码)
写流程
在创建了分布式文件系统的实例后,客户端通过调用该实例的create()方法就可以创建文件,并会发送给Namenode一个RPC调用,在文件系统的命名空间中创建一个新文件,在创建文件前namenode会做一些检查(如文件是否存在…

Hadoop启动以后,DataNode无法启动,不报错
这个就是当我们启动Hadoop时候,查看的时候会发现DataNode启动不了,但是也没有报错,那么这个问题怎么解决呢? 解决办法 1.先看hdfs-site.xml是否正确 2.打开NameNode下的VERSION文件,复制其cluster ID一行,…

【002hive基础】hive的库、表与hdfs的组织逻辑
文章目录 一. 数据的组织形式1. hive数据库2. hive表2.1. 内部表和外部表2.2. 分区表与分桶表 3. 视图 二. 底层储存 一. 数据的组织形式
1. hive数据库
hive将不同功能模块的数据,存储在不同的数据库中,在hdfs中以文件夹的形式显示。 2. hive表
2.1.…

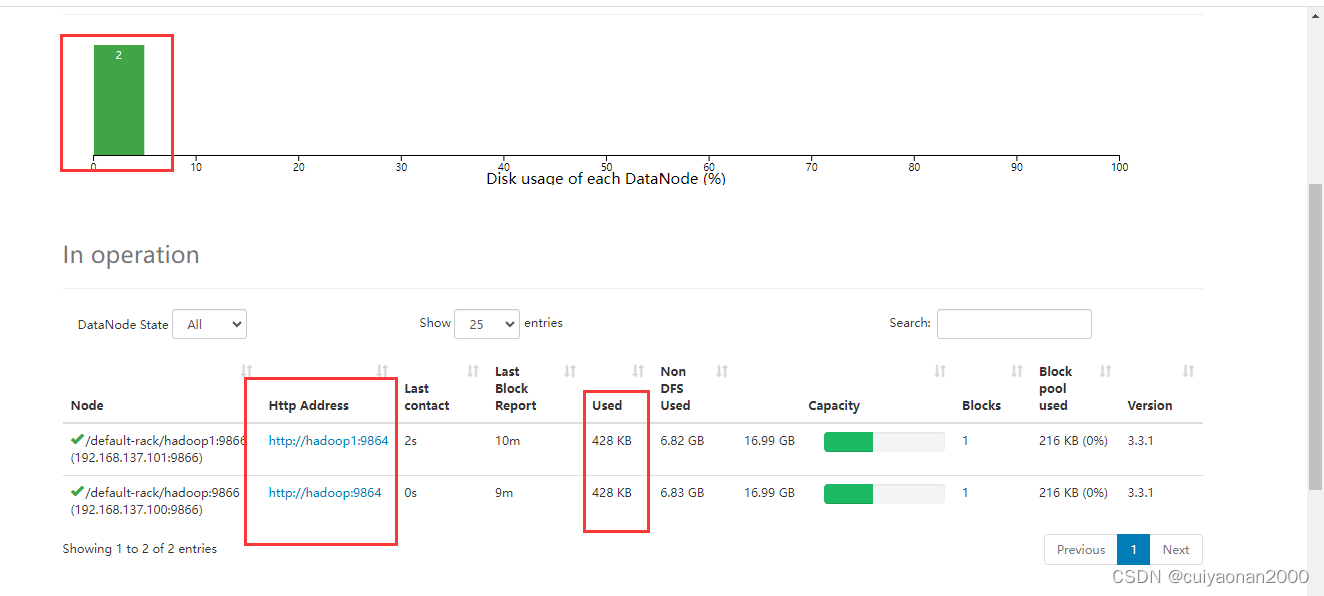
ViewFs And Federation On HDFS
序言
ViewFs 是在Federation的基础上提出的,用于通过一个HDFS路径来访问多个NameSpace,同时与ViewFs搭配的技术是client-side mount table(这个就是具体的规则配置信息可以放置在core.xml中,也可以放置在mountTable.xml中).
总的来说ViewFs的其实就是一个中间层,用于去连接不…
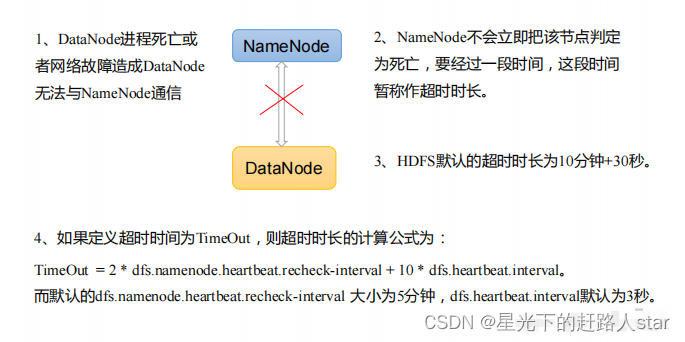
Hadoop基础学习---4、HDFS写、读数据流程、NameNode和SecondaryNameNode、DataNode
1、HDFS写、读数据流程
1.1 HDFS写数据流程
1.1 剖析文件写入 1、客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 2、NameNode返回是否可以上传。 3、客户端请求第一个Block上传到哪几…
YARN的Node Label机制
Node Label的介绍
官网对NodeLabel的介绍如下: Node label is a way to group nodes with similar characteristics and applications can specify where to run. 节点标签是一种对具有相似特征的节点进行分组的方法,应用程序可以指定在哪里运行。 那么标签到底是做…
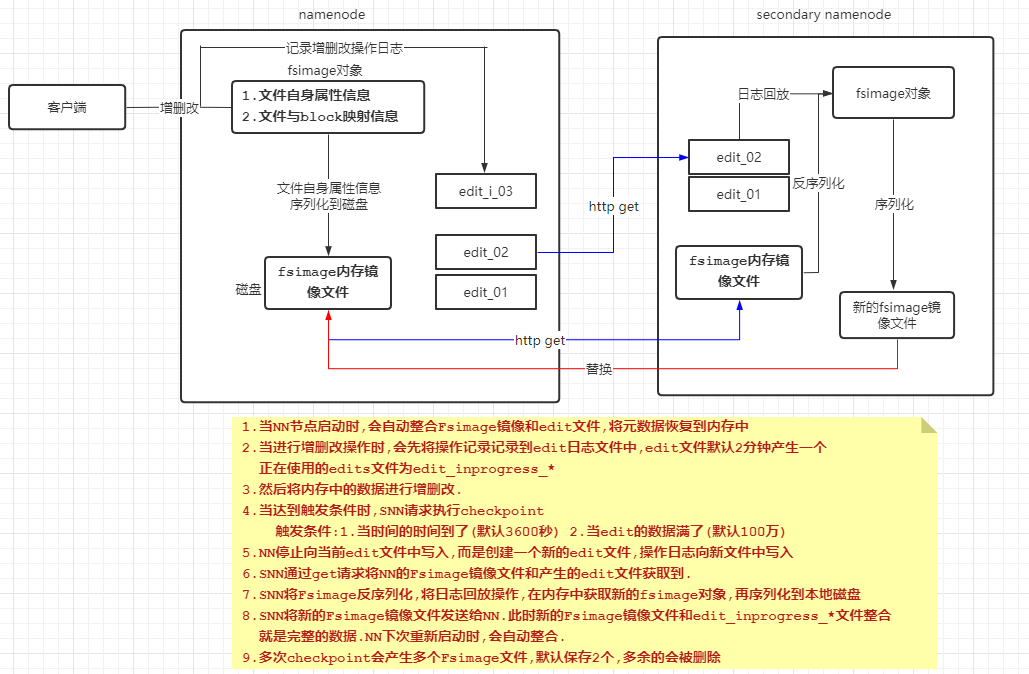
[Hadoop实现Springboot之HDFS数据查询和插入 ]
目录
🎃前言:
🎃Spring Boot项目中添加Hadoop和HDFS的依赖。可以使用Apache Hadoop的Java API或者使用Spring Hadoop来简化操作。
🎃 需要配置Hadoop和HDFS的连接信息,包括Hadoop的配置文件和HDFS的连接地址等。
Ἰ…
dfs.nameservices参数
当在Hadoop集群中配置高可用性(High Availability)时,dfs.nameservices参数在Hadoop分布式文件系统(HDFS)中起着重要的作用。该参数用于指定HDFS集群的名称服务(NameNode),它是一个逻…

Hadoop --- HDFS介绍
HDFS 全称是Hadoop Distributed File System hadoop分布式(cluser)文件存储系统。适合一次写入,多次读出的场景。
HDFS不需要单独安装,安装Hadoop的时候带了HDFS系统。
Hadoop安装可以参考:
有基础的,已…
Hadoop3的高可用搭建
1. 准备工作 前期准备工作包括了 CenOS 7虚拟化安装与配置,
Java虚拟机的安装,
Hadoop相关部署包的下载,
Hadoop集群所需基础环境的配置。
第一点CenOS 7虚拟化安装与配置和第二点Java虚拟机的安装:
需要我们参考第一章&…

大数据开发基础-环境配置篇-Hadoop集群安装
鼠鼠接下来将更新一系列自己在学习大数据开发过程中收集的资源、和自己的总结、以及面经答案、LeetCode刷题分析题解。
首先是大数据开发基础篇 环境搭建、组件面试题等 其次是更新大数据开发面经的java面试基础 最后更新一个大数据开发离线数仓的实战项目,自己写入…

使用Java API 访问HDFS上的数据
文章目录一.概述二.搭建环境1.使用Maven构建Java程序,添加maven的依赖包2.修改hdfs-site.ml文件,添加如下配置,放开权限,重启hdfs服务3.单元测试的setUp和tearDown方法4.使用Java API操作HDFS的常用操作1)创建目录2)创建文件并写入数据3)重命名操作4)上传本地文件到HDFS5)查看某…
【Flink 实战系列】Flink SQL 使用 filesystem connector 同步 Kafka 数据到 HDFS(parquet 格式 + snappy 压缩)
Flink SQL 同步 Kafka 数据到 HDFS(parquet + snappy)
在上一篇文章中,我们用 datastream API 实现了从 Kafka 读取数据写到 HDFS 并且用 snappy 压缩,今天这篇文章我们来实现一个 Flink SQL 版本的,为了方便我直接采用 sql-client 提交任务的方式来演示。
添加 jar 包 …
零基础徒手搭建大数据监控主机系统Grafana
注:本文搭建需掌握Linux基本命令。成功后的截图实例如图,随着时间的增长会更加帅气!
一. 需要的安装包
prometheus-2.9.2.linux-amd64.tar.gznode_exporter-0.17.0.linux-amd64.tar.gzgrafana-6.1.4.linux-amd64.tar.gz
注:安装…
Java大数据开发:Hadoop-HDFS
在刚开始的学习中,曾经介绍过,hadoop组成部分包含HDFS,MapReduce,下面我们就来看一下HDFS吧。
HDFS概念
1.1 概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次࿰…

创建HDFS,导入HADOOP jar包
创建HDFS,导入HADOOP 所有jar包
1、打开eclipse
点击
2、新建java project: 选择自己安装的jdk版本(老版本容易出bug)
3、在hadoop工程下新建文件夹lib(用于存放jar包) 4、导入jar包
第一个jar包 cp …

解锁大数据世界的钥匙——Hadoop HDFS安装与使用指南
目录
1、前言
2、Hadoop HDFS简介
3、Hadoop HDFS安装与配置
4、Hadoop HDFS使用
5、结语
1、前言 大数据存储与处理是当今数据科学领域中最重要的任务之一。随着互联网的迅速发展和数据量的爆炸性增长,传统的数据存储和处理方式已经无法满足日益增长的需求。…

PiflowX组件-WriteToUpsertKafka
WriteToUpsertKafka组件
组件说明
以upsert方式往Kafka topic中写数据。
计算引擎
flink
有界性
Streaming Upsert Mode
组件分组
kafka
端口
Inport:默认端口
outport:默认端口
组件属性
名称展示名称默认值允许值是否必填描述例子kafka_h…
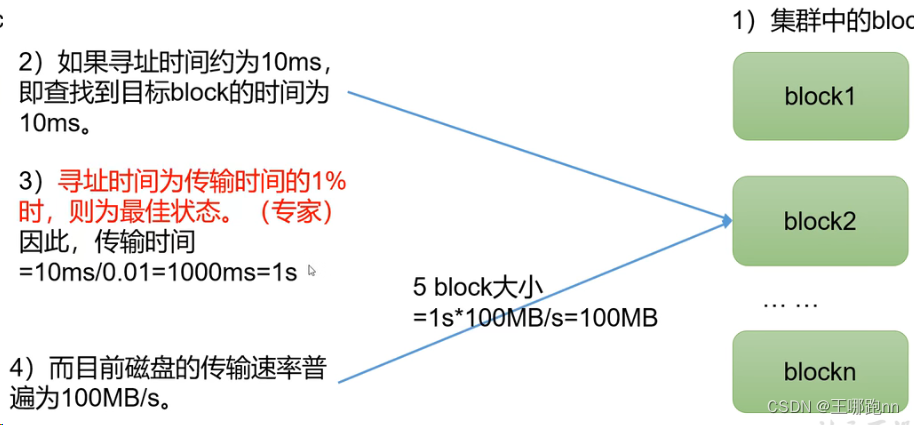
大数据 - Hadoop系列《三》- HDFS(分布式文件系统)概述
🐶5.1 hdfs的概念
HDFS分布式文件系统,全称为:Hadoop Distributed File System。
它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集…
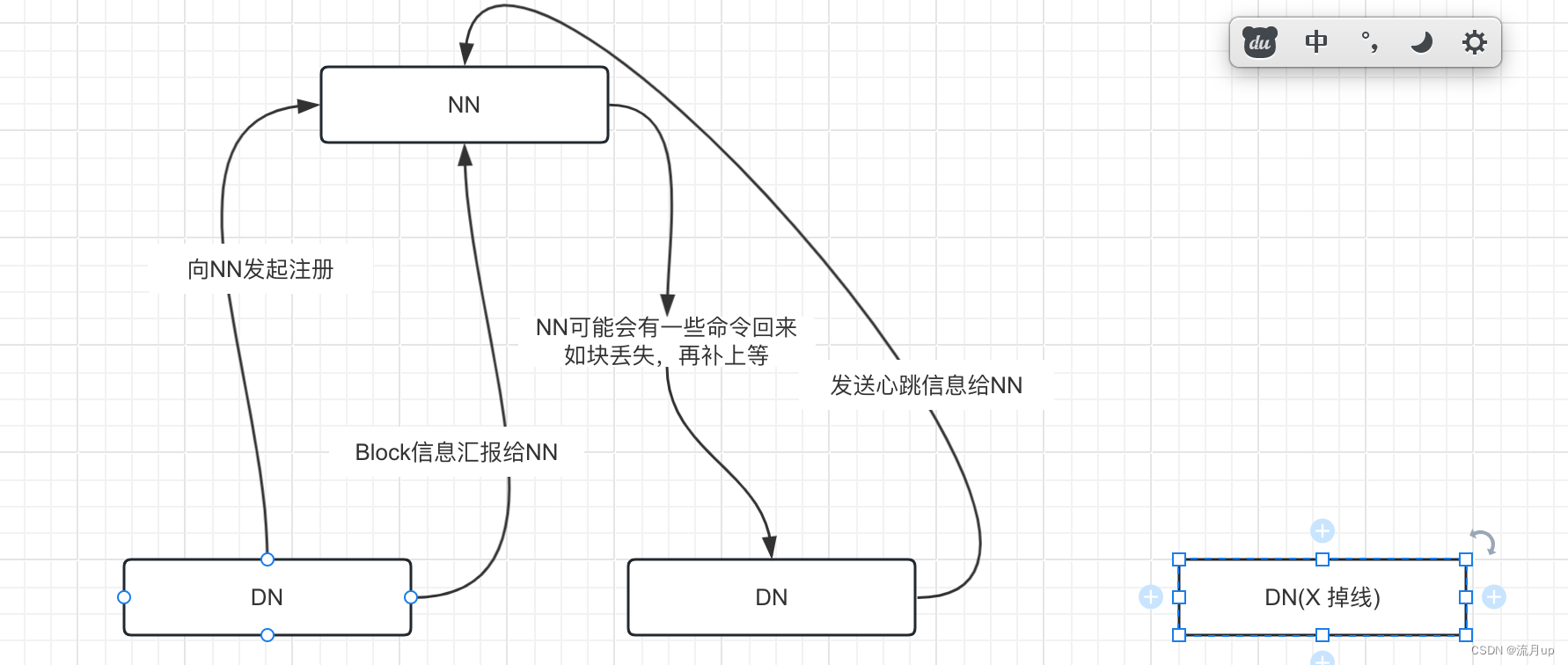
【大数据】二、HDFS 入门演示
大数据
要了解大数据,我们就要先了解什么是数据?
数据就是指人们的行为,人们的某个行为都被称为是一项数据,这些数据可以用来对生活中各种各样的事物进行分析,而我们进行分析所需要的技术就是我们所学的大数据的一系…

HDFS集群环境配置
HDFS集群环境配置
环境如下三台服务器:
192.168.32.101 node1192.168.32.102 node2192.168.32.103 node3
一、Hadoop安装包下载 点此官网下载 二、Hadoop HDFS的角色包含:
NameNode,主节点管理者DataNode&am…
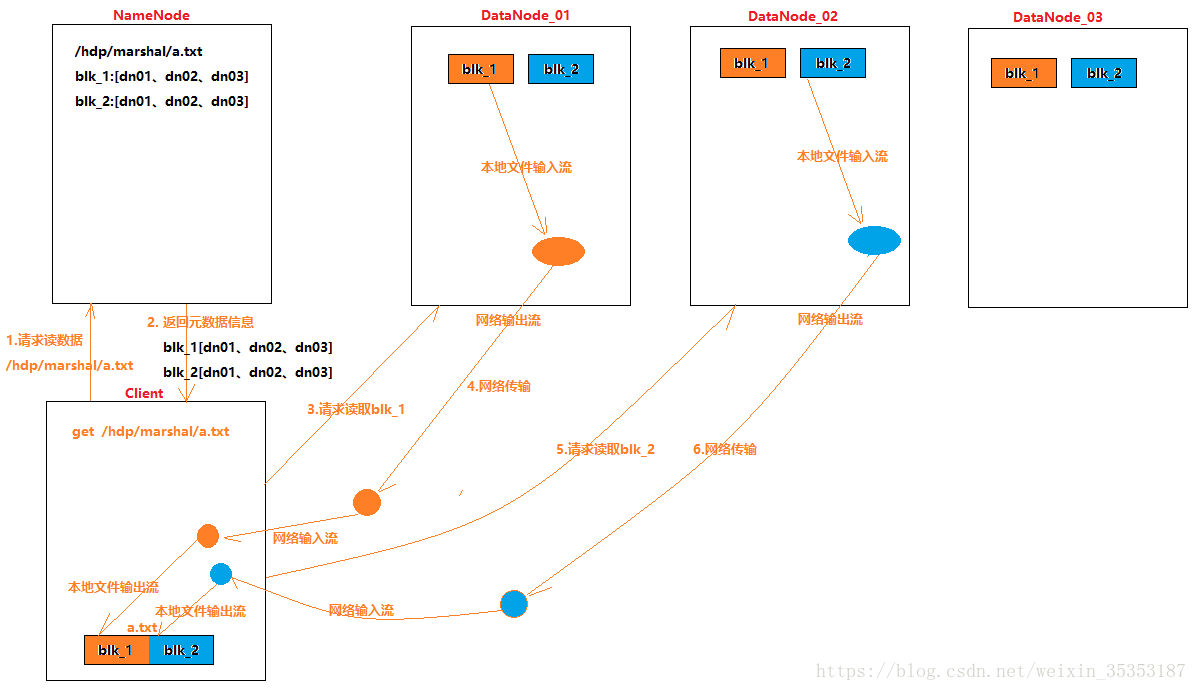
彷徨 | Hadoop之HDFS个人浅谈
小白所写 , 写的不好 , 请大神指点
目录
1 . Hadoop中有三个核心组件 :
2 . 大数据的基本概念 :
处理海量数据的核心技术 :
分布式存储的框架:
分布式的计算框架:
辅助类工具有:
3 . 分布式文件存储系统HDFS
4 . Hadoop集群Shell端操作HDFS…
报错there is no HDFS_NAMENODE_USER defined
在Hadoop安装目录下找到sbin文件夹,修改里面的四个文件
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
HDFS_DATANODE_USERroot
HDFS_DATANODE_SECURE_USERhdfs
HDFS_NAMENODE_USERroot
HDFS_SECONDARYNAMENODE_USERroot
2、对于st…
hadoop的运行模式
作者简介:大家好我是小唐同学(๑><๑),好久不见,为梦想而努力的小唐又回来了,让我们一起加油!!! 个人主页:小唐同学(๑><๑)的博客主页 目前…
Spark Standalone 部署
Spark Standalone 部署解压缩文件修改配置文件启动集群Web UI 界面提交应用提交参数说明配置历史服务配置日志存储路径添加日志配置重启重新执行任务查看历史服务配置高可用(HA)集群规划停止集群启动 Zookeeper启动集群关闭集群关闭历史服务解压缩文件
…
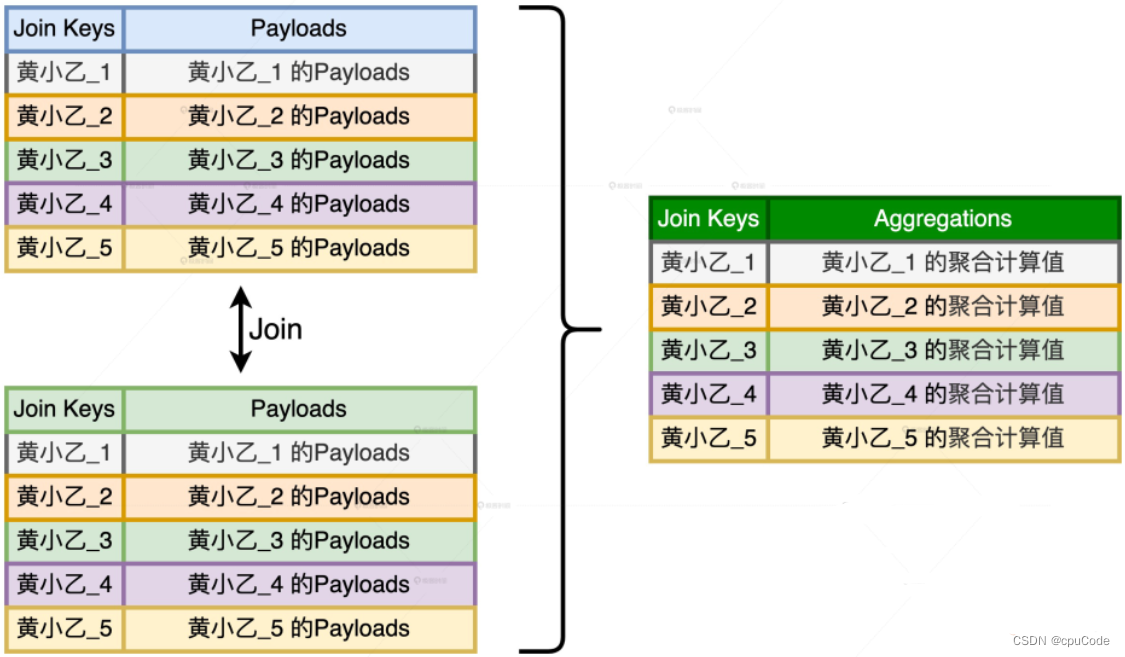
Spark Join大大表
Spark Join大大表分而治之拆分内表外表的重复扫描案例负隅顽抗数据分布均匀数据倾斜Task 数据倾斜Executor 数据倾斜两阶段 ShuffleExecutors 调优案例Join 大大表 :
Join 的两张体量较大的事实表,尺寸相差在 3 倍内,且无法广播变量用大表 Join 大表才能…
大数据实验统计-1、Hadoop安装及使用;2、HDFS编程实践;3、HBase编程实践;4、MapReduce编程实践
大数据实验统计
1、Hadoop安装及使用;
一.实验内容
Hadoop安装使用:
1)在PC机上以伪分布式模式安装Hadoop;
2)访问Web界面查看Hadoop信息。
二.实验目的
1、熟悉Hadoop的安装流程。
2、…
【HDFS】 写数据报 NOT_ENOUGH_STORAGE_SPACE
一、问题描述
对测试集群做压测,实验配置如下: 10个Client、每个Client使用550线程去写80000个文件,每个文件10KB。
在测试的过程中,客户端侧报了很多写入失败的异常日志,如下所示。 提示信息显示3台运行的datanode都被exclude了,因此选不出节点写入导致写入失败。
13…
hadoop中hdfs的fsimage文件与edits文件
hadoop中hdfs的fsimage文件与edits文件的作用
首先,我们抛出fsimage和edits文件的功能描述。
Fsimage文件: HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的
所有目录和文件inode的序列化信息。
Edits文件:存放HDFS文件系统的所有更…
利用hdfs gateway挂载NFS到本地
HDFS NFS Gateway
HDFS提供了基于NFS(Network File System)的插件,可以对外提供NFS网关,供其它系统挂载使用。 NFS网关支持NFSv3,并允许将HDFS作为客户机本地文件系统的一部分挂载,现在支持: 上传、下载、删除、追加内容 我们通过…
Hadoop、HDFS、Hive、Hbase区别及联系
Hadoop、HDFS、Hive和HBase是大数据生态系统中的关键组件,它们都是由Apache软件基金会管理的开源项目。下面将深入解析它们之间的区别和联系。
Hadoop
Hadoop是一个开源的分布式计算框架,它允许用户在普通硬件上构建可靠、可伸缩的分布式系统。Hadoop通常指的是整个生态系统…
当我们说大数据Hadoop,究竟在说什么?
提到大数据,大抵逃不过两个问题,一个是海量的数据该如何存储,另外一个就是那么多数据该如何进行查询计算呢。
好在这些问题前人都有了解决方案,而Hadoop就是其中的佼佼者,是目前市面上最流行的一个大数据软件…
Hive表使用ORC格式和SNAPPY压缩建表语句示例
Hive表使用ORC格式和SNAPPY压缩建表语句示例
下面是一个sql示例:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS mydatabase;-- 使用数据库
USE mydatabase;-- 创建分区表,使用ORC文件格式,采用Snappy压缩算法
CREATE TABLE IF NOT EXISTS …

业财一体化架构设计与实现总结
随着企业经营环境的日益复杂和多变,业务和财务之间的紧密结合变得愈发重要。在这样的背景下,业务与财务一体化管理成为了企业信息化建设的重要趋势。本文将探讨业务与财务一体化架构的设计与实现,帮助企业更好地整合业务流程,优化…
安装CDH平台的服务器磁盘满了,磁盘清理过程记录
1.使用hdfs命令查看哪个文件占用最大
hdfs dfs -du -h /tmp
2.我的服务器上显示/tmp/hive/hive文件夹下的,一串字符串命名的文件特别大几乎把磁盘占满了
网上查到/tmp文件是临时文件,由于hiveserver2任务运行异常导致缓存未删除,正常情况下…
外卖平台订餐流程架构的实践
当我们想要在外卖平台上订餐时,背后其实涉及到复杂的技术架构和流程设计。本文将就外卖平台订餐流程的架构进行介绍,并探讨其中涉及的关键技术和流程。
## 第一步:用户端体验
用户通过手机应用或网页访问外卖平台,浏览菜单、选择…
![DataNode启动报错Failed to add storage directory [DISK]file:【已解决】](https://img-blog.csdnimg.cn/50abfce494904acdafd827b1a8d91282.png)
DataNode启动报错Failed to add storage directory [DISK]file:【已解决】
Failed to add storage directory [DISK]file hadoop启动后缺少DataNode进程报错out文件报错log文件解决 hadoop启动后缺少DataNode进程
jps查看hadoop进程缺少DataNode的进程
报错out文件
查看DataNode的out日志 DataNode启动报错
ulimit -a for user root
core file size…
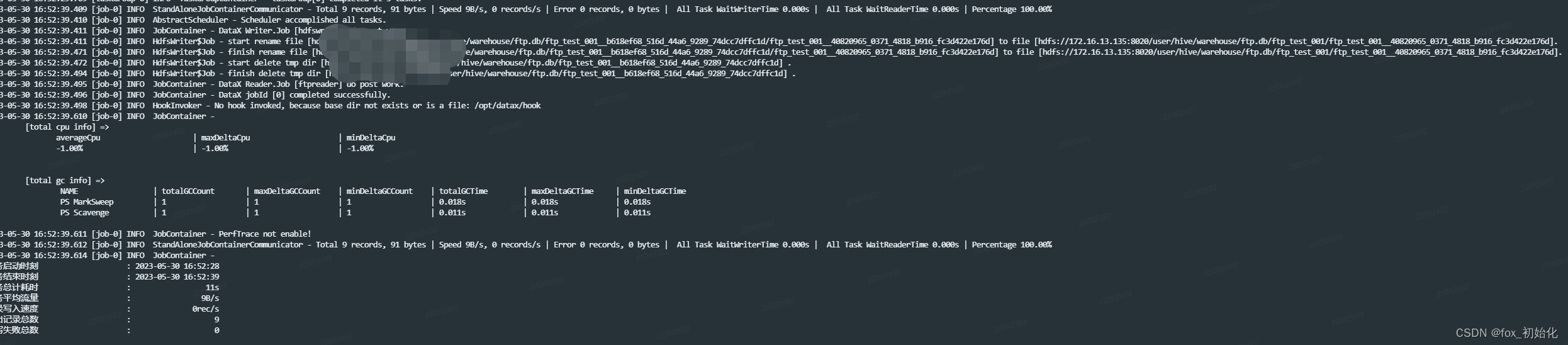
Datax ftp写入hive
这是一个巨大的坑,网上对这块的完整描述真的很少,新手真的会很迷茫!!!
插件
选择插件
reader插件选择:ftpread
write插件选择:hdfswrite
参数配置
reader参数
"parameter": {/…
20230611_Hadoop_BigDataTools
Hadoop客户端
一、Big Data Tools工具 Pycharm专业版下载Big Data Tools工具。 获取hadoop.dll与winutils.exe文件放置于$HADOOP_HOME/Bin中。 配置系统环境变量:E:\hadoop-3.3.4 配置Big Data Tools,登录。 -- 如果需要走第二种路径配置登录, 需要修…
java 客户端操作HDFS
1、windows上部署hadoop包
部署包win版本
源码包zip包
lib整合:共121个jar包 $HADOOP_PREFIX/share/hadoop/{common,hdfs,mapreduce,yarn,tools}/{lib,.}*.jar 将windows版本hadoop/bin/hadoop.dll 放到c:/windows/system32下
2、windows环境变量配置
hadoop的…
【Hadoop】HDFS编程
1、初始化配置信息:
Testpublic void init() throws IOException, URISyntaxException, InterruptedException {Configuration configuration new Configuration();configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSyst…
HDFS的基本操作(创建目录或文件、查看目录或文件、上传和拷贝文件到HDFS上、追加数据到HDFS上、从HDFS上下载文件到Linux本地、合并HDFS文件)
文章目录 前言一、HDFS的相关命令1、在HDFS创建目录2、查看当前目录3、查看目录与子目录4、查看文件的内容5、创建文件6、上传和拷贝文件7、追加数据到HDFS文件中8、下载文件到Linux本地系统9、合并HDFS上多个小文件,并下载到本地10、删除HDFS上的指定目录下的文件1…
Java操作Apache HBase API以及HBase和MapReduce整合
Java操作HBase API
添加依赖 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.apache.hadoop</g…

java实现从HDFS上下载文件及文件夹的功能,以流形式输出,便于用户自定义保存任何路径下
文章目录java实现下载hdfs文件及文件夹说明:java实现从HDFS上下载文件及文件夹的功能,以流形式输出,便于用户自定义保存任何路径下1.下载xxx文件2.下载xx文件夹java实现下载hdfs文件及文件夹
说明:java实现从HDFS上下载文件及文件…
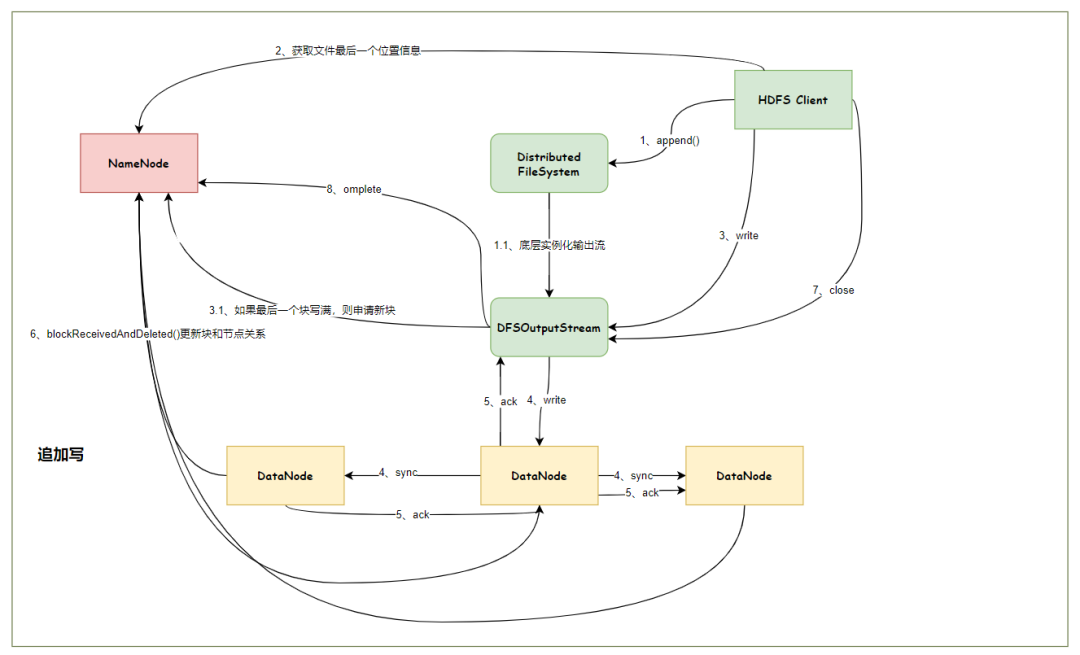
Hadoop三部曲搞起~
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料(密码每周更新一次)
入门大数据,通常先从Hadoop学习。通过本文可以学习到以下几点: Hadoop基本特性 HDFS读流程 HDFS写流程 HDFS追加流程 HDFS数…
Shell 检查HDfS文件
平常脚本运行需要检查对应hdfs路径相关信息,总结一下:
Tip: 假设要检查的路径为check_path
1.获取路径文件大小并转化为规定单位 Byte,K,M,G
bytes获取文件大小,单位为字节;base为转换单位的基准,我这里取1G&#x…
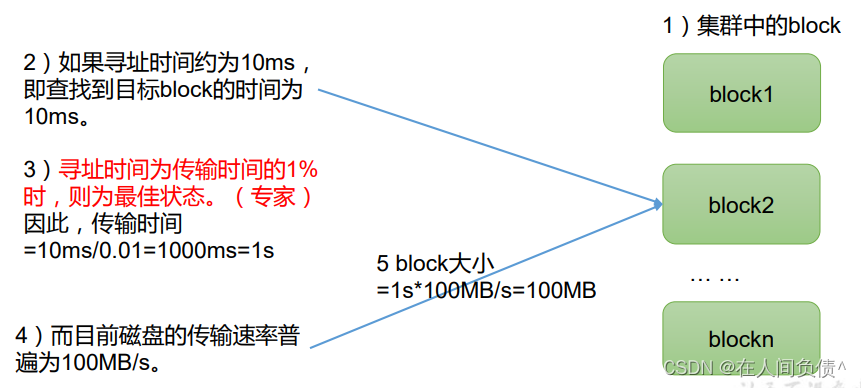
Hadoop 3.x(HDFS)----【HDFS 概述】
Hadoop 3.x(HDFS)----【HDFS 概述】1. HDFS产生背景及定义1. HDFS产生背景2. HDFS定义2. HDFS优缺点1. HDFS优点2. HDFS缺点3. HDFS组成架构4. HDFS文件块大小1. HDFS产生背景及定义
1. HDFS产生背景
随着数据量越来越大,在一个操作系统存不…

HDFS架构中重要概念
HDFS Hadoop Distributed File System 分布式文件存储 1.主从式架构 2.存储数据时,没有物理上线
注意: HDFS集群 不适合存储大量的小文件 HDFS集群 存储的文件 使用一次写入多次操作场景
NameNode集群中主节点(内存) 1.维护了树…
一百七十二、Flume——Flume采集Kafka数据写入HDFS中(亲测有效、附截图)
一、目的
作为日志采集工具Flume,它在项目中最常见的就是采集Kafka中的数据然后写入HDFS或者HBase中,这里就是用flume采集Kafka的数据导入HDFS中
二、各工具版本
(一)Kafka
kafka_2.13-3.0.0.tgz
(二)…
修炼k8s+flink+hdfs+dlink(一:安装flink)
一:standalone的ha环境部署。
创建目录,上传安装包。
mkdir /opt/app/flink
上传安装包到本目录。
tar -zxvf flink-1.13.6-bin-scala_2.12.tgz配置参数。 在flink-conf.yaml中添加zookeeper配置
jobmanager.rpc.address: node01
high-availability: …

【大数据Hadoop】HDFS3.3.1-Datanode-DataStorage的实现原理
DataStorage的实现原理 前言Storage类继承关系StorageInfoStorage.StorageStateStorage.StorageDirectory文件夹操作加锁/解锁操作存储状态恢复操作 StorageDataStorage 前言
Datanode 最重要的功能就是管理磁盘上存储的 HDFS 数据块。Datanode 将这个管理功能切分为两个部分&…
已解决org.apache.hadoop.hdfs.protocol.QuotaExceededException异常的正确解决方法,亲测有效!!!
已解决org.apache.hadoop.hdfs.protocol.QuotaExceededException异常的正确解决方法,亲测有效!!!
目录
问题分析
报错原因
解决思路
解决方法
总结 博主v:XiaoMing_Java 问题分析
在使用Hadoop分布式文件系统&a…
hdfs.DataStreamer: Exception in createBlockOutputStream XXXXX
报错信息:
java.io.IOException: Got error, statusERROR, status message , ack with firstBadLink as 192.168.100.13:9866at org.apache.hadoop.hdfs.protocol.datatransfer.DataTransferProtoUtil.checkBlockOpStatus(DataTransferProtoUtil.java:134)at org.a…
HDFS WebHDFS 读写文件分析及HTTP Chunk Transfer Encoding相关问题探究
文章目录 前言需要回答的首要问题DataNode端基于Netty的WebHDFS Service的实现基于重定向的文件写入流程写入一个大文件时WebHDFS和Hadoop Native的块分布差异 基于重定向的数据读取流程尝试读取一个小文件尝试读取一个大文件 读写过程中的Chunk Transfer-Encoding支持写文件使…

【大数据】了解 YARN 架构的基础知识
了解 YARN 架构的基础知识 1.为什么是 YARN2.YARN 简介3.YARN 的组成部分3.1 Resource Manager 资源管理器3.1.1 Scheduler 调度程序3.1.2 Application Manager 应用程序管理器 3.2 Node Manager 节点管理器3.3 Application Master 应用程序主控3.4 Container 容器 4.在 YARN 中…

本机无法访问虚拟机hdfs文件系统
解决
1.首先查看虚拟机hadoop是否已经启动服务
2.查看虚拟机防火墙是否开启
systemctl status iptables出现:
Unit iptables.service could not be found.因为CentOS7没有iptables.service,安装一下即可:
yum install iptables-service…

【Hadoop大数据技术】——HDFS分布式文件系统(学习笔记)
📖 前言:Hadoop的核心是HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)和MapReduce。其中,HDFS是解决海量大数据文件存储的问题,是目前应用最广泛的分布式文件系统。 目录 &#x…
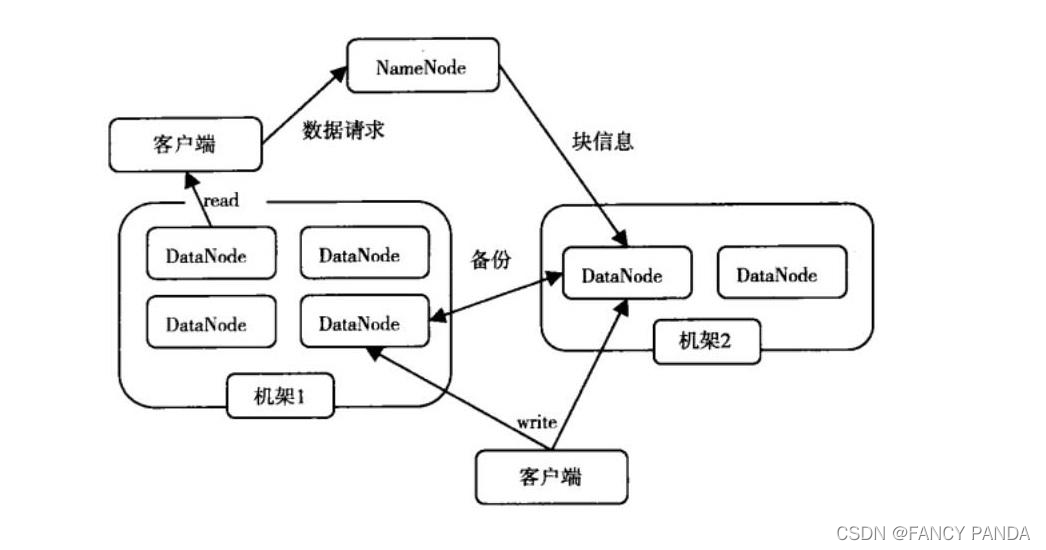
恢复HDFS上误删除的文件
1. 通过回收站恢复
HDFS 为我们提供了垃圾箱的功能,也就是说当我们执行 hadoop fs -rmr xxx 命令之后,文件并不是马上被删除,而是会被移动到 执行这个操作用户的 .Trash 目录下,等到一定的时间后才会执行真正的删除操作。看下面的…
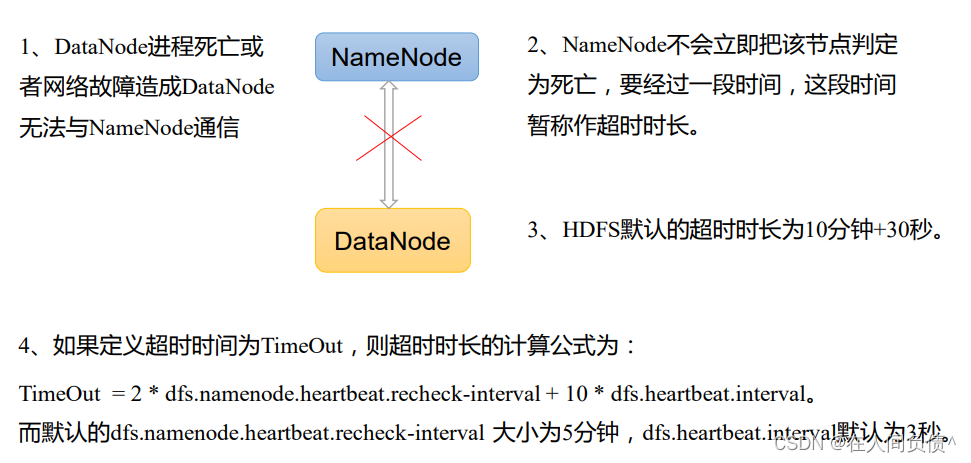
Hadoop 3.x(HDFS)----【DataNode】
Hadoop 3.x(HDFS)----【DataNode】1. DataNode工作机制2. 数据完整性3. 掉线时限参数设置1. DataNode工作机制 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的…
Hive查询转换与Hadoop生态系统引擎与优势
目录 摘要一、Hive是什么二、HDFS是什么三、Hive与HDFS的关系四、什么是HiveQL五、什么是mapreduce六、Hive如何将查询转为mapreduce任务七、Hadoop生态系统中的高性能引擎八、使用Hadoop的优点 摘要
Hadoop生态系统中包含了多个关键组件,如Hive、HDFS、MapReduce等…
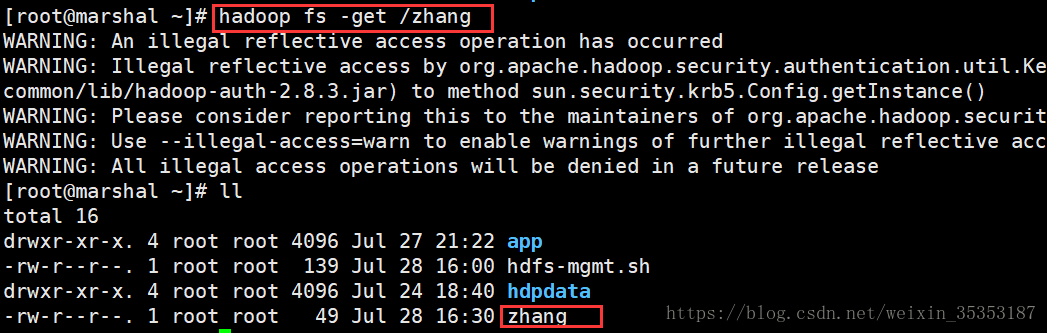
彷徨 | HDFS客户端基本shell操作
# HDFS 的shell练习
# hdfs version 查看HDFS版本 # hadoop fs -ls / 查看HDFS根目录下的文件和目录 # hdfs dfs -ls -R /这条会列出/目录下的左右文件,由于有-R参数,会在文件夹和子文件夹下执行ls操作 , 会递归 # hadoop fs -mkdir /test 在根目录创建…
彷徨 | HDFS客户端API编程基本java操作 | 一
1 : 上传本地文件到HDFS Testpublic void testUpload() throws Exception {Configuration conf new Configuration();//默认值,可以不设置conf.set("dfs.blocksize", "128m");// 1.先获取一个访问HDFS的客户端对象 // 参数1:URI-…
如何使用Java API读写HDFS
[b][colorgreen][sizelarge]HDFS是Hadoop生态系统的根基,也是Hadoop生态系统中的重要一员,大部分时候,我们都会使用Linux shell命令来管理HDFS,包括一些文件的创建,删除,修改,上传等等ÿ…
HDFS文件查改增删及上传下载
1. 文件查改增删
1.1 查看文件
# 查看某目录下的文件
hadoop fs -ls <path># 显示文件大小
hadoop fs -du -h <path>
# 显示文件大小,s代表显示只显示总计(列出最后的和)。
hadoop fs -du -s -h <path># 输出文件内容
hadoop fs -cat <path…
成为卓越数据科学家必备的 13 项技能
一周前,我在 LinkedIn 上问了一个问题:优秀的数据科学家与卓越的数据科学家之间的区别是什么? 令人惊讶的是,我得到了来自各行各业的许多顶尖数据科学家的积极反馈。 我发现这非常实用和有趣。为了进一步了解二者间的区别,我一直…
大数据开发实战系列之Spark电商平台
源于企业级电商网站的大数据统计分析平台,该平台以 Spark 框架为核心,对电商网站的日志进行离线和实时分析。
该大数据分析平台对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行分析,根据平台统计出…
Hadoop2.x学习笔记-1(Hadoop架构+NTP集群时间同步配置)
一、前言 本人认为,学习一门技术首先需要系统的了解技术整个框架,才能让自己对这门技术的理解更进一步。同时,先有理论,后有技术的出现。这代表着,我们需要在学习好理论基础的前提上完成实践的操作,这样才能…
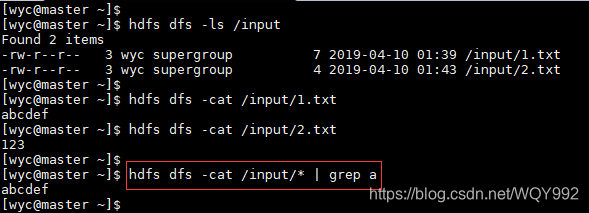
HDFS dfs常用命令大全
根据官方文档的提示我们能够知道可以通过shell的方式访问hdfs中的数据,对数据进行操作。那么首先让我们看一下hdfs的版本,使用命令hdfs version。 -mkdir
创建目录 Usage:hdfs dfs -mkdir [-p] < paths> 选项:-p 很像Unix m…

Hadoop(一):初始Hadoop
Linux安装hadoop:
参考:【Linux】安装hadoop详细步骤_Code.Knight的博客-CSDN博客_linux安装hadoop
这里要注意的是,修改主机名要慎重,可以不修改。 解决报错
启动 hdfs 会报错:temporary failure in name resoluti…
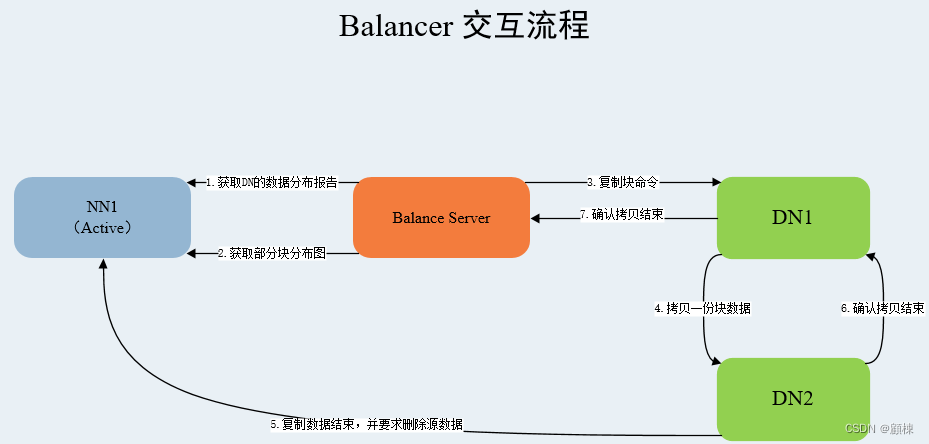
【HDFS实战】HDFS上的数据均衡
HDFS上的数据均衡简介 文章目录 HDFS上的数据均衡简介重新平衡多DN之间的数据相关命令 重新平衡单DN内磁盘间的数据相关命令PlanExecuteQueryCancelReport 相关配置调试 HDFS上的balance目前有两类: Balancer:多数据节点之间的balanceDisk Balancer&…
重启namenode速度慢,耗时很久加载fsimage问题解决办法
如果重启namenode速度慢,耗时很久加载fsimage问题解决办法 可以需要定期执行以下命令提前合并元数据。
hdfs dfsadmin -safemode enter
hdfs dfsadmin -saveNamespace
hdfs dfsadmin -safemode leave (在关闭hdfs服务前,执行一上命令&#…
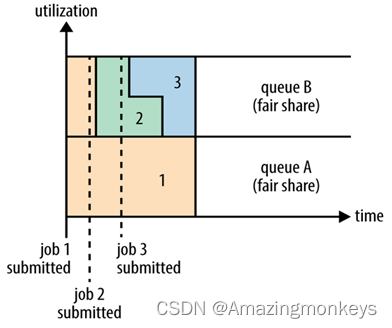
Hadoop 3:YARN
YARN简介
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器。 YARN是一个【通用资源管理系统和调度平台】,可为上层应用提供统一的资源管理和调度。 它的引入为集群在利用率、…
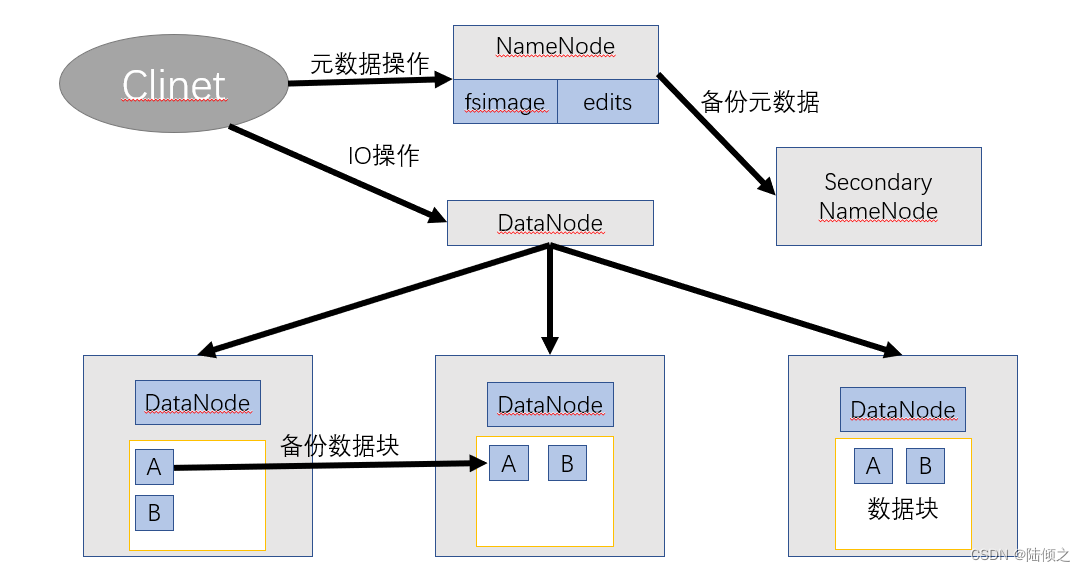
Hadoop的HDFS文件系统
Hadoop的HDFS文件系统
概述
Hadoop的HDFS文件系统是一种分布式文件系统,hadoop的核心组件之一。它的设计目标是能够在普通硬件上运行,并且能够处理大量的数据。HDFS采用了主从(Master/Slave)架构,其中有一个NameNode…

五、hdfs常见权限问题
1、常见问题 2、案例
(1)问题 (2)hdfs的超级管理员 (3)原因 没有使用Hadoop用户对hdfs文件系统进行操作。 在Hadoop文件系统中,Hadoop用户相当于Linux系统中的root用户,是最高级别用…
![[Hadoop]Apache Hadoop、HDFS](https://img-blog.csdnimg.cn/92dd458754534d6d9506357057eda08c.png)
[Hadoop]Apache Hadoop、HDFS
目录
大数据导论与Linux基础
Apache Hadopp概述
Hadoop介绍
Hadoop现状
Hadoop特性优点
Hadopp架构变迁
Apache Hadopp集群搭建
Hadopp集群简介
Hadoop集群模式安装
Hadoop集群启停命令、Web UI
HDFS分布式文件系统基础
分布式存储系统的核心属性及功能含义
HDFS简…

Spark Catalyst
Spark Catalyst逻辑计划逻辑计划解析逻辑计划优化Catalyst 规则优化过程物理计划Spark PlanJoinSelection生成 Physical PlanEnsureRequirementsSpark SQL 端到端的优化流程:
Catalyst 优化器 : 包含逻辑优化/物理优化Tungsten :
Spark SQL的优化过程 : 逻辑计划 …
大数据 - Hadoop系列《三》- MapReduce(分布式计算引擎)概述
上一篇文章:
大数据 - Hadoop系列《三》- HDFS(分布式文件系统)概述-CSDN博客 目录
12.1 针对MapReduce的设计构思
1. 如何对付大数据处理场景
2. 构建抽象编程模型
3. 统一架构、隐藏底层细节
12.2 分布式计算概念
12.3 MapReduce定义…

大数据--hdfs--java编程
环境:
virtualbox ubantu1604 Linux idea社区版2023
jdk1.8
hadoop相关依赖
使用java操作
1. 判断/user/stu/input/test.txt文件是否存在,存在则读出文件内容,打印在控制台上。反之,输出“文件不存在”。
package abc;impo…
Linux(centos7)部署hadoop集群
部署环境要求:已完成JDK环境部署、配置完成固定IP、SSH免费登录、防火墙关闭等。
1、下载、上传主机 官网:https://hadoop.apache.org 2、解压缩、创建软连接 解压:
tar -zxvf hadoop-3.3.6.tar.gz软连接:
ln -s /usr/local/apps/hadoop-3.3.6 hadoop3、文件配置 hadoo…

hadoop HDFS分布式计算概述,MapReduce概述,YARN概述
1、分布式计算概述
1.1、什么是(数据)计算
我们一直在提及:分布式计算, 分布式暂且不论, “计算”到底是指什么呢?
大数据体系内的计算, 举例:
销售额统计、区域销售占比、季度…

【大数据】Doris 构建实时数仓落地方案详解(一):实时数据仓库概述
Doris 构建实时数仓落地方案详解(一):实时数据仓库概述 1.数据仓库的发展历程2.数据仓库技术的发展3.数仓的相关技术栈4.OLAP 查询5.MPP 架构6.实时数仓定义7.实时数仓的难点 数据仓库的概念可以追溯到 20 世纪 80 年代,当时 IBM …
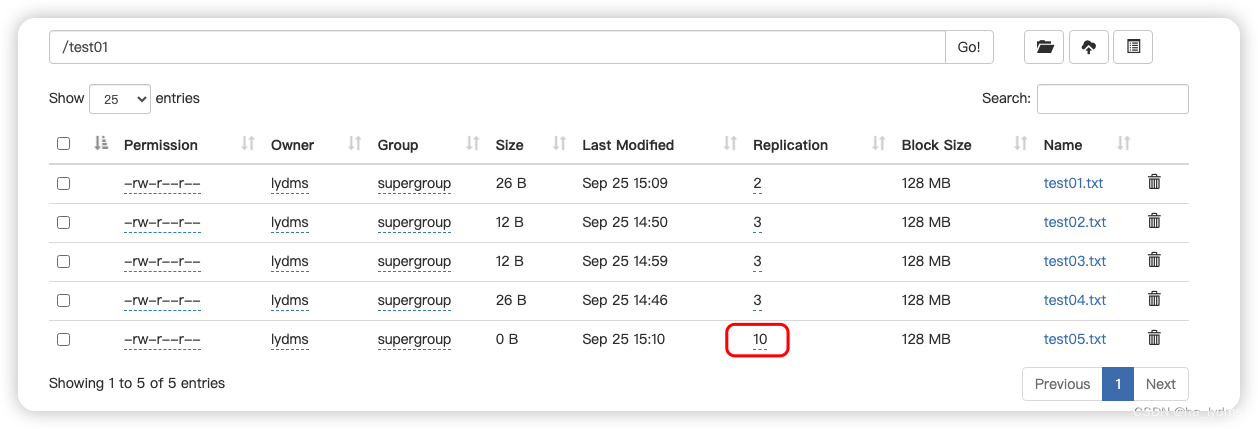
【HDFS】客户端读某个块时,如何对块的各个副本进行网络距离排序?
本文包含如下内容: ① 通过图解+源码分析/A1/B1/node1和 /A1/B2/node2 这两个节点的网络距离怎么算出来的 ② 客户端读文件时,副本的优先级。(怎么排序的,排序规则都有哪些?) ③ 我们集群发现的一个问题。
客户端读时,通过调用getBlockLocations RPC 获取文件的各个块。…

Hadoop理论及实践-HDFS四大组件关系(参考Hadoop官网)
NameNode(名称节点,Master主节点)
NameNode主要功能 1、NameNode负责管理HDFS文件系统的元数据,包括文件,目录,块信息等。它将元数据Fsimage与Edit_log持久化到硬盘上。一个是Fsimage(镜像文件)…
HDFS文件格式及压缩
HDFS(Hadoop Distributed File System)支持多种文件格式和压缩方式,这些格式和方式可以根据数据类型和处理需求进行选择。以下是一些常见的HDFS文件格式和压缩方式:
常见的HDFS文件格式: SequenceFile: SequenceFile是Hadoop中一种二进制文件格式,用于存储键-值对。它适…
HDFS之DataNode动态添加与卸载
动态添加一个DataNode集群扩容需要添加新DataNode,通常是在需要增加存储的情况下,虽然有时也是为了增加IO总带宽或减小单台机器失效的影响。在运行中的HDFS集群上增加新的DataNode是一个在线操作或热操作。对于要使用HDFS主机及功能的用户,新…
修复hive重命名分区后新分区为0的问题
hive分区重命名后,新的分区的分区大小为0 , 例如 alter table entersv.ods_t_test partition(dt2022-11-08) rename to partition(dt2022-11-21) ods_t_test 的2022-11-21分区大小为0。怎样修复 使用 msck repair table 命令来修复表的元数据,让hive重新…
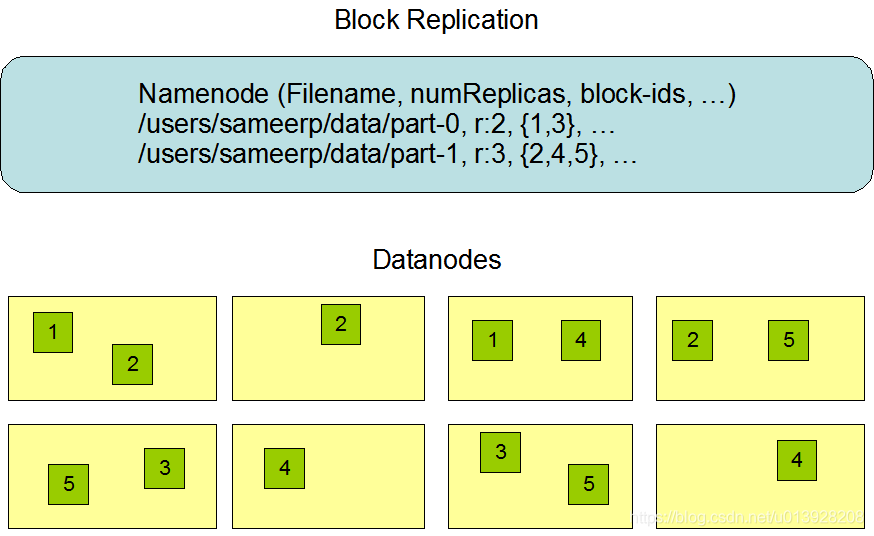
Hadoop2.8.5 分布式文件系统HDFS
Hadoop的两大系统之一“HDFS”。所谓分布,是说整个文件系统的内容并非集中存储在一台或几台“文件服务器上”,而是分散在集群的不同节点上。理想的情景是集群内的每一台机器都承担着一些内容的存储。HDFS 是 Hadoop 集群的文件系统,这是一种分布( distributed )、容错( faultto…

Java进行Hbase查询
Hbase存储结构和查询方式已经有所了解,如何调用连接并且进行数据查询呢,可以使用jmeter的Java脚本进行操作. Hbase查询主要是scaner通过滤器filter进行操作,根据要查询列族还是rowkey可分为多种filter,可根据具体条件来进行查询&a…

0202hdfs的shell操作-hadoop-大数据学习
文章目录 1 进程启停管理2 文件系统操作命令2.1 HDFS文件系统基本信息2.2 介绍2.3 创建文件夹2.4 查看指定文件夹下的内容2.5 上传文件到HDFS2.6 查看HDFS文件内容2.7 下载HDFS文件2.8 HDFS数据删除操作 3 HDFS客户端-jetbrians产品插件3.1 Big Data Tools 安装3.2 配置windows…

【HDFS】分布式文件系统的常用HDFS操作
先理解 Shell命令行 ●.启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh⑴.将本地的house.txt文件上传到HDFS的mydir目录下
./bin/hdfs dfs -put ./house.txt mydir⑵.将HDFS的dir目录下的house.txt下载 到本地
./bin/hdfs dfs -get mydir/house.txt file:///usr/loc…
HDFS常用命令常用
常用HDFS命令说明hadoop fs -mkdir dir新建HDFS目录dirhadoop fs -mkdir -p /dir1/dir2/dir3建立多层目录hadoop fs -ls /Input列出”/Input”目录下的文件和目录hadoop fs -ls -R /Input列出”/Input”目录下所有子目录及目录里的文件hadoop fs -copyFromLocal file dir将本地…

DataX 概述、部署、数据同步运用示例
文章目录 什么是 DataX?DataX 设计框架DataX 核心架构DataX 部署DataX 数据同步 MySQL —> HDFSDataX 数据同步 HDFS —> MySQLDataX 优化同步 MySQL 中 NULL 值数据到 HDFS 出现错误配置文件变量传参 什么是 DataX?
DataX 是阿里巴巴集团开源的、…
高可用Hadoop大数据部署流程
补充:mp引擎切换为tez、解决yarn 8081端口报错问题
解决hive comment中文乱码问题:hive-site配置如下
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.4.151.58:3306/hive?allowMultiQueriestrue&…
Windows平台Hadoop的安装与配置
Windows下运行Hadoop,通常有两种方式:
第一种是用VM方式安装一个Linux操作系统,这样基本可以实现全Linux环境的Hadoop运行。第二种是通过Cygwin模拟Linux环境。
后者的好处是使用比较方便,安装过程也简单。在这里咱们就基于第二…
DEPRECATED: Use of this script to execute hdfs command is deprecated.
在window下安装hadoop,在执行$ bin/hadoop namenode -format命令时出现上述错误。 看了网上的很多解决方案,有人说是配置原因,有人说事JAVA_HOME的原因,还有人建议将命令中的hadoop换成hdfs,但是都没解决我的问题。
…
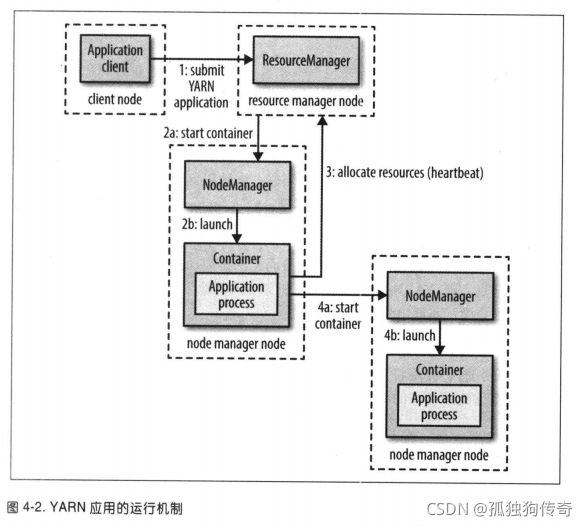
一起艳学大数据Hadoop(三)——java操作HDFS的增删改查
具体过程描述如下:
1、Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象 2、通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Names…

Spark与hdfs delegation token过期的排查思路总结
背景
hadoop delegation token的问题相对比较混乱和复杂,简单说下这东西的出现背景,最早的hadoop的因没有的完善的安全机制(安全机制主要包括:认证 鉴权,hadoop这里主要是身份认证机制没有),所…

数据导入hudi报错,错将字段写到hdfs路径上
报错信息
Error trying to save partition metadata (this is okay, as long as atleast 1 of these succced), file:/qiche/hudi_table/冬天续航要打个八折的样子,能接受。高速相对市区还要耗电一些。不过这个车最主要是也就是在市区里面跑,而且最多会…
HDFS的原理漫画详解
1、3个部分,客户端client,nameNode(存放元数据及其他信息的节点),dataNode(实际存放数据的节点) 2、如何写数据过程 3、读取数据的过程 4、容错:故障类型及其检测方法 5、读写容错 6…
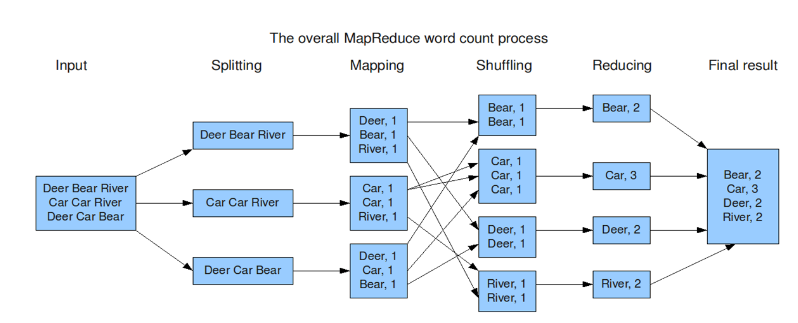
Hadoop基本介绍
1、Hadoop的整体框架 Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。 &…
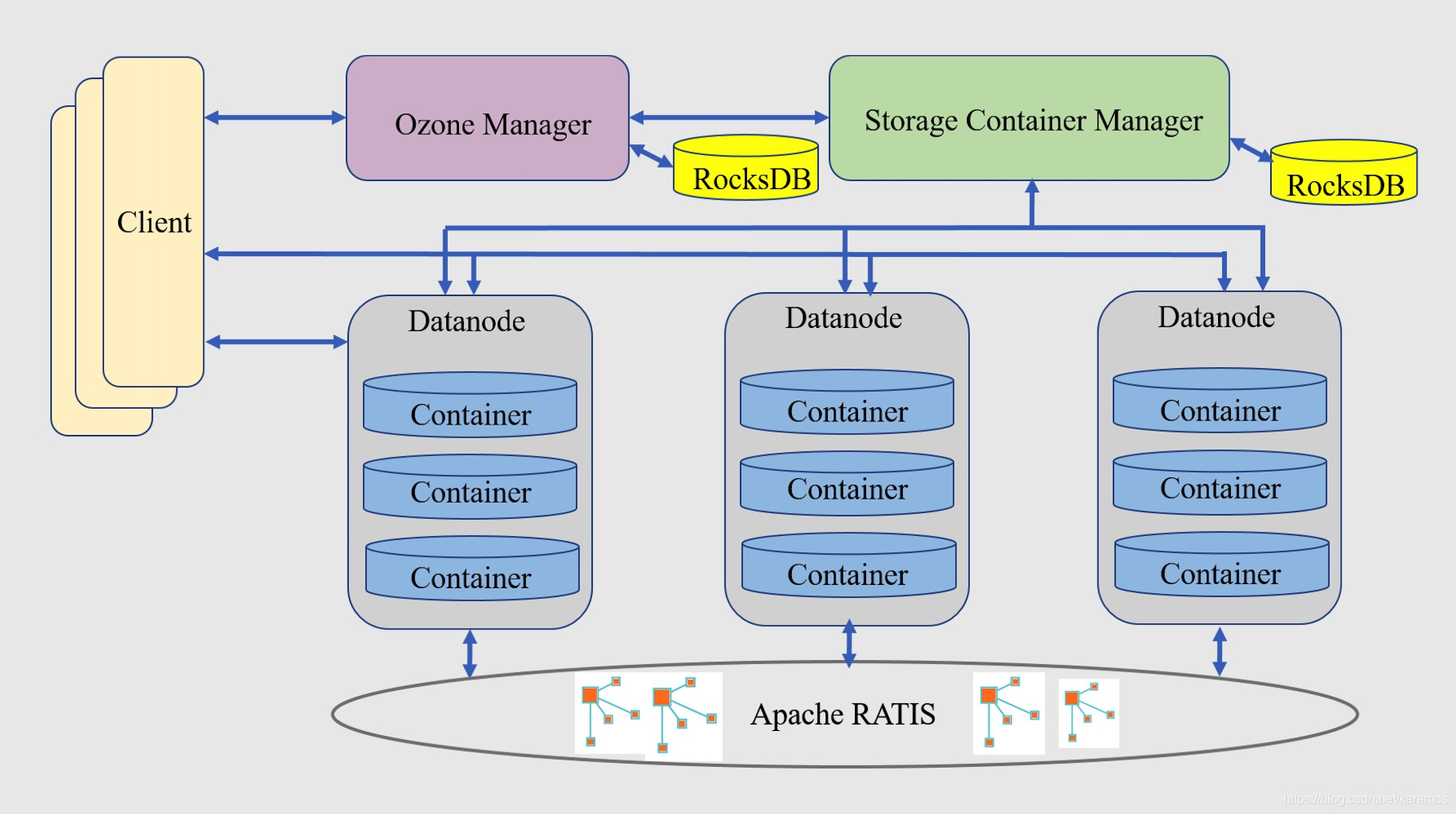
腾讯云大数据团队主导Apache社区新一代分布式存储系统Ozone 1.0.0发布
刚刚获悉,由腾讯云大数据团队主导的Ozone 1.0.0版本在Apache Hadoop社区正式发布。据了解,经过2年多的社区持续开发和内部1000节点的实际落地验证,Ozone 1.0.0已经具备了在大规模生产环境下实际部署的能力。
Ozone 是Apache Hadoop社区推出的…
Hadoop的hdfs
1、Hadoop是什么 实际应用:
(1)FlumeLogstashKafkaSpark Streaming进行实时日志处理分析 1.1、小故事版本的解释
小明接到一个任务:计算一个100M的文本文件中的单词的个数,这个文本文件有若干行,每行有若…

HDFS文件删除后,HIVE元数据还存在的问题
一.背景 手动在hdfs上删除了一个表的分区数据(inc_day2023-08-30),当查询这个表这个分区的数据时报错文件不存在 二.原因 即HDFS数据删除了,但是hive metastore元数据却没有更新,使用show partitions tablename 发现该分区还存在 三.解决办法…
Hive 和 HDFS、MySQL 之间的关系
文章目录 HiveHDFSMySQL三者的关系 Hive、MySQL 和 HDFS 是三个不同的数据存储和处理系统,它们在大数据生态系统中扮演不同的角色,但可以协同工作以支持数据管理和分析任务。
Hive Hive 是一个基于 Hadoop 生态系统的数据仓库工具,用于管理和…
HDFS 集群动态节点管理
目录
一、动态扩容、节点上线
1.1 背景
1.2 扩容步骤
1.2.1 新机器基础环境准备
1.2.2 Hadoop 配置
1.2.3 手动启动 DataNode 进程
1.2.4 Web 页面查看情况
1.2.5 DataNode 负载均衡服务
二、动态缩容、节点下线
2.1 背景
2.2 缩容步骤
2.2.1 添加退役节点
…
一百六十八、Kettle——用海豚调度器定时调度从Kafka到HDFS的kettle任务脚本(持续更新追踪、持续完善)
一、目的
在实际项目中,从Kafka到HDFS的数据是每天自动生成一个文件,按日期区分。而且Kafka在不断生产数据,因此看看kettle是不是需要时刻运行?能不能按照每日自动生成数据文件?
为了测试实际项目中的海豚定时调度从…

Hadoop架构再探讨——HDFS的设计改进(HA高可用+Federation联盟)
文章目录总述HDFS HAHDFS Federation总述
▍Hadoop1.0的局限与不足
抽象层次低,需要人工编写大量代码表达能力有限开发者自己管理作业(Job)之间的依赖关系难以看到程序的整体逻辑延迟高,因此迭代效率低浪费资源(分为…

【HBase】HBase数据库基本操作(Shell)
分享一个有趣的比喻: HBase像一个骑着大象的士兵,本身并不优秀,却可以耀武扬威——但需要养一头大象(Hadoop) 检查
▶ cd到Hadoop,开启HDFS
cd /usr/local/hadoop./sbin/start-dfs.sh▶ cd到Hbase&#x…
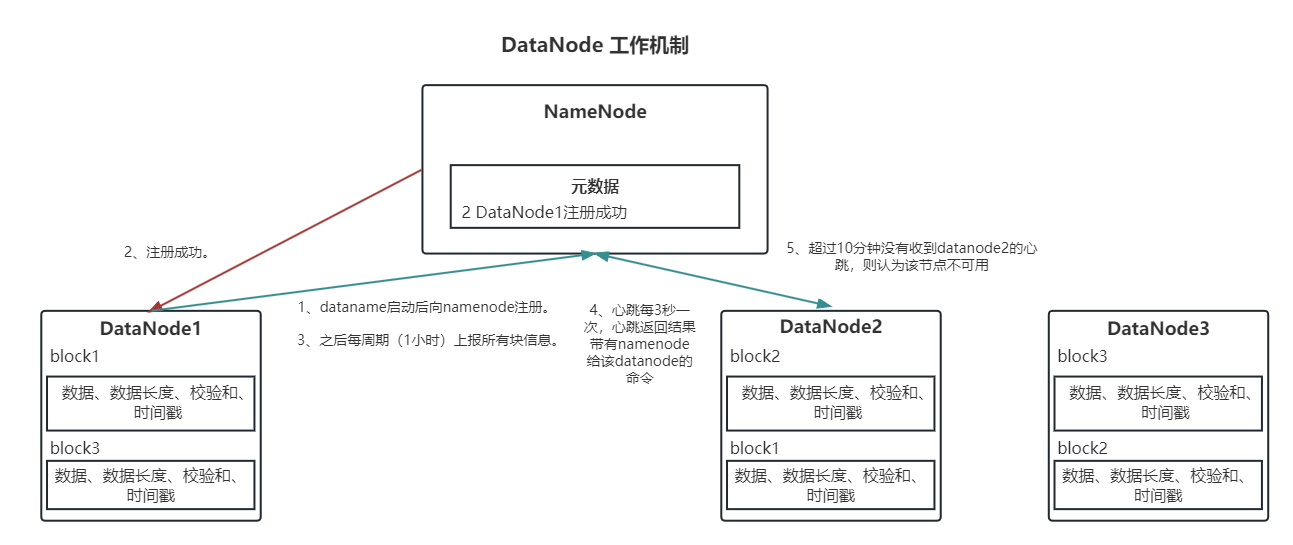
Hadoop的分布式文件存储系统HDFS组件的使用
Hadoop的第一个核心组件:HDFS(分布式文件存储系统) 一、HDFS的组成1、NameNode2、DataNode3、SecondaryNameNode4、客户端:命令行/Java API 二、HDFS的基本使用1、命令行操作2、Java API操作 三、HDFS的工作流程问题(H…

【Hadoop】HDFS API 操作大全
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助…

MapReduce YARN 的部署
1、部署说明
Hadoop HDFS分布式文件系统,我们会启动:
NameNode进程作为管理节点DataNode进程作为工作节点SecondaryNamenode作为辅助 同理,Hadoop YARN分布式资源调度,会启动:ResourceManager进程作为管理节点NodeM…
【HDFS】cachingStrategy的设置
org.apache.hadoop.hdfs.client.impl.BlockReaderFactory#getRemoteBlockReader: private BlockReader getRemoteBlockReader(Peer peer) throws IOException {int networkDistance = clientContext.getNetworkDistance(datanode);return BlockReaderRemote
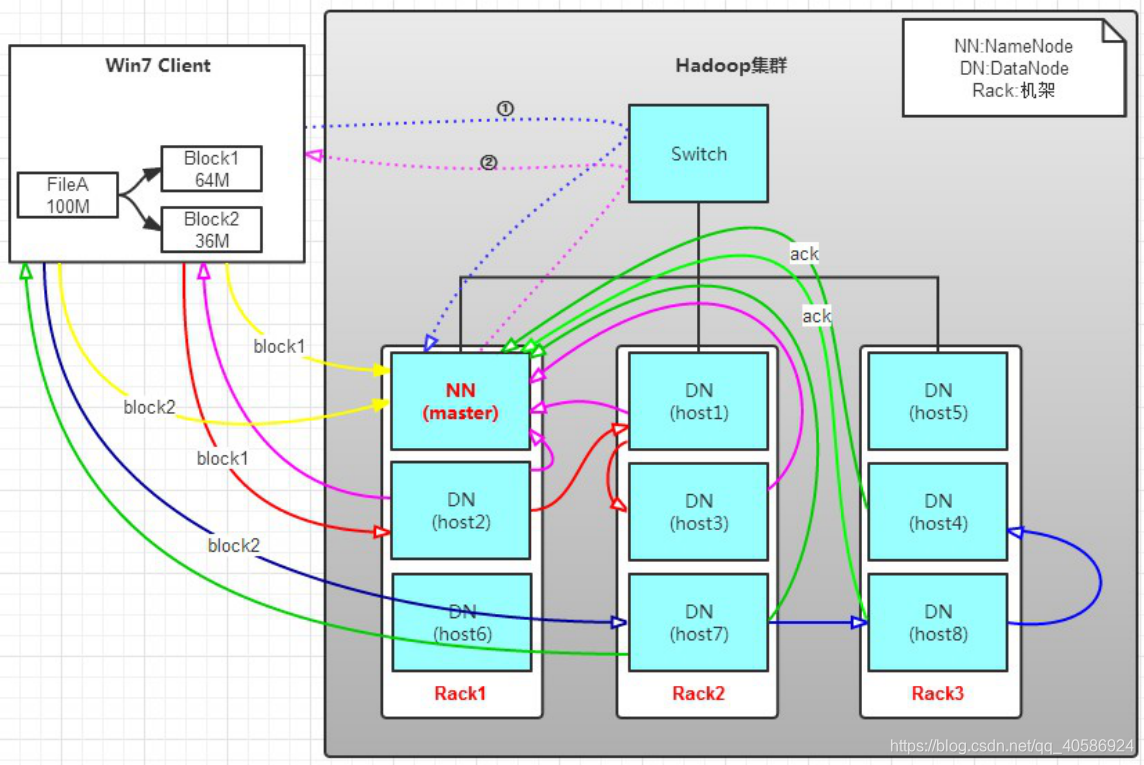
HDFS(hadoop distributed File System)详解
HDFS(hadoop distributed File System)分布式文件系统 特点:高容错性(多个文本副本存储),价格低,高吞吐量。 常见的系统 gfs,HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS。 Hdfs总体上采用了m…
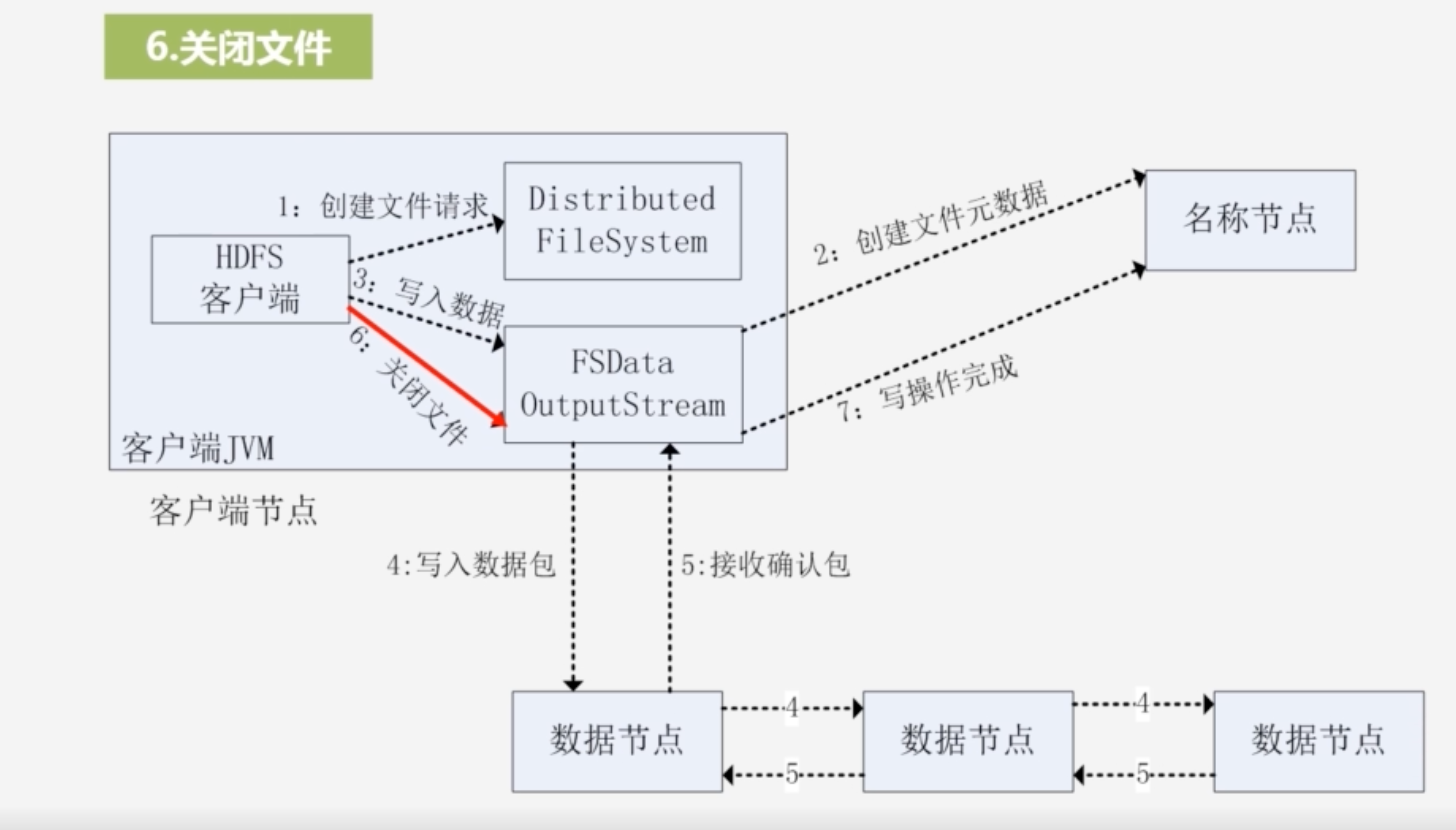
分布式文件系统HDFS(林子雨慕课课程)
文章目录 3. 分布式文件系统HDFS3.1 分布式文件系统HDFS简介3.2 HDFS相关概念3.3 HDFS的体系结构3.4 HDFS的存储原理3.5 HDFS数据读写3.5.1 HDFS的读数据过程3.5.2 HDFS的写数据过程 3.6 HDFS编程实战 3. 分布式文件系统HDFS
3.1 分布式文件系统HDFS简介 HDFS就是解决海量数据…

二百一十二、Flume——Flume实时采集Linux中的目录文件写入到HDFS中(亲测、附截图)
一、目的
在实现Flume实时采集Linux中的Hive日志写入到HDFS后,再做一个测试,用Flume实时采集Linux中的目录文件,即使用 Flume 监听Linux整个目录的文件,并上传至 HDFS中
二、前期准备
(一)安装好Hadoop、…
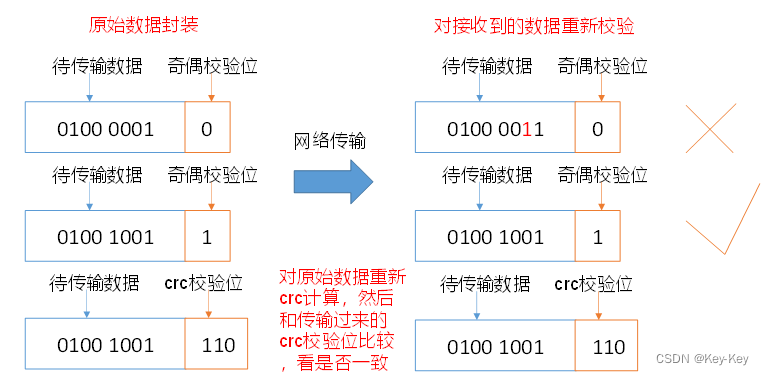
大数据开发之Hadoop(HDFS)
第 1 章:HDFS概述
1.1 HDFS产出背景及定义
1、HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的…
Linux 系统 CentOS7 上搭建 Hadoop HDFS集群详细步骤
集群搭建 整体思路:先在一个节点上安装、配置,然后再克隆出多个节点,修改 IP ,免密,主机名等 提前规划: 需要三个节点,主机名分别命名:node1、node2、node3 在下面对 node1 配置时,先假设 node2 和 node3 是存在的 **注意:**整个搭建过程,除了1和2 步,其他操作都使…

Ubuntu中启动HDFS后没有NameNode解决办法
关闭进程:
stop-dfs.sh
格式化:
hadoop namenode -format
出现报错信息:
23/10/03 22:27:04 WARN fs.FileUtil: Failed to delete file or dir [/usr/data/hadoop/tmp/dfs/name/current/fsimage_0000000000000000000.md5]: it still exi…
HDFS-命令行相关
HDFS-命令行相关 ls 列出目录mkdir 创建目录put 上传文件cp复制mv移动appendToFile内容追加cat ls 列出目录
hadoop fs -ls 需要查看的文件目录
如
hadoop fs -ls /mkdir 创建目录
hadoop fs -mkdir 需要创建的文件的路径
hadoop fs -mkdir /test/也可以使用 -p 参数创建多级…

Hadoop设置hdfs全局指令
在终端进入用户个人环境变量配置文件
vim ~/.bashrc
然后添加如下内容
export PATH$PATH:/usr/local/hadoop/bin
添加到你的hadoop下载目录的bin目录为止就可以了 重新激活一下配置文件
source ~/.bashrc
hdfs有专属于自己的文件存储目录,加上特殊的指令就可以箱终端一…

【大数据】Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读
Doris 构建实时数仓落地方案详解(二):Doris 核心功能解读 1.Doris 发展历程2.Doris 三大模型3.Doris 数据导入4.Doris 多表关联5.Doris 核心设计6.Doris 查询优化7.Doris 应对实时数仓的痛点 1.Doris 发展历程
Apache Doris 是由 百度 研发并…
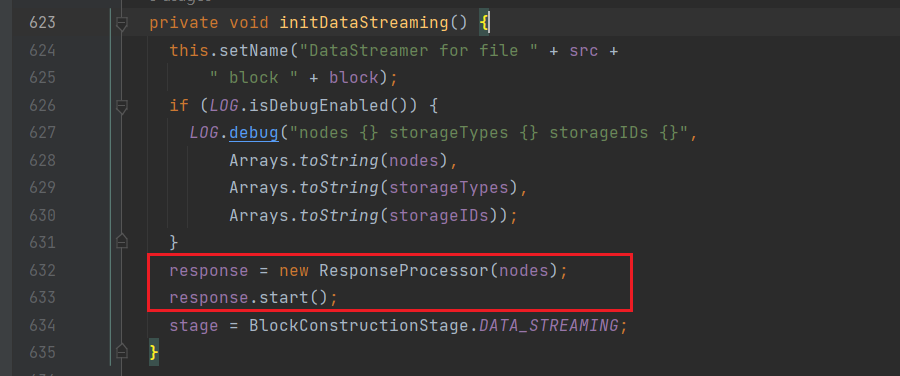
Hadoop源码阅读(三):HDFS上传
说明: 1.Hadoop版本:3.1.3 2.阅读工具:IDEA 2023.1.2 3.源码获取:Index of /dist/hadoop/core/hadoop-3.1.3 (apache.org) 4.工程导入:下载源码之后得到 hadoop-3.1.3-src.tar.gz 压缩包,在当前目录打开Pow…
docker拉取hadoop镜像做集群
该文docker常用命令 docker search imagename:搜索查找镜像 docker pull imagename:拉取镜像到本地仓库 docker images:查看本地镜像 docker ps:查看正在运行的容器 docker ps -a:查看所有容器 docker run --name mast…

修炼离线:(三)sqoop插入hbase 报错权限问题
一:报错现象。 二:解决方式。
方法一:修改文件所有者。
切换hadoop用户:export HADOOP_USER_NAMEhdfs
hadoop fs -chown -R root:root /方法二:修改权限
切换hadoop用户:export HADOOP_USER_NAMEhdfs
ha…
【大数据技术】实验2:熟悉常用的HDFS操作和基于MapReduce的词频统计
文章目录一、实验环境二、实验内容利用Hadoop提供的Shell命令完成以下任务利用HDFS的Java API编程实现以下任务功能编写MapReduce程序实现以下任务功能出现的问题一、实验环境
操作系统:Linux(建议Ubuntu16.04或Ubuntu18.04);Had…
java.nio.channels.SocketChannel[connection-pending remote=/xx.xx.xx.xx:9866]
目录 背景
问题描述
解决办法 背景
CDH集群在内网中部署,外网客户端需要正常提交任务到内网集群Yarn上,但外网客户端和内网网络不能直接连通,于是通过将内网中的每台主机绑定一个浮动ip,然后开通外网客户端和浮动ip之间的网络来…
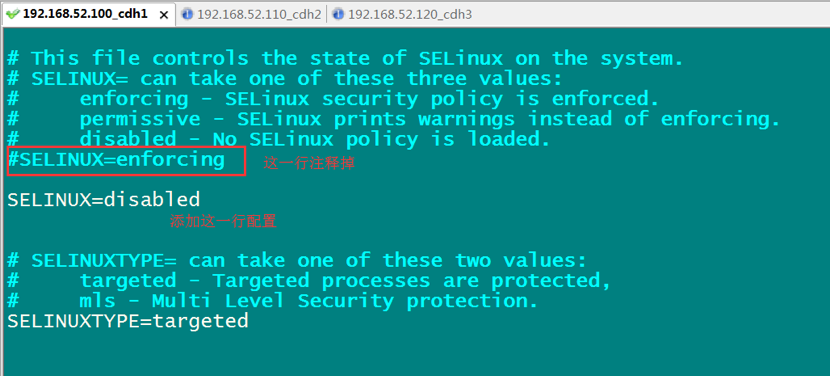
修炼k8s+flink+hdfs+dlink(五:安装dockers,cri-docker,harbor仓库,k8s)
一:安装docker。(所有服务器都要安装)
安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/cent…
深入理解 Hadoop (四)HDFS源码剖析
HDFS 集群启动脚本 start-dfs.sh 分析
启动 HDFS 集群总共会涉及到的角色会有 namenode, datanode, zkfc, journalnode, secondaryName 共五种角色。
JournalNode 核心工作和启动流程源码剖析
// 启动 JournalNode 的核心业务方法
public void start() throws IOException …
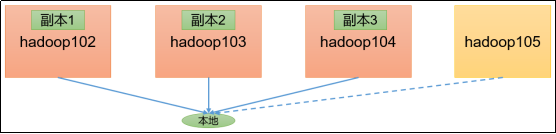
Hadoop3教程(二十七):(生产调优篇)HDFS读写压测
文章目录 (146)HDFS压测环境准备(147)HDFS读写压测写压测读压测 参考文献 (146)HDFS压测环境准备
对开发人员来讲,压测这个技能很重要。
假设你刚搭建好一个集群,就可以直接投入生…

hadoop在本地创建文件,然后将文件拷贝/上传到HDFS
1.要$cd {对应目录}进入到对应目录,一般为
cd /usr/local/hadoop/
2.创建文件,$sudo gedit {文件名},例
sudo gedit test.txt
然后在弹出的txt文件输入内容,点击右上角的保存之后,关闭即可。
3.拷贝本地文件到HDF…
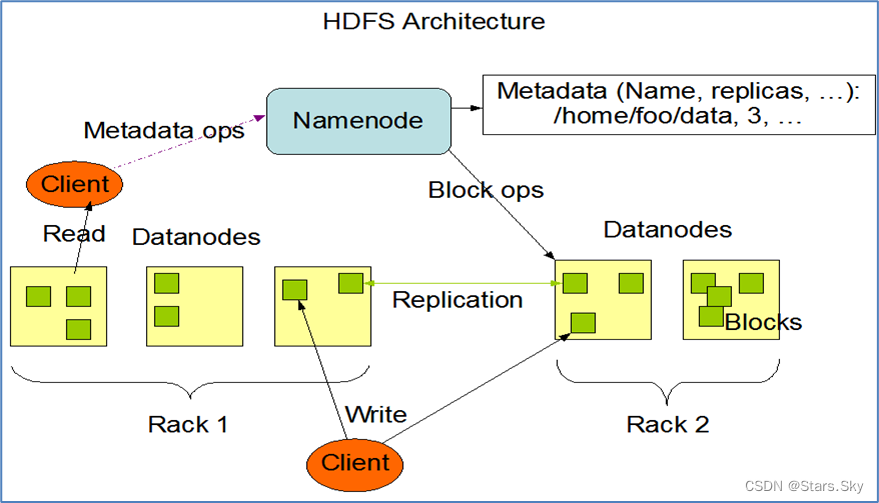
2023.11.22 -数据仓库的概念和发展
目录
https://blog.csdn.net/m0_49956154/article/details/134320307?spm1001.2014.3001.5501
1经典传统数仓架构
2离线大数据数仓架构
3数据仓库三层
数据运营层,源数据层(ODS)(Operational Data Store)
数据仓库层&#…
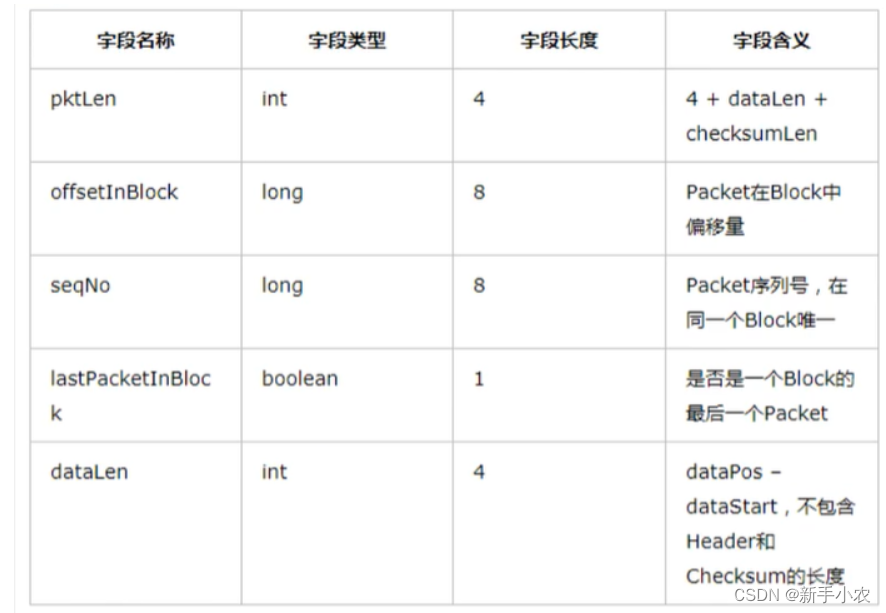
Hadoop -hdfs的读写请求
1、HDFS写数据(宏观):
1、首先,客户端发送一个写数据的请求,通过rpc与NN建立连接,NN会做一些简单的校验,文件是否存在,是否有空间存储数据等。
2、NN就会将校验的结果发送给客户端…
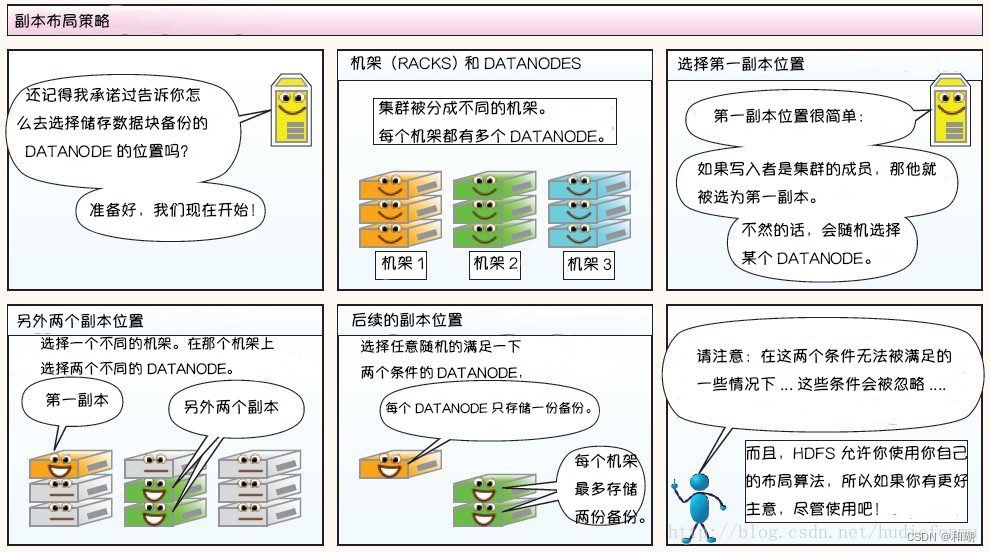
【Hadoop】分布式文件系统 HDFS
目录 一、介绍二、HDFS设计原理2.1 HDFS 架构2.2 数据复制复制的实现原理 三、HDFS的特点四、图解HDFS存储原理1. 写过程2. 读过程3. HDFS故障类型和其检测方法故障类型和其检测方法读写故障的处理DataNode 故障处理副本布局策略 一、介绍
HDFS (Hadoop Distribute…
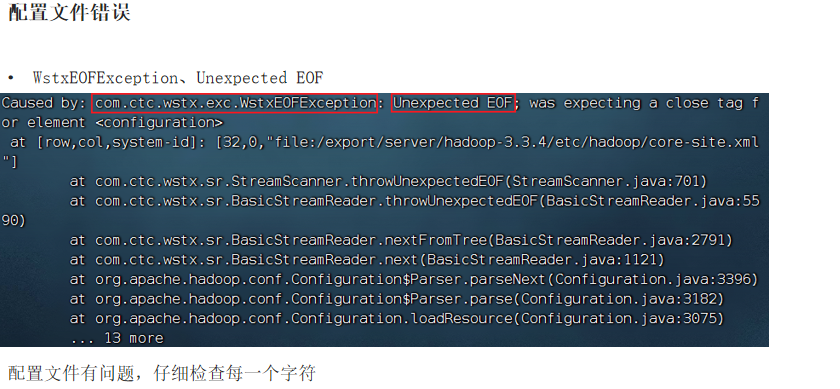
Linux部署HDFS集群
(一)VMware虚拟机中部署
ps、其中node1、node2、node3替换为自己相应节点的IP地址,或者host文件中配置过的主机名,或者看前置准备 或者查看前置准备:Linux部署HDFS集群前置准备
1.下载压缩包
https://www.apache.or…
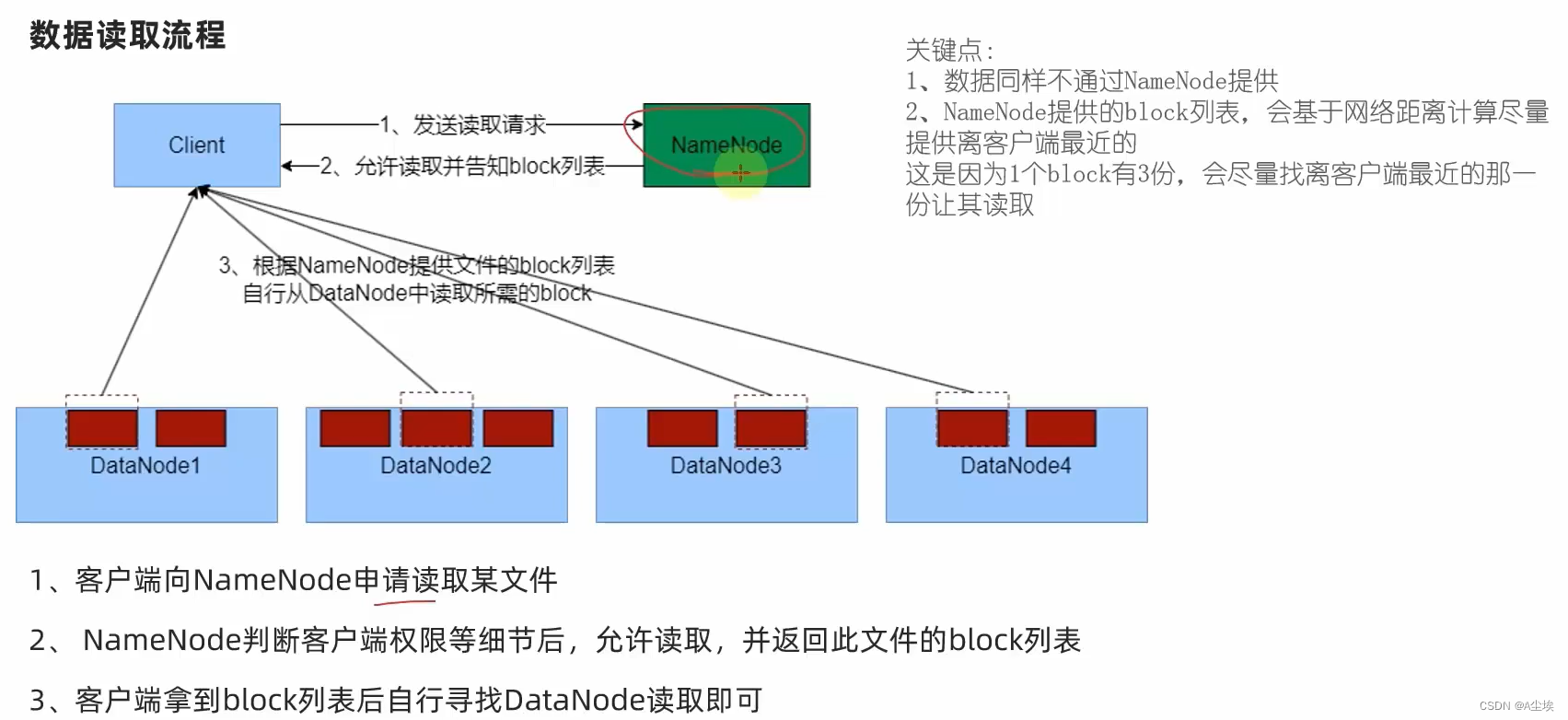
Hadoop——分布式存储HDFS
HDFS集群环境部署
VMware虚拟机中部署
一、https://hadoop.apache.org中下载安装包 二、环境分配 三、上传、解压
确认服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等
四、修改配置文件
hdfs-site.xml ①、dfs.datanode.data.dir.perm 700 h…

Hadoop的HDFS高可用方案
一、Hadoop高可用简介
Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFSNameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂
1、HDFS系统高可用简介…
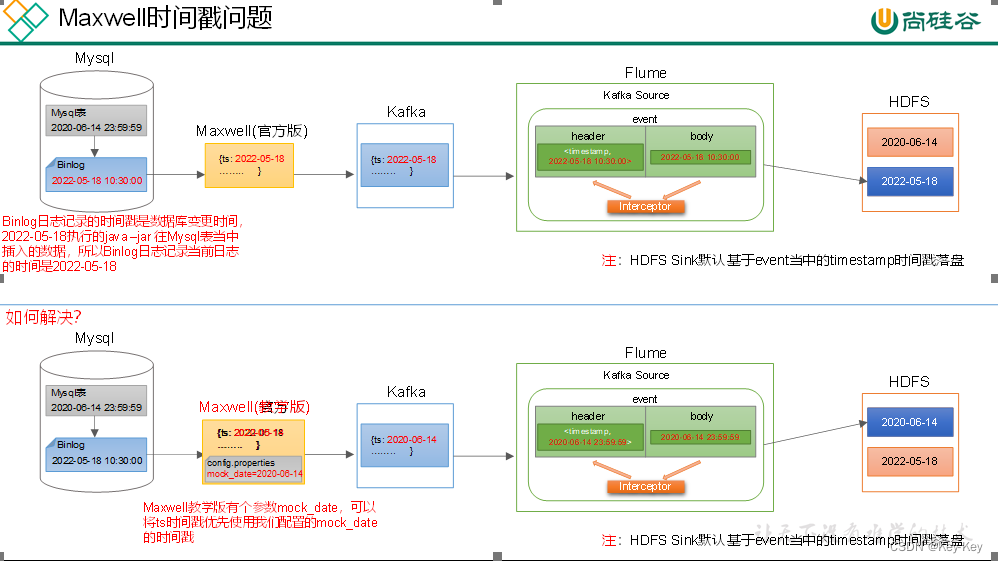
大数据开发之电商数仓(hadoop、flume、hive、hdfs、zookeeper、kafka)
第 1 章:数据仓库
1.1 数据仓库概述
1.1.1 数据仓库概念
1、数据仓库概念: 为企业制定决策,提供数据支持的集合。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本,提高产品质量。 数据…
hadoop hdfs的API调用,在mall商城代码中添加api的调用
在网上下载了现成的商城代码的源码 本次旨在熟悉hdfs的api调用,不关注前后端代码的编写,所以直接下载现成的代码,代码下载地址。我下载的是前后端在一起的代码,这样测试起来方便 GitHub - newbee-ltd/newbee-mall: 🔥 …
Java操作hdfs,总是报ClosedChannelException
现象
public boolean uploadFile(MultipartFile file, String dst) {try {long start System.currentTimeMillis();// 创建Hadoop配置对象Configuration config new Configuration();config.set("fs.defaultFS", hdfsUri);Path dstPath new Path(ROOT_PATH dst)…

深入解析Hadoop生态核心组件:HDFS、MapReduce和YARN
这里写目录标题 01HDFS02Yarn03Hive04HBase1.特点2.存储 05Spark及Spark Streaming关于作者:推荐理由:作者直播推荐: 一篇讲明白 Hadoop 生态的三大部件 进入大数据阶段就意味着进入NoSQL阶段,更多的是面向…

利用Spark将Kafka数据流写入HDFS
利用Spark将Kafka数据流写入HDFS
在当今的大数据时代,实时数据处理和分析变得越来越重要。Apache Kafka作为一个分布式流处理平台,已经成为处理实时数据的事实标准。而Apache Spark则是一个强大的大数据处理框架,它提供了对数据进行复杂处理…
HDFSRPC通信框架参数详解
写在前面
请先阅读HDFSRPC通信框架详解,对整体框架先有一定的了解。
参数列表
参数默认值描述ipc.server.read.connection-queue.size100readeripc.server.read.threadpool.size1readeripc.server.listen.queue.size128Listener:backlogipc.server.tcpnodelaytru…
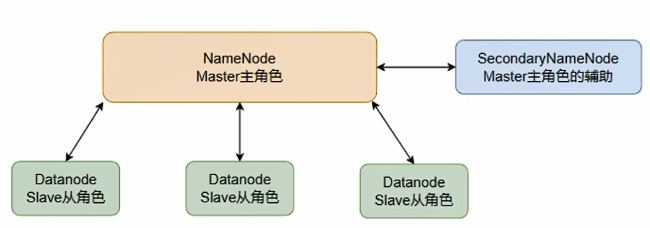
Hadoop HDFS(分布式文件系统)
一、Hadoop HDFS(分布式文件系统) 为什么要分布式存储数据 假设一个文件有100tb,我们就把文件划分为多个部分,放入到多个服务器 靠数量取胜,多台服务器组合,才能Hold住 数据量太大,单机存储能力有上限,需要…

四、hdfs文件系统基础操作-保姆级教程
1、启动Hadoop集群 想要使用hdfs文件系统,就先要启动Hadoop集群。
启动集群:
start-dfs.sh
关闭集群:
stop-dfs.sh 2、文件系统构成
(1)基础介绍
其实hdfs作为分布式存储的文件系统,其构成和Linux文件系统构成差不多一…
Java抽取Hive、HDFS元数据信息
文章目录 一、技术二、构建SpringBoot工程2.1 创建maven工程并配置 pom.xml文件2.2 编写配置文件 application.yml2.3 编写配置文件 application.propertites2.4 开发主启动类2.5 开发配置类 三、测试抽取Hive、HDFS元数据四、将抽取的元数据存储到MySQL4.1 引入依赖4.2 配置ap…
HDFS常用命令总结
目录 1. HDFS简介2. hdfs dfsRef 1. HDFS简介
HDFS(Hadoop Distributed File System)是一种Hadoop分布式文件系统,具备高度容错特性,支持高吞吐量数据访问,可以在处理海量数据(TB或PB级别以上)…
Hadoop之HDFS——【模块一】元数据架构
一、元数据是什么
在HDFS中,元数据主要指的是文件相关的元数据,通过两种形式来进行管理维护,第一种是内存,维护集群数据的最新信息,第二种是磁盘,对内存中的信息进行维护与持久化,由namenode管理维护。从广义的角度来说,因为namenode还需要管理众多的DataNode结点,因…

Running job: job_1709516801756_0003
**
yarn运行卡在Running job: job_1709516801756_0003问题解决:
** 在运行wordcount时出现错误,一直卡住 运行命令:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output 出现错误:…

Datax安装部署及读取MYSQL写入HDFS
一.DataX简介
1.DataX概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。 源码地址:https://github.com/alibaba/Data…
【大数据】区分 hdfs dfs -ls 与 hdfs dfs -ls /
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…

Windows下IntelliJ IDEA远程连接服务器中Hadoop运行WordCount(详细版)
使用IDEA直接运行Hadoop项目,有两种方式,分别是本地式:本地安装HadoopIDEA;远程式:远程部署Hadoop,本地安装IDEA并连接, 本文介绍第二种。
一、安装配置Hadoop
(1)虚拟机伪分布式
见上才艺&a…
HDFS(Hadoop分布式文件系统)具有高吞吐量特点的原因
数据分块和分布式存储:HDFS将大文件分割成多个数据块,并通过数据块的复制和分布式存储在集群中的多台机器上存储这些数据块。这样,可以利用多台机器的并行处理能力,并同时读取或写入多个数据块,从而提高整体的吞吐量。…

HDFS的架构优势与基本操作
目录 写在前面一、 HDFS概述1.1 HDFS简介1.2 HDFS优缺点1.2.1 优点1.2.2 缺点 1.3 HDFS组成架构1.4 HDFS文件块大小 二、HDFS的Shell操作(开发重点)2.1 基本语法2.2 命令大全2.3 常用命令实操2.3.1 上传2.3.2 下载2.3.3 HDFS直接操作 三、HDFS的API操作3…

开源分布式存储系统(HDFS、Ceph)架构分析
文章目录 中间控制节点架构-HDFSNameNode节点分析DataNode节点分析SecondNameNode节点分析Client分析 完全无中心架构-CephCeph Monitor分析Ceph OSD分析Ceph Manager分析Ceph Clients分析 小结HDFS优点缺点 Ceph优点缺点 参考 中间控制节点架构-HDFS
以HDFS( Hado…

Hadoop大数据应用:HDFS 集群节点扩容
目录 一、实验
1.环境
2.HDFS 集群节点扩容
二、问题
1.rsync 同步报错 一、实验
1.环境
(1)主机
表1 主机
主机架构软件版本IP备注hadoop NameNode (已部署) SecondaryNameNode (已部署) Resourc…
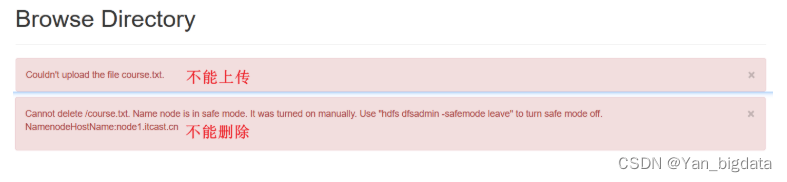
Hadoop架构---HDFS补充知识点---三个模式/机制
1.安全模式
在安全模式下 不允许HDFS客户端进行任何修改文件的操作,包括上传文件,删除文件等操作。
#查看安全模式状态:
[rootnode1 /]# hdfs dfsadmin -safemode get
Safe mode is OFF
#开启安全模式:
[rootnode1 /]# hdfs dfsadmin -safemode enter
Safe mod…

十二、MapReduce概述
1、MapReduce
(1)采用框架
MapReduce是“分散——>汇总”模式的分布式计算框架,可供开发人员进行相应计算
(2)编程接口:
~Map
~Reduce
其中,Map功能接口提供了“分散”的功能ÿ…
Hadoop集群环境下HDFS实践编程过滤出所有后缀名不为“.abc”的文件时运行报错:java.net.ConnectException: 拒绝连接;
一、问题描述
搭建完Hadoop集群后,在Hadoop集群环境下运行HDFS实践编程使用Eclipse开发调试HDFS Java程序(文末有源码):
假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.tx…
【flink】flink on yarn jar异常,类冲突:原因本地上传jar和hdfs的jar冲突
flink jar异常,类冲突可能原因:
报错如下
java.sql.SQLException: ERROR 2006 (INT08): Incompatible jars detected between client and server. Ensure that phoenix-[version]-server.jar is put on the classpath of HBase in every region server…
第1章 Iceberg简介
1.1 概述 Iceberg是一个面向大型分析数据集的开放表格格式。它为多种计算引擎,如Spark、Trino、PrestoDB、Flink、Hive和Impala,增加了表格功能,使用一种高性能的表格格式,其工作方式就像一个SQL表一样。
在生产环境中࿰…
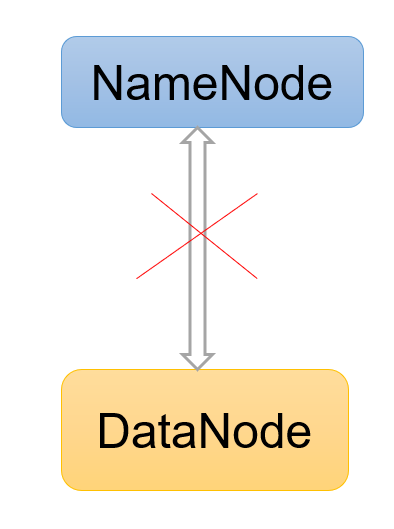
Hadoop3教程(六):HDFS中的DataNode
文章目录 (63)DataNode工作机制(64)数据完整性(65)掉线时限参数设置参考文献 (63)DataNode工作机制
DataNode内部存储了一个又一个Block,每个block由数据和数据元数据组…
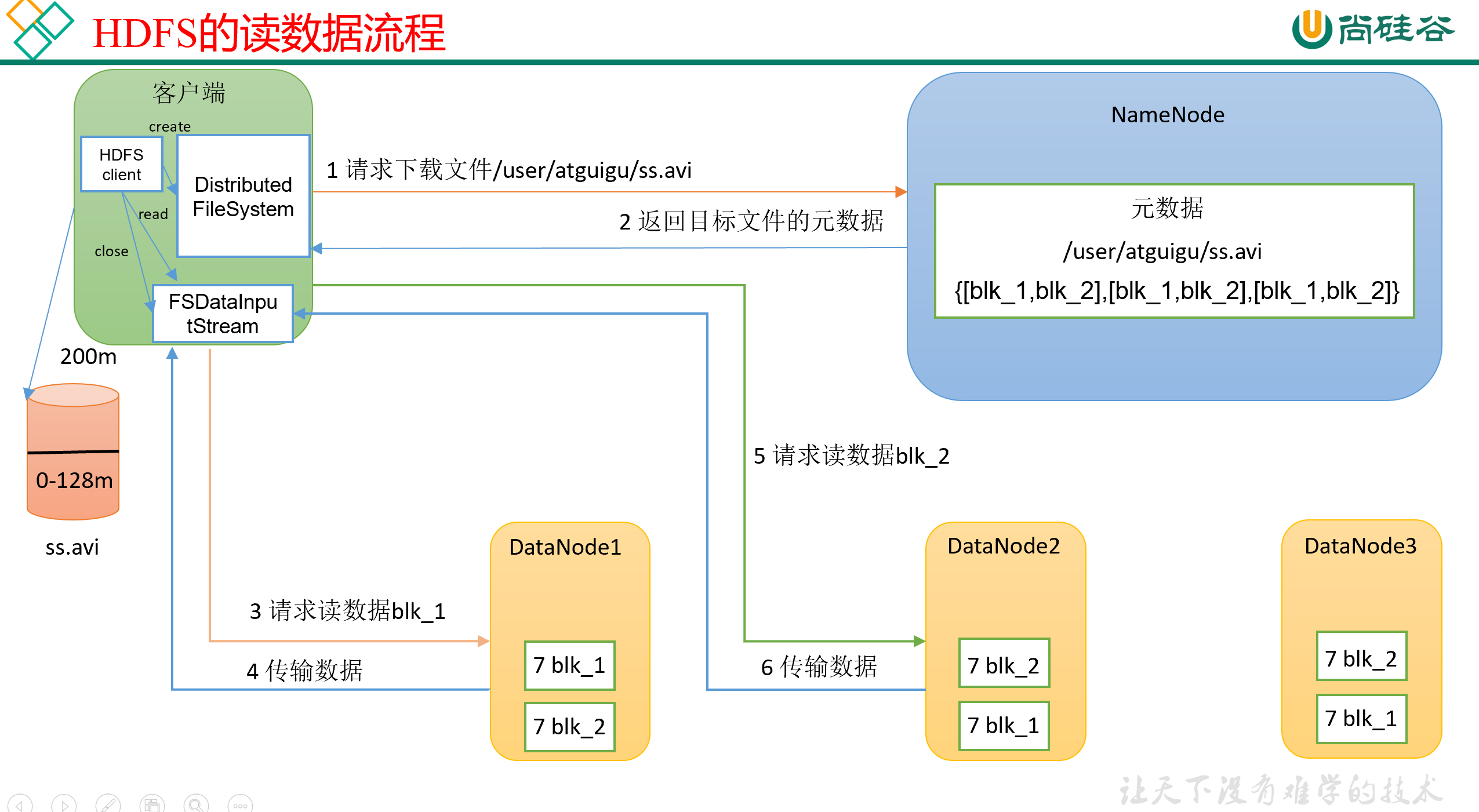
Hadoop3教程(四):HDFS的读写流程及节点距离计算
文章目录 (55)HDFS 写数据流程(56) 节点距离计算(57)机架感知(副本存储节点选择)(58)HDFS 读数据流程参考文献 (55)HDFS 写数据流程
…
【HDFS】DatanodeAdminBackoffMonitor退役节点极慢的问题定位
一、现象:
下节点特别慢。10台节点,每台大约需要退役60w个块。但是3个小时才退役了3000多个块。
NN侧如下日志,可以看到30秒只退役了512-494 = 20个块,这要是退役600w个块,得猴年马月?
2024-03-19 14:44:42,952 INFO org.apache.hadoop.hdfs.server.blockmanagement.D…
深入理解 Hadoop (三)HDFS文件系统设计实现
HDFS FileSystem NameNode 端抽象实现
HDFS 磁盘元数据文件解读 共有五种格式的文件: edits_0000000000000041912-0000000000000041913:该 LogSegment 记录了 transaction id 在 41912-41913 之间的事务日志。(最多保留 50 个) edits_inprogress_000000…
hdfs dfsadmin -safemode无法退出安全模式
退出安全模式 第一种:正常退出安全模式
hdfs dfsadmin -safemode leave如提示Safe mode is OFF,那就说明退出成功,但有时候这个命令也没办法退出安全模式,就需要使用强制退出 第二种:强制退出安全模式 hdfs dfsadmin …
大数据主要组件HDFS Iceberg Hadoop spark介绍
HDFSIceberghadoopspark HDFS
面向PB级数据存储的分布式文件系统,可以存储任意类型与格式的数据文件,包括结构化的数据以及非结构化的数据。HDFS将导入的大数据文件切割成小数据块,均匀分布到服务器集群中的各个节点,并且每个数据…

HDFS概述及常用shell操作
HDFS 一、HDFS概述1.1 HDFS适用场景1.2 HDFS优缺点1.3 HDFS文件块大小 二、HDFS的shell操作2.1 上传2.2 下载2.3 HDFS直接操作 一、HDFS概述
1.1 HDFS适用场景
因为HDFS里所有的文件都是维护在磁盘里的 在磁盘中对文件的历史内容进行修改 效率极其低(但是追加可以)
1.2 HDF…
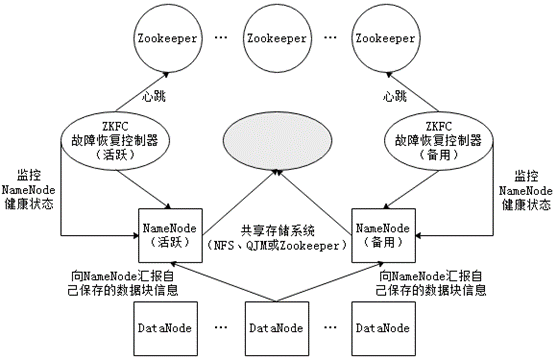
【Hadoop大数据技术】——Hadoop高可用集群(学习笔记)
📖 前言:Hadoop设计之初,在架构设计和应用性能方面存在很多不如人意的地方,如HDFS和YARN集群的主节点只能有一个,如果主节点宕机无法使用,那么将导致HDFS或YARN集群无法使用,针对上述问题&#…

基于华为MRS3.2.0实时Flink消费Kafka落盘至HDFS的Hive外部表的调度方案
文章目录 1 Kafka1.1 Kerberos安全模式的认证与环境准备1.2 创建一个测试主题1.3 消费主题的接收测试 2 Flink1.1 Kerberos安全模式的认证与环境准备1.2 Flink任务的开发 3 HDFS与Hive3.1 Shell脚本的编写思路3.2 脚本测试方法 4 DolphinScheduler 该需求为实时接收对手Topic&a…

大数据 - Hadoop系列《五》- HDFS文件块大小及小文件问题
系列文章:
大数据- Hadoop入门-CSDN博客
大数据 - Hadoop系列《二》- Hadoop组成-CSDN博客
大数据 - Hadoop系列《三》- HDFS(分布式文件系统)概述_大量小文件的存储使用什么分布式文件系统-CSDN博客
大数据 - Hadoop系列《三》- MapRedu…
【大数据】四、HDFS 基础操作
IDE 连接
在本地电脑上解压 hadoop.tar.gz,配置环境变量
之后 去github 上 把 winutil.exe 和 hadoop.dll 下载到 hadoop 的bin 文件夹下
再修改 etc/hadoop-env.cmd 中的 JDK 路径
我们使用 IDEA 打开一个 JAVA Maven项目,进行测试
注意࿰…


HDFS block 块大小设置
寻址时间:HDFS中找到目标文件块(block)所需要的时间。
原理:
文件块越大,寻址时间越短,但磁盘传输时间越长;
文件块越小,寻址时间越长,但磁盘传输时间越短。
一 为什…

Hadoop:HDFS学习巩固——基础习题及编程实战
一 HDFS 选择题
1.对HDFS通信协议的理解错误的是?
A.客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的
B.HDFS通信协议都是构建在IoT协议基础之上的
C.名称节点和数据节点之间则使用数据节点协议进行交互
D.客户端通过一…
获取Flink作业在HDFS上保存的最新的savepoint文件路径
获取Flink作业在HDFS上保存的最新的savepoint文件路径
代码:
savepoint$(hadoop fs -ls hdfs://xxxApp/flink-checkpoints/xxxflinkjob/*/chk-*/_metadata |grep -vw Found |sort -k6,7 -r |head -n 1 |awk {print $8})上面的代码是一个Shell命令,用于…
HADOOP HDFS详解
目录 第一章 概述
1.1大数据的特征(4V)
1.2 大数据的应用场景
1.3大数据的发展前景
1.4企业大数据的一般处理流程
1.4.1数据源
1.4.2数据采集或者同步
1.4.3数据存储
1.4.4 数据清洗
1.4.5 数据分析
1.4.6数据展示
第二章 hadoop介绍
2.1.hadoop 目标
2.2 hadoop的…

HDFS面试指南:掌握关键问题
在大数据领域,Hadoop分布式文件系统(HDFS)是一个重要的组成部分,它能够有效地处理和存储大规模数据。
在面试中,对HDFS的理解和知识是非常重要的。本文旨在从HDFS的诞生角度出发,理清都可能出现哪些方面的…

把本地文件上传到HDFS上操作步骤
因为条件有限,我这里以虚拟机centos为例 实验条件:我在虚拟机上创建了三台节点,部署了hadoop,把笔记本上的数据上传到hdfs中 数据打包上传到虚拟机节点上 采用的是rz命令,可以帮我们上传数据 没有的话可以使用命令安装…

大数据开发-Hadoop之HDFS高级应用
文章目录 HDFS回收站HDFS的安全模式定时上传数据至HDFSHDFS的高可用和高扩展HDFS写数据过程源码剖析 HDFS回收站
HDFS会为每个用户创建一个回收站目录:/user/用户名/.Trash/回收站中的数据都会有一个默认的保存周期,过期未恢复则会被HDFS自动彻底删除默认情况下HDF…

HDFS的Shell操作及客户端配置方法
HDFS进程启停命令
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群 执行原理:
在执行此脚本的机器上,启动(关闭&…
使用Hive对HDFS中数据查询的优点
目录 摘要一、Hive是什么二、HDFS是什么三、Hive与HDFS的关系四、什么是HiveQL五、什么是mapreduce六、Hive如何将查询转为mapreduce任务七、Hadoop生态系统中的高性能引擎八、使用Hadoop的优点 摘要
Hadoop生态系统中包含了多个关键组件,如Hive、HDFS、MapReduce等…

Hadoop大数据应用:HDFS 集群节点缩容
目录
一、实验
1.环境
2.HDFS 集群节点缩容
二、问题
1.数据迁移有哪些状态
2.数据迁移失败 一、实验
1.环境
(1)主机
表1 主机
主机架构软件版本IP备注hadoop NameNode (已部署) SecondaryNameNode (已部署…
总结:HDFS+YARN+HIVE
总结:HDFSYARNHIVE 第一章 Hello大数据&分布式Part1 数据导论一. 数据二. 数据的价值 Part2 大数据诞生Part3 大数据概述一. 什么是大数据二.大数据特征三.大数据的核心工作 Part4 大数据软件生态一. 大数据软件生态 Part5 Apache Hadoop 概述一. Hadoop概念 第二章 分布式…
HDFSRPC通信框架详解
本文主要对HDFSRPC通信框架解析。包括listener,reader,handler,responser等实现类的源码分析。注意hadoop版本为3.1.1。
写在前面
rpc肯定依赖于socket通信,并且使用的是java NIO。读者最好对nio有一定的了解,文章中…
【软件工程】软件工程定义、软件危机以及软件生命周期
🌸博主主页:釉色清风🌸文章专栏:软件工程🌸 今日语录:What matters isn’t how others think of your ambitions but how fervently you cling to them. 软件工程系列,主要根据老师上课所讲提及…
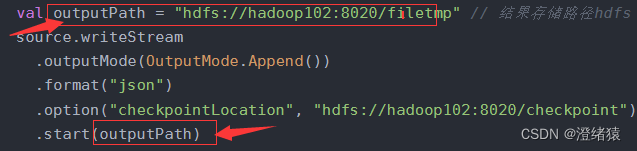
py脚本模拟json数据,StructuredStreaming接收数据存储HDFS一些小细节 ERROR:‘path‘ is not specified
很多初次接触到StructuredStreaming 应该会写一个这样的案例
- py脚本不断产生数据写入linux本地, 通过hdfs dfs 建目录文件来实时存储到HDFS中
1. 指定数据schema: 实时json数据
2. 数据源地址:HDFS
3. 结果落地位置: HDFS
…
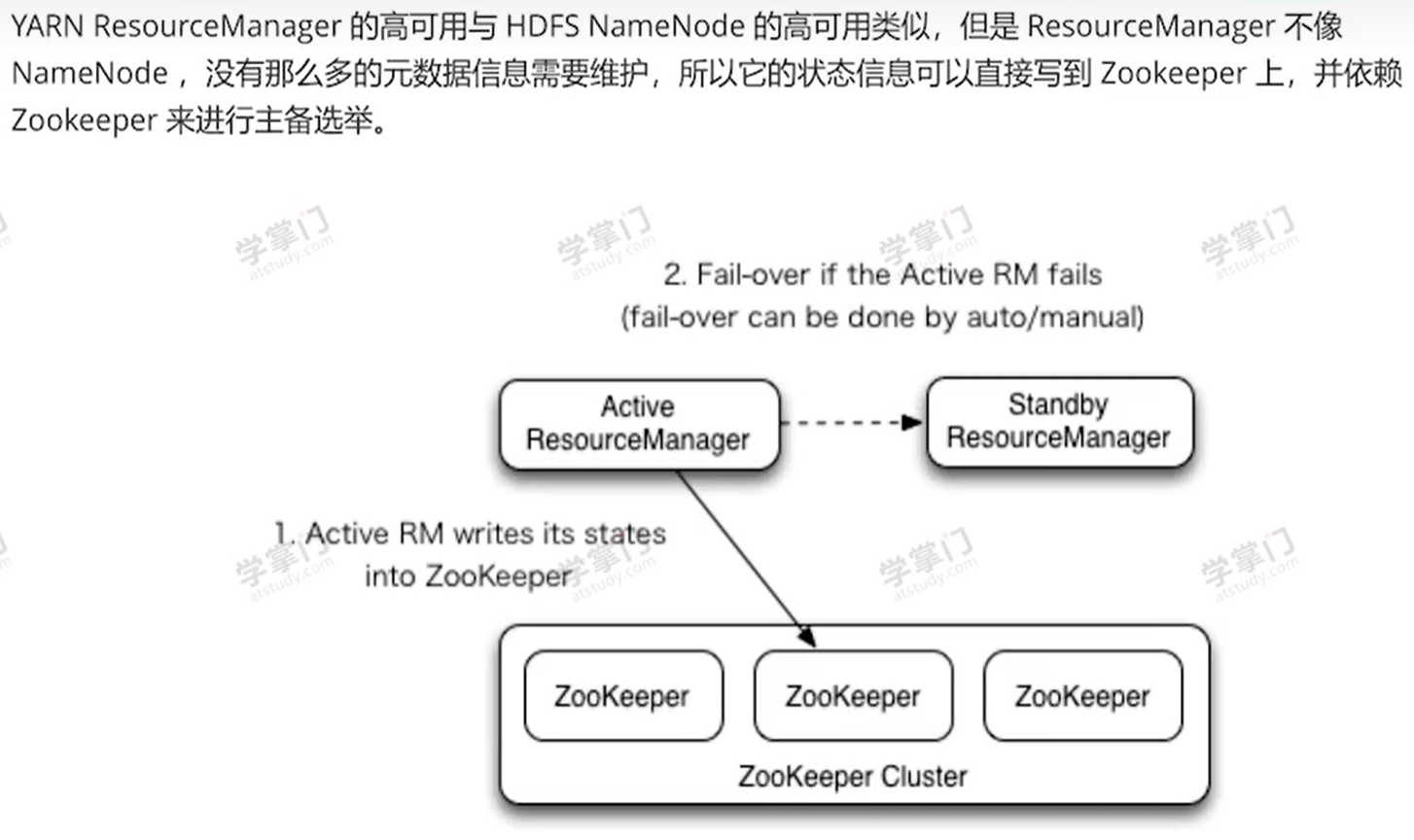
hadoop 高可用(HA)、HDFS HA、Yarn HA
目录 hadoop 高可用(HA) HDFS高可用 HDFS高可用架构 QJM 主备切换: Yarn高可用 hadoop 高可用(HA) HDFS高可用 HDFS高可用架构 QJM 主备切换: Yarn高可用
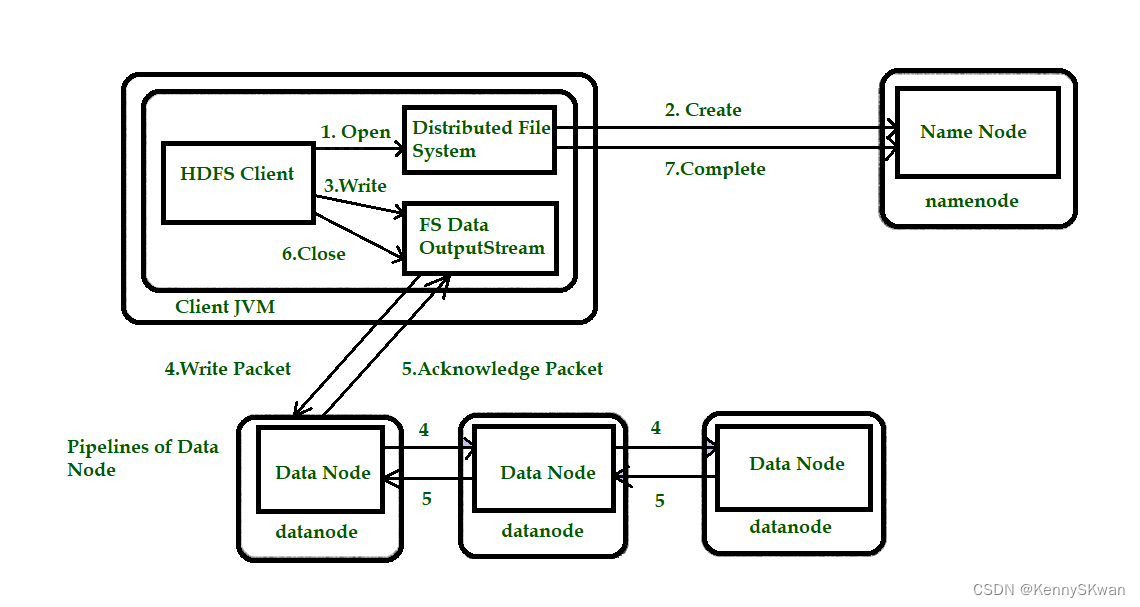
深入理解HDFS工作原理:大数据存储和容错性机制解析
**
引言:
**
在当今数据爆炸的时代,存储和管理大规模数据成为了许多组织面临的重要挑战。为了解决这一挑战,分布式文件系统应运而生。Hadoop分布式文件系统(HDFS)作为Apache Hadoop生态系统的核心组件之一ÿ…